When accurate prediction models yield harmful self-fulfilling prophecies
Premedical Team, Inria, Montpellier, France
2026-04-21
Prediction model performance versus healthcare impact
- many prediction models: given feature \(X\), estimate probability outcome \(Y\)
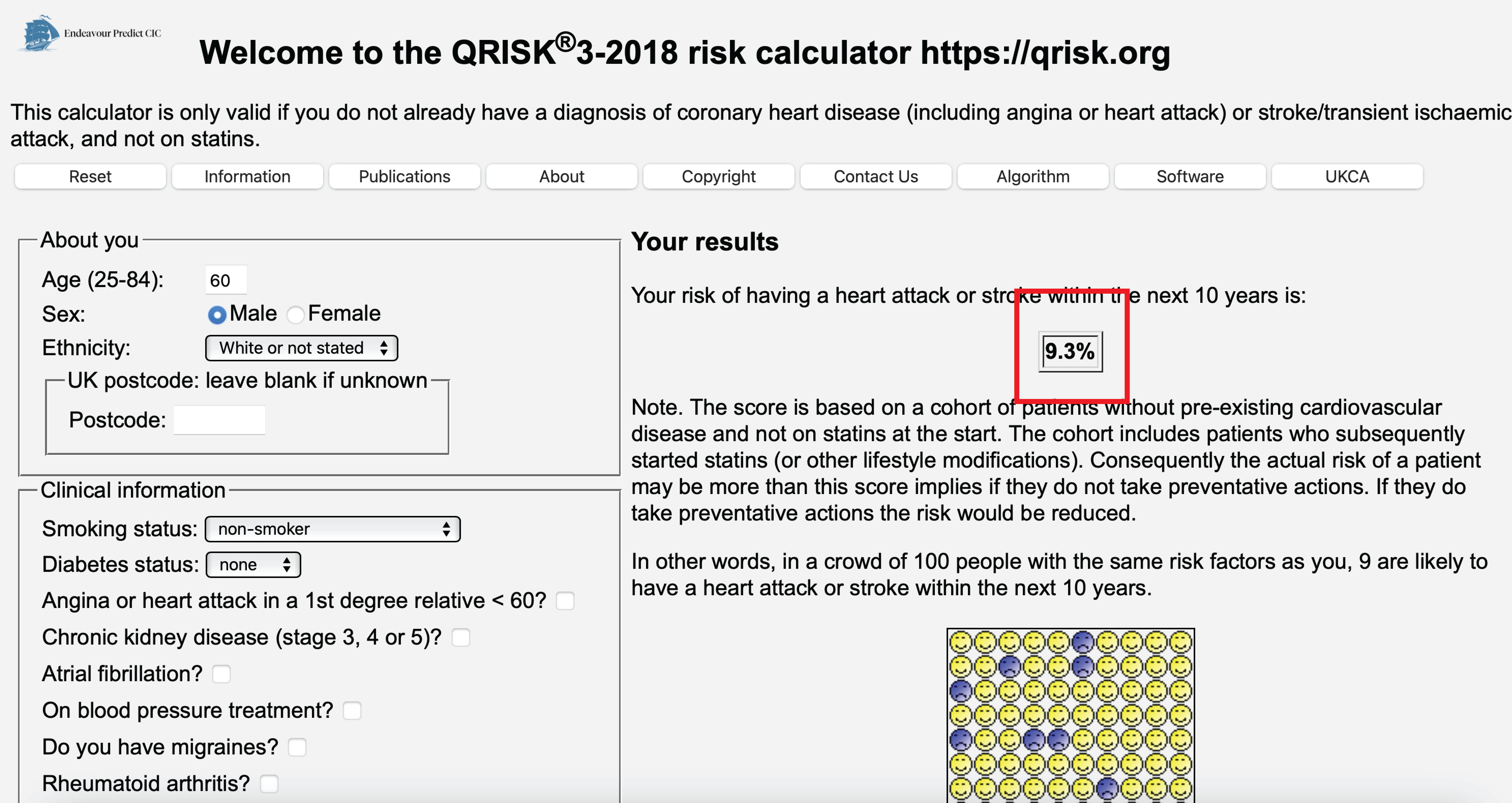
- e.g. given age, cholesterol and sex, predict 10-year risk of a heart attack
![]()
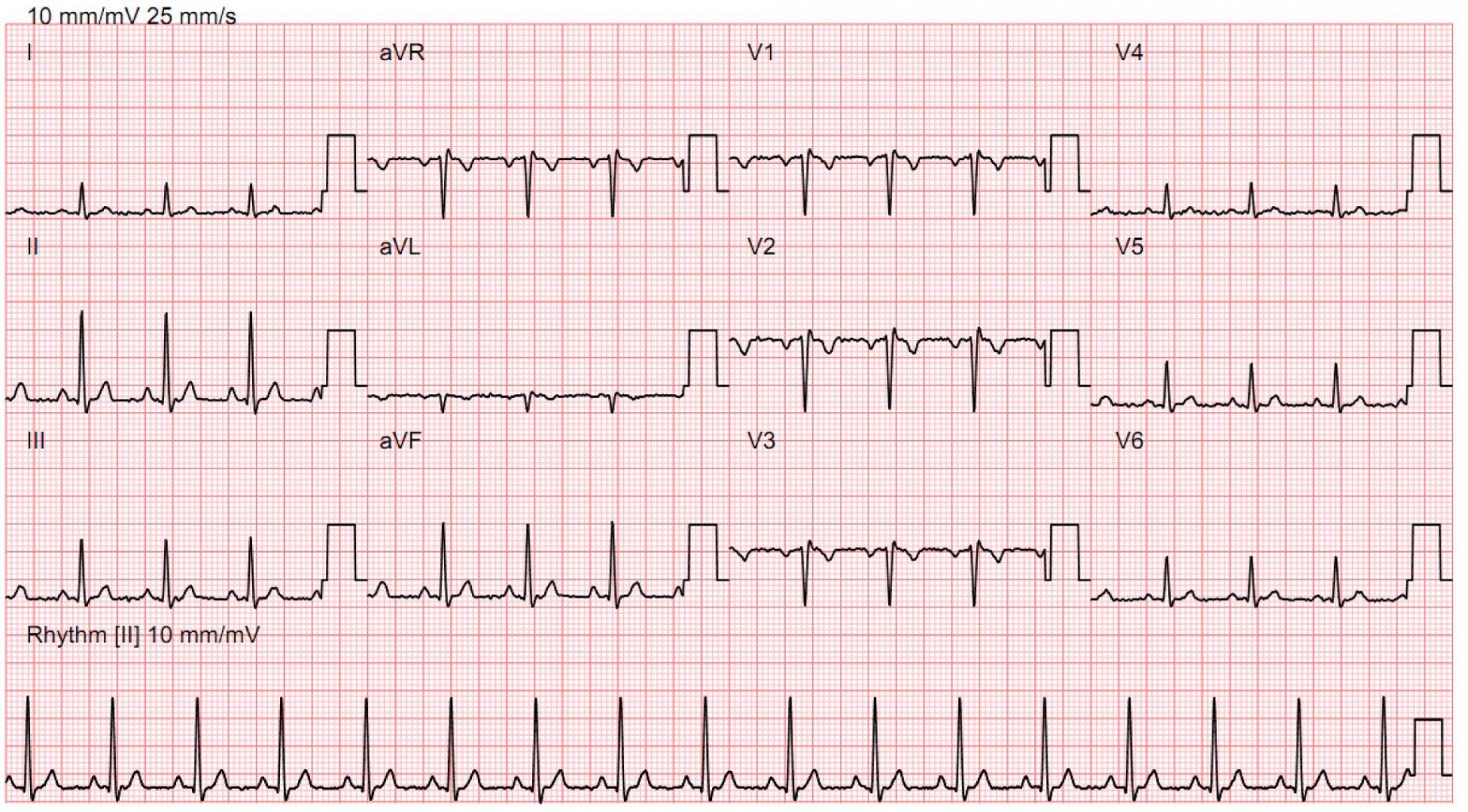
- given ECG, predict presence of heart failure
![]()
- e.g. given age, cholesterol and sex, predict 10-year risk of a heart attack
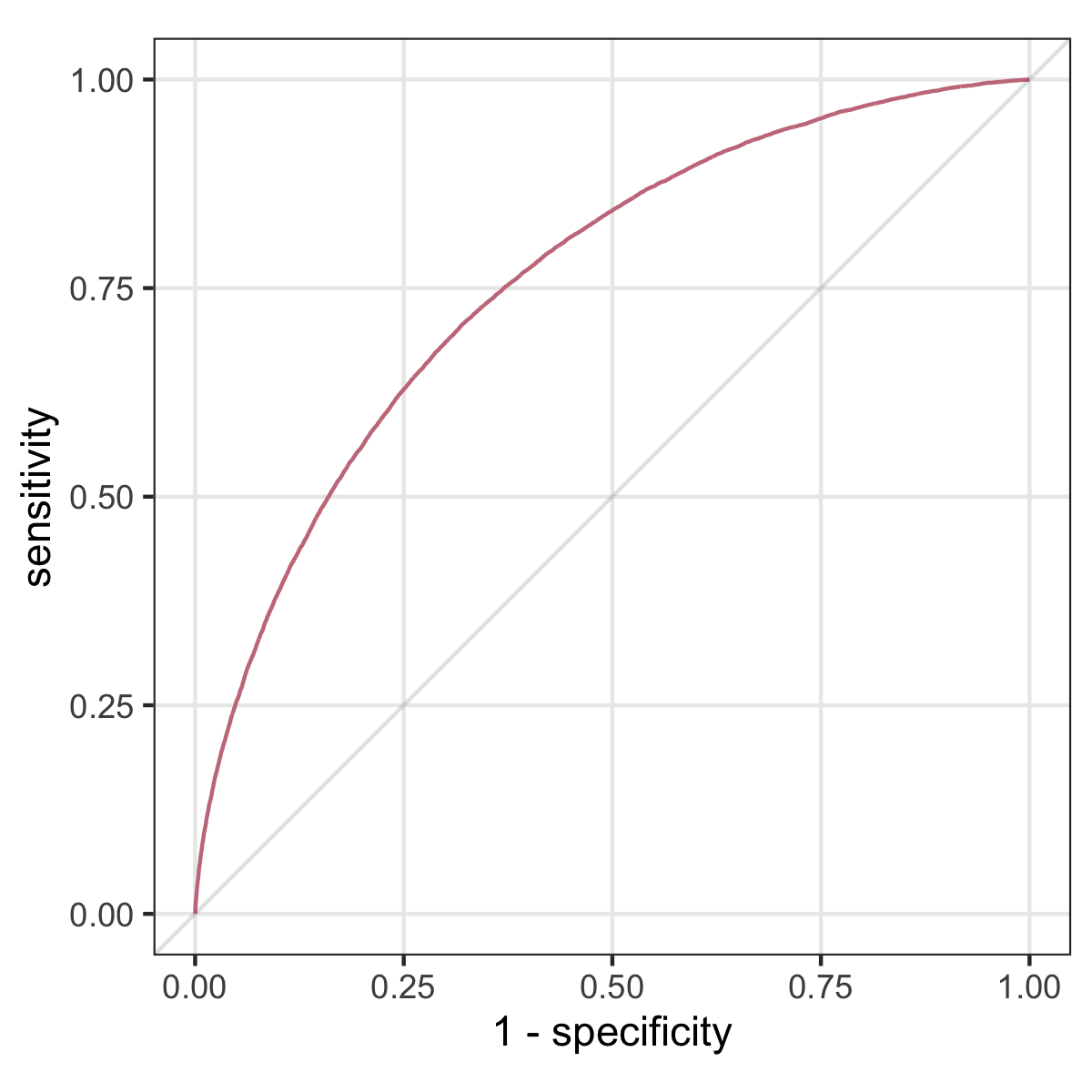
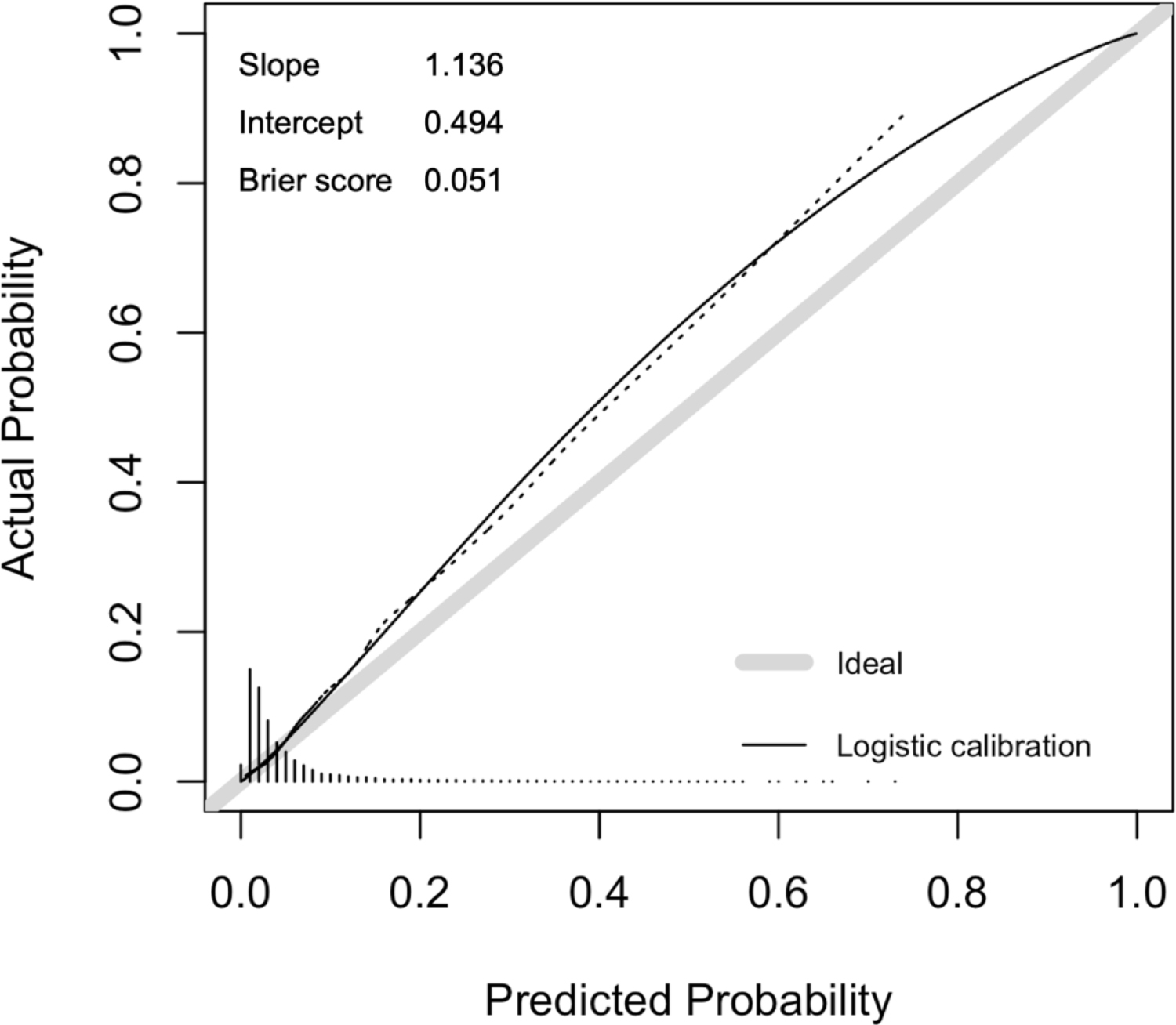
- evaluated on predictive performance: discrimination (AUC) and calibration


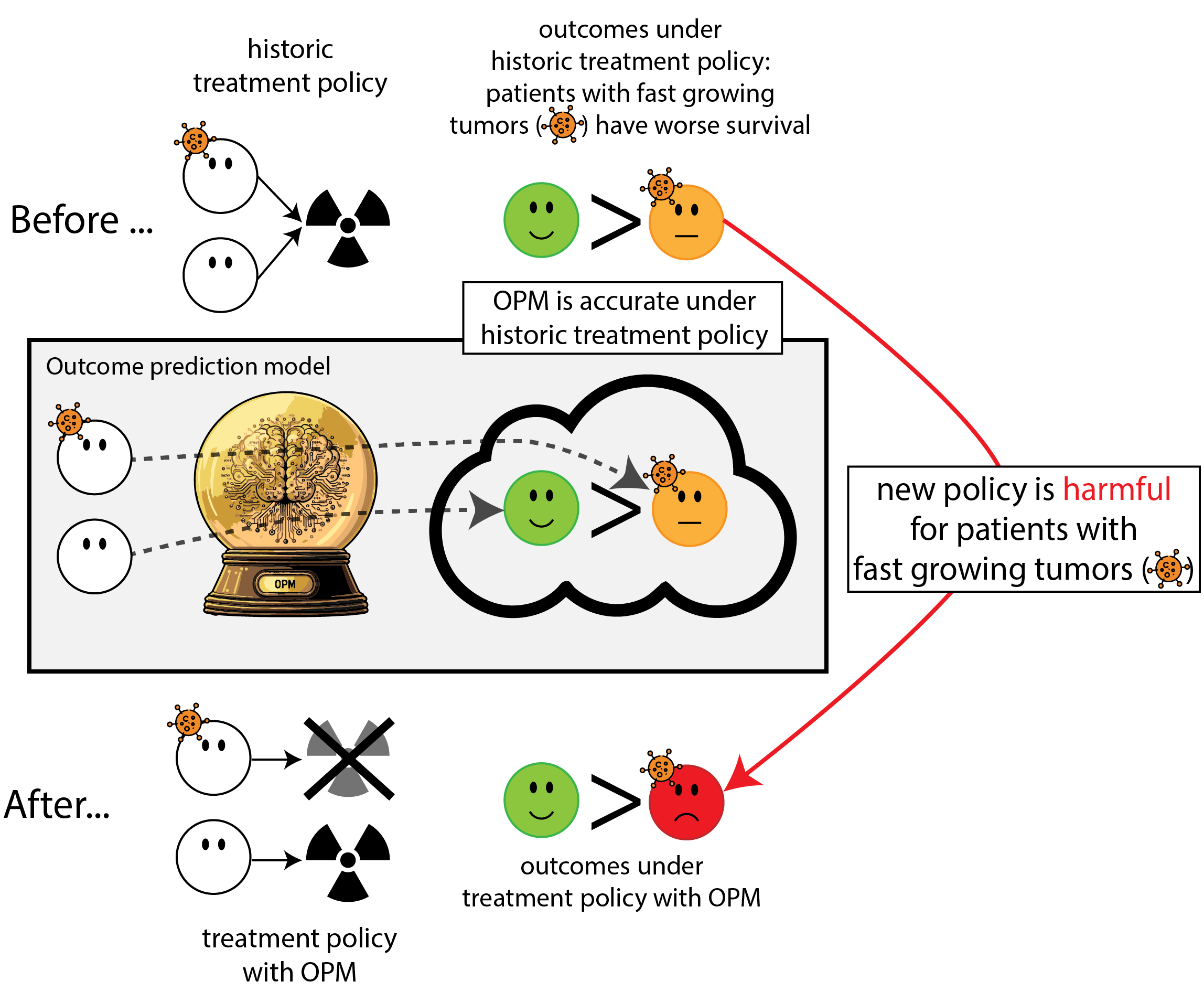
Regulation to the rescue: we need to monitor (AI) models


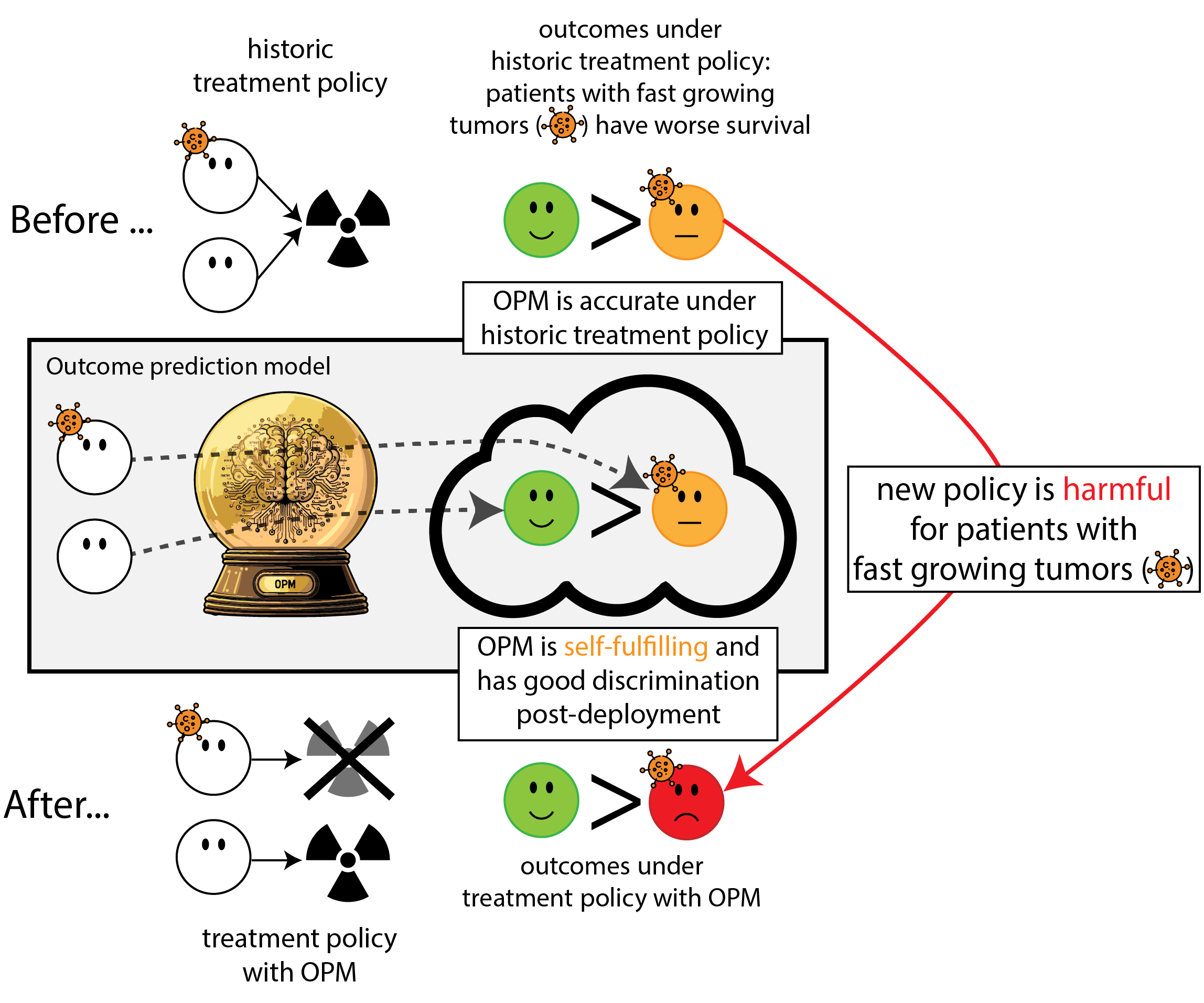
Our paper
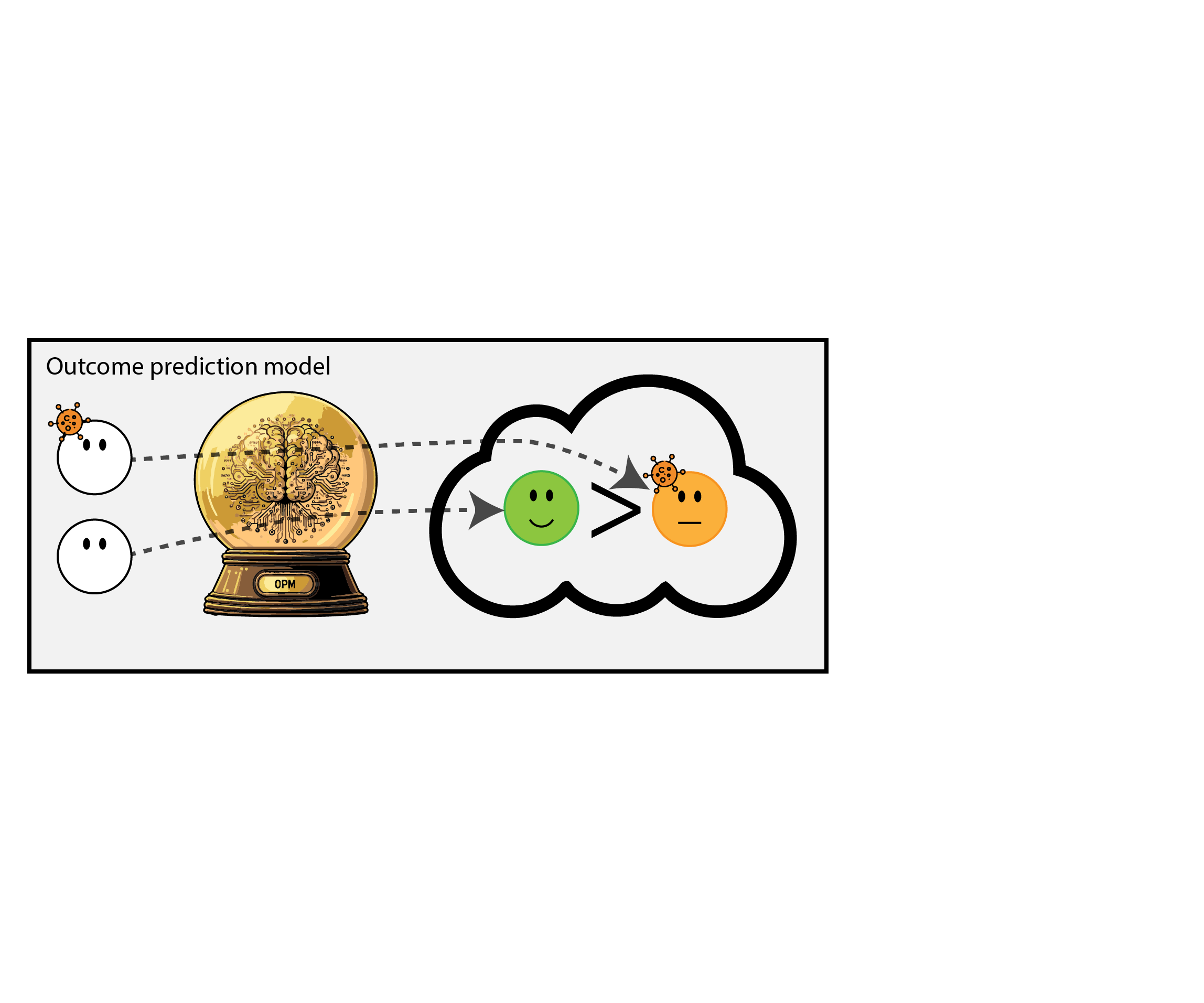
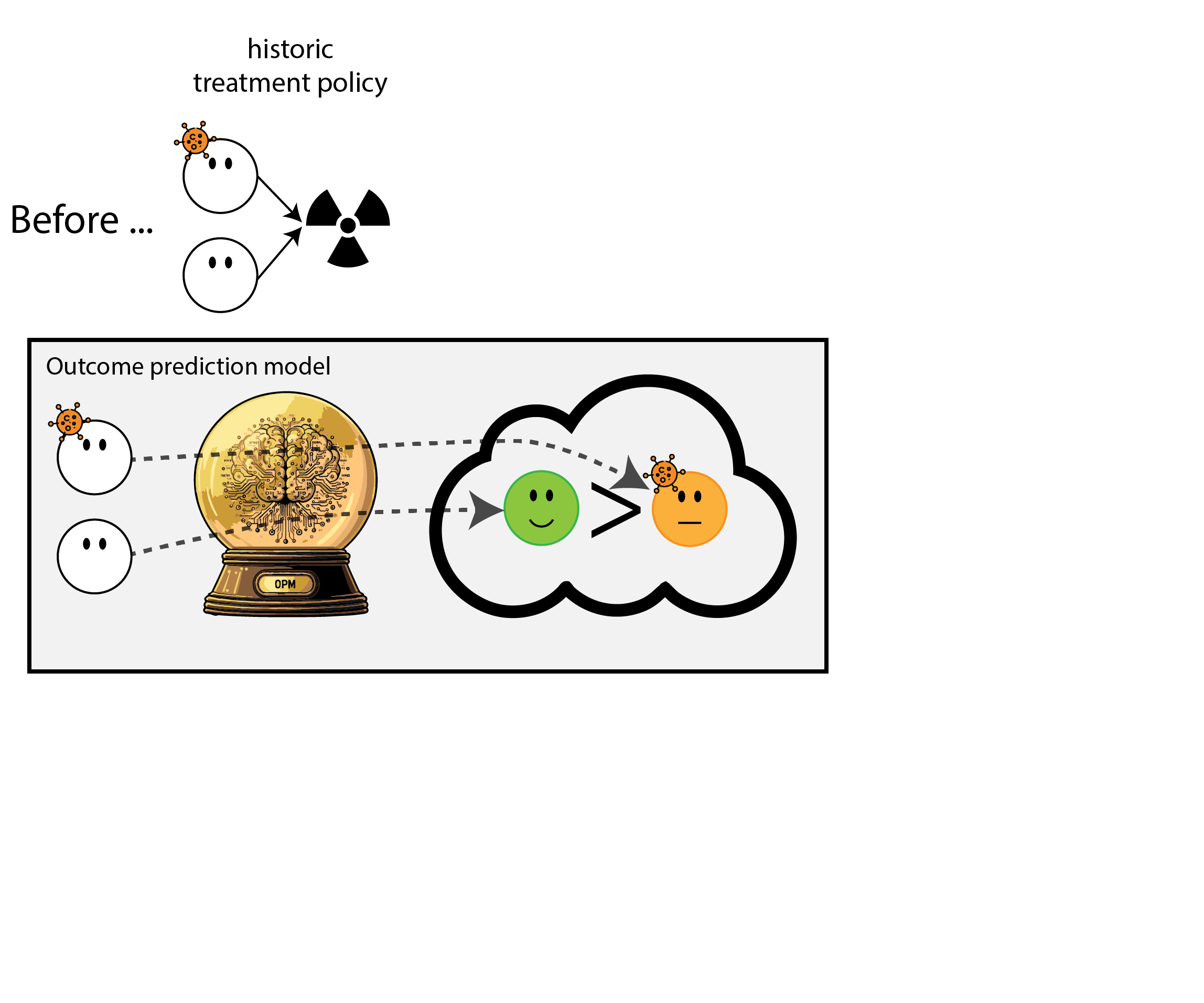
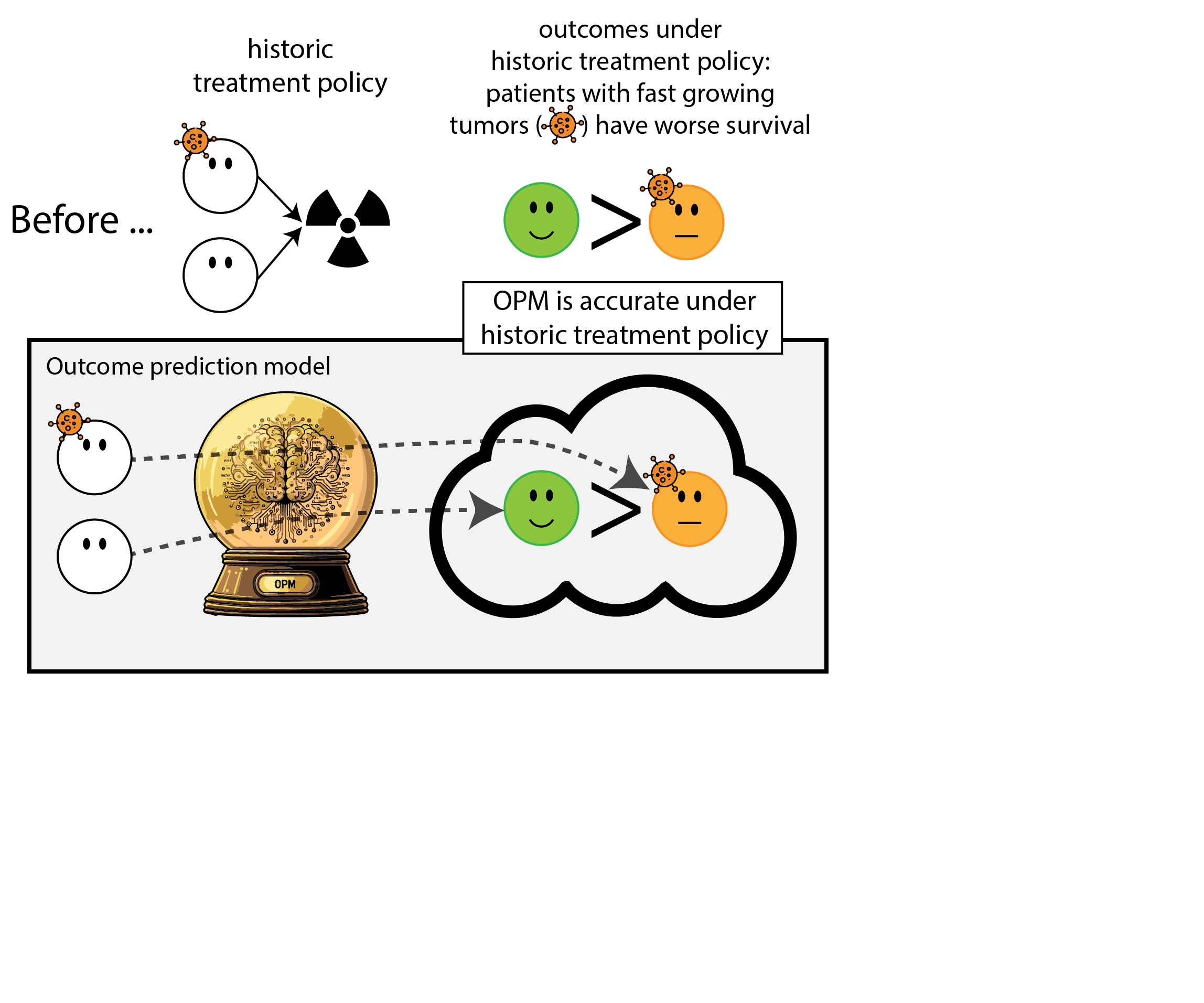
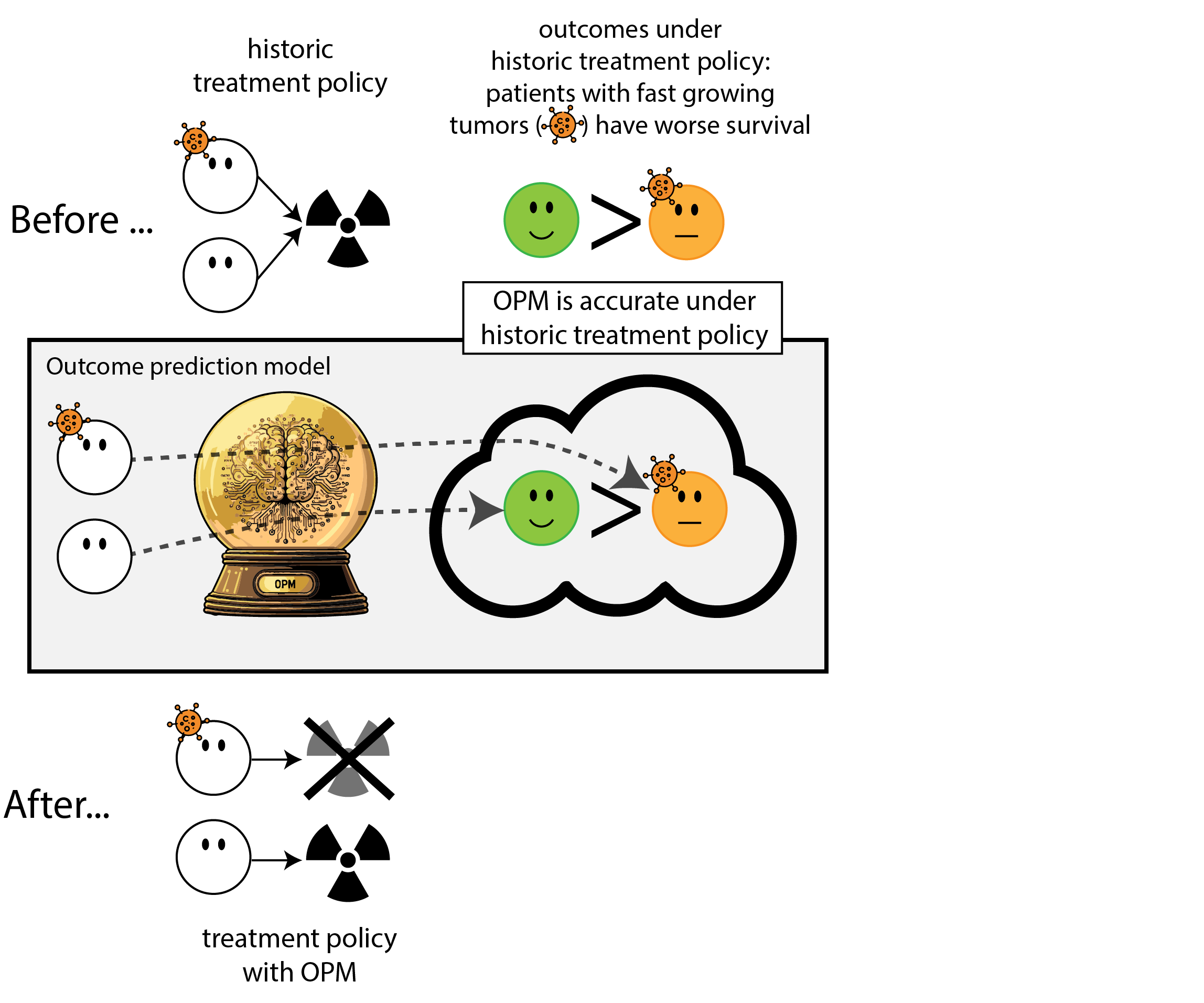
We formalize the simplest general case of introducing an ‘outcome prediction model’ for decision support
- before: everyone treated (\(T=1\))(or untreated (\(T=0\)))
- new binary feature \(X\)
- outcome prediction model: \(\mu(x) = P(Y=1|X=x)\)
- new policy based on OPM: treat when \(\mu(x) > \lambda\) (assume non-constant policy)
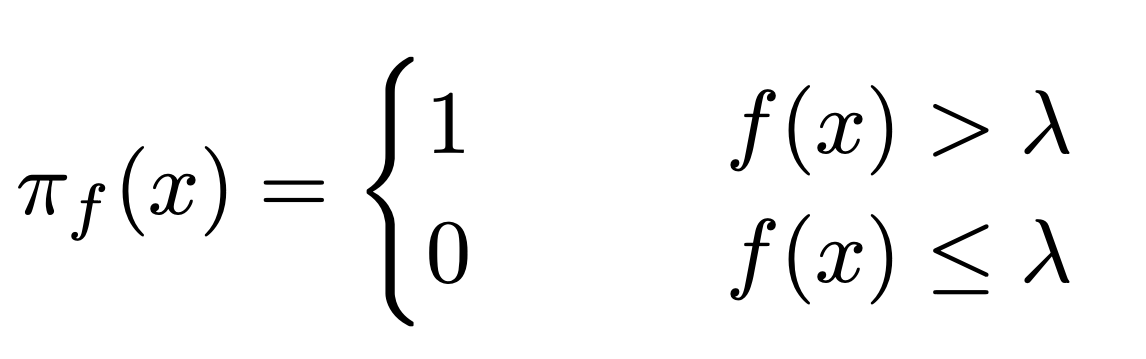
Harmful self-fulfilling prophecies occur in cases without extreme treatment (interaction) effects
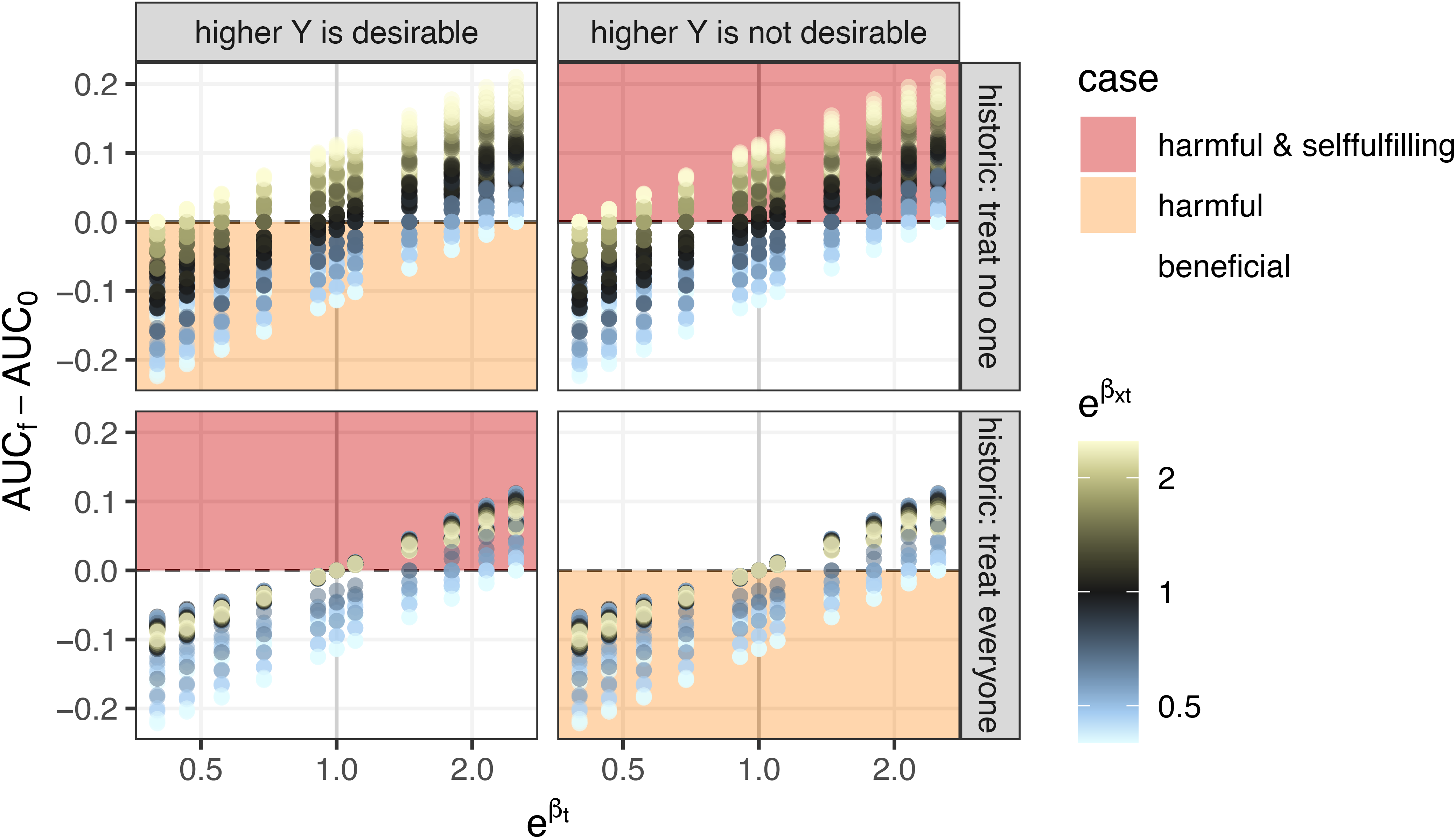
Also when removing settings where the average treatment effect is harmful
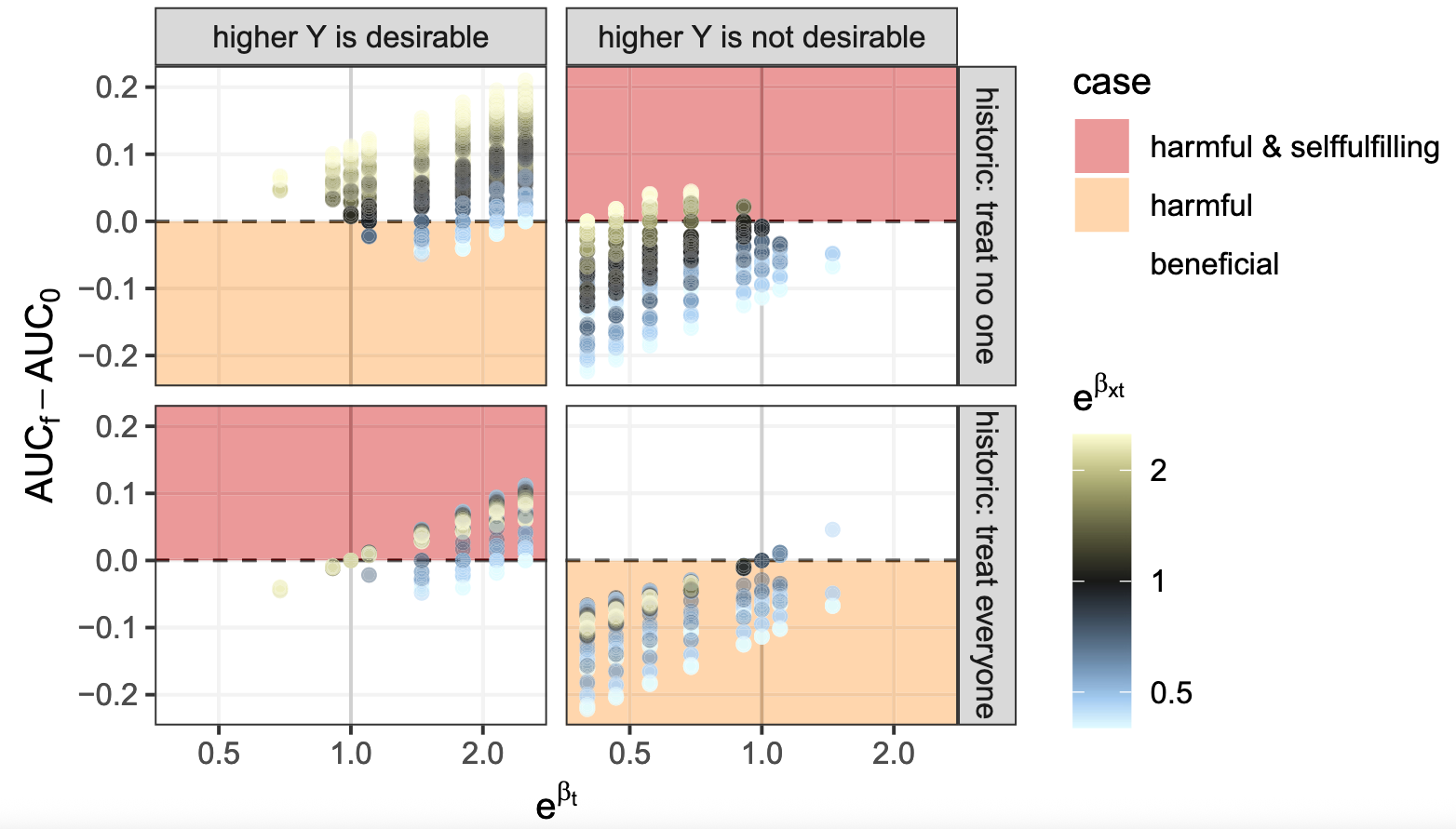
Deterministic evaluation of usefulness of policy
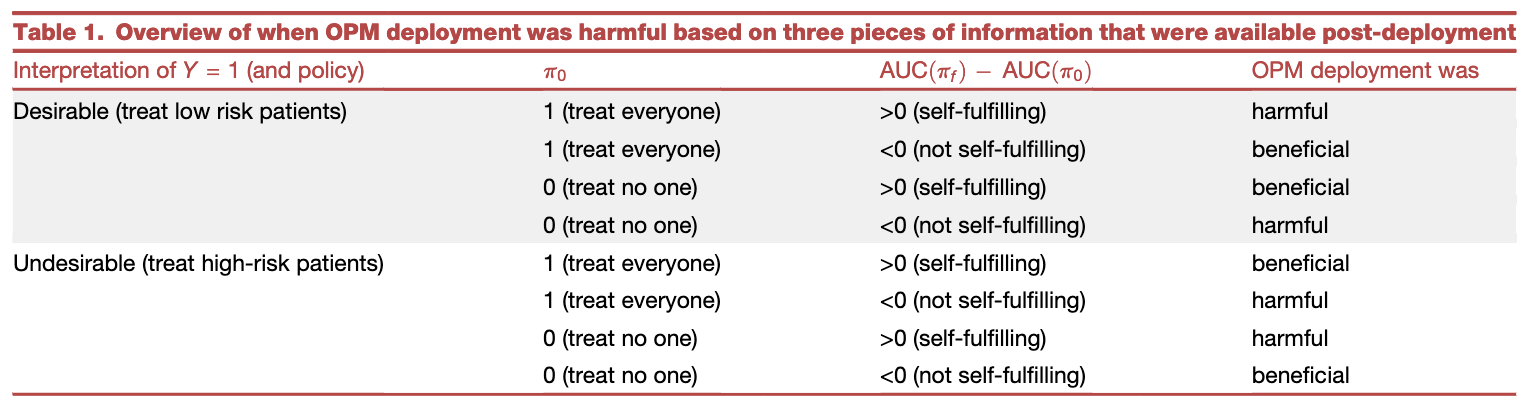
Calibration result
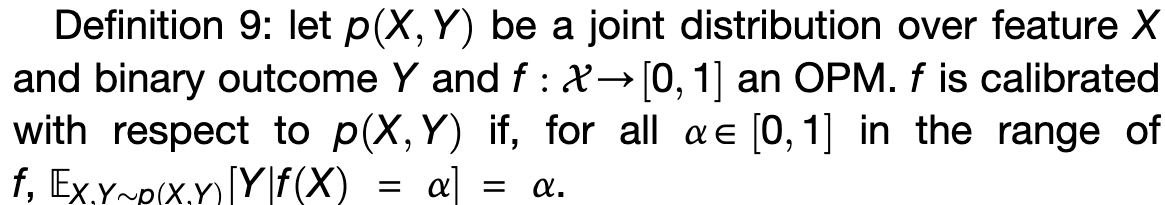

- ergo deployment of model was useless
Did we slay the vampire?

Editorial

Press coverage - urgent mail
Press coverage
Press coverage

Science Media Center Roundup (7 experts)
