PROTECT update
Manchester / Rajesh
2025-07-13
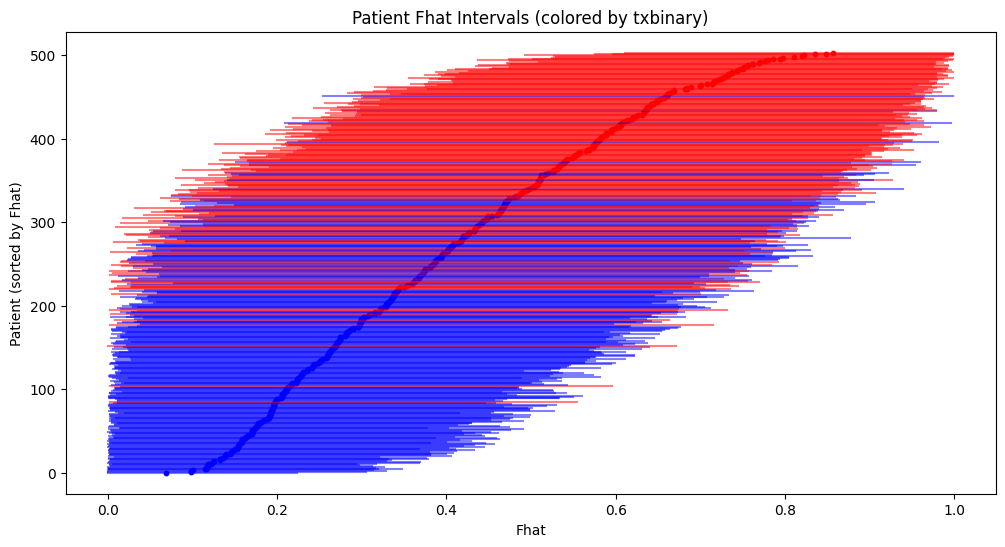
PROTECT uses a latent factor model for the unobserved confounder
- PROTECT models the joint likelihood of ‘observables’:
- treatment \(T\), survival \(Y\) and proxies \(W\) of fitness (performance score, fraily)
- … conditional on ‘controls’ \(X\) (age, stage, histology)
- in addition to ‘global parameters’ \(\theta\) that any regression model has (e.g. treatment to outcome regression coefficient), PROTECT has ‘local parameters’ (local to every patient \(i=1, ... N\)): \(F_i\)
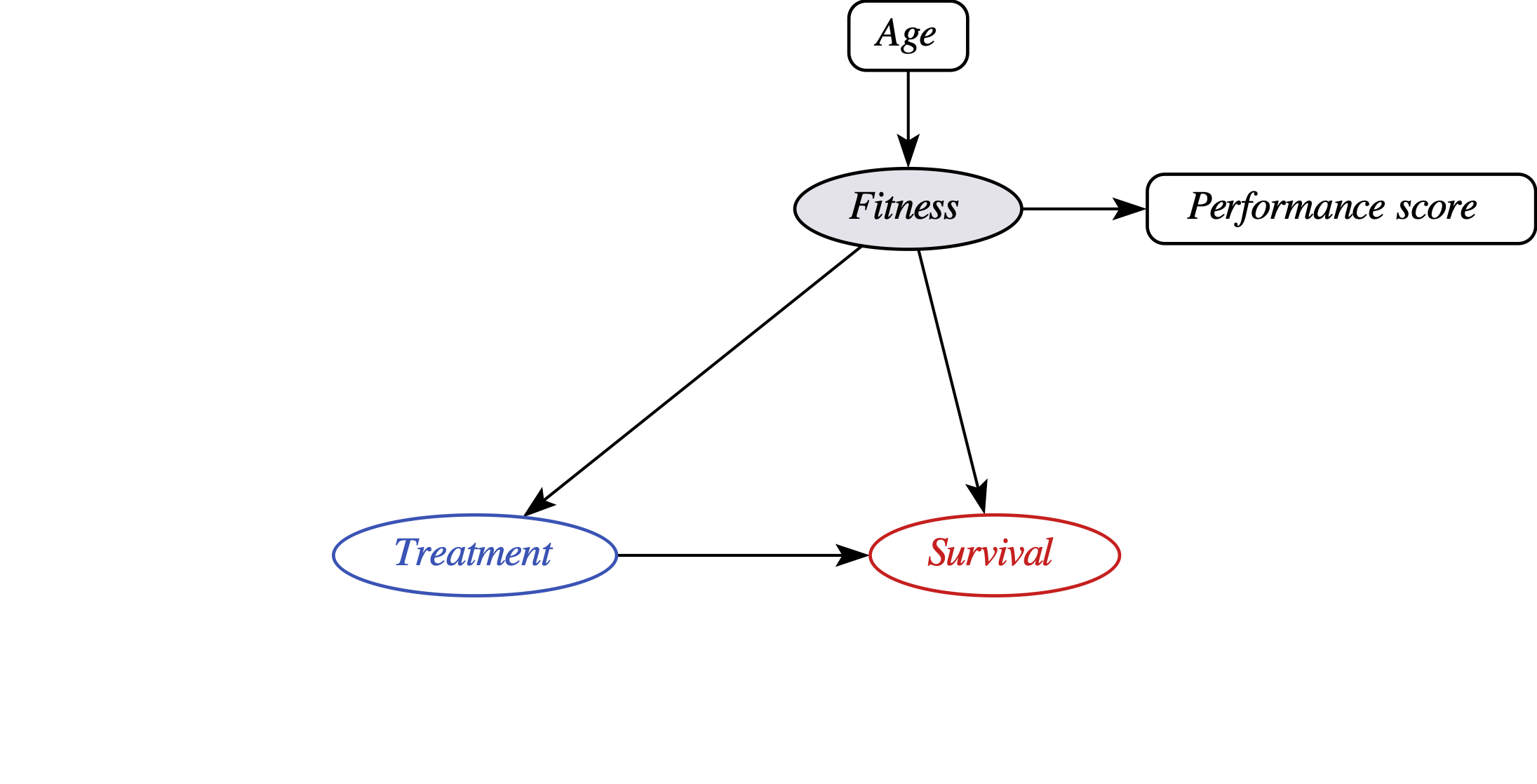
approximation in original PROTECT
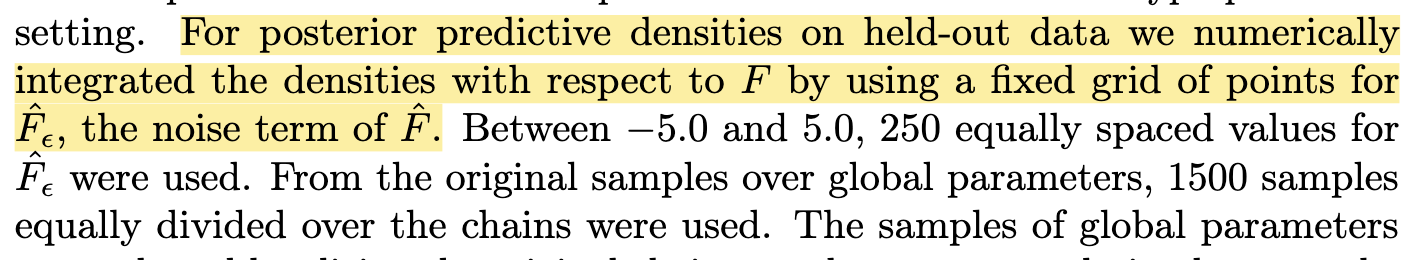
- take a grid of values for \(f\), for each value (and a given \(\theta_s\)), calculate the joint likelihood of the observables for that posterior predictive mode (e.g. \(W_i,T_i\))
- calculate the weighted sum of the log-likelihood of observed \(Y_i\), weighted by the joint likelihood of the \(F-\)conditioning observables
- omission: calculation did not weigh in the prior probability of \(f\), so the predictive likelihoods do not correspond to the actual PROTECT model
‘new’ solution: use Gauss-Hermite Quadrature
- to integrate over a gaussian distribution, pick \(K\) carefully chosen points \(X_k\) with corresponding weights \(W_k\)
- implemented in PROTECT library, consequences:
- with much fewer points (\(K=32\)),
- much better approximation,
- incorporates prior over \(f\)
- the new approach is tested in cases with analytically knwon likelihoods (gaussian outcome and proxies)
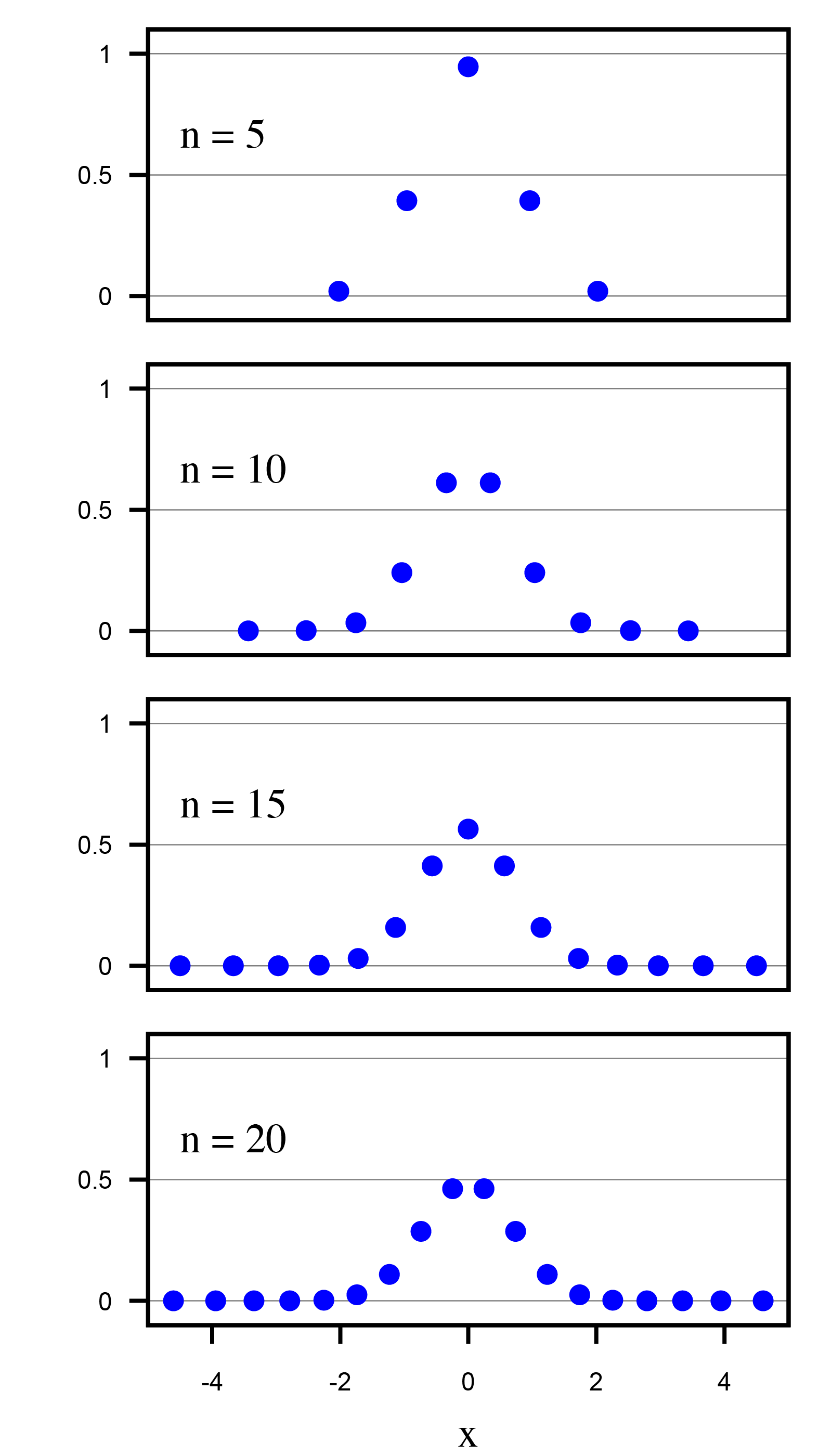
Utrecht overlap?