A causal viewpoint on prediction model performance under changes in case-mix
Human Data Science ‘Content Meeting’
2025-05-22

Change in setting
What can we expect from the model’s performance (if anything) in the new setting?


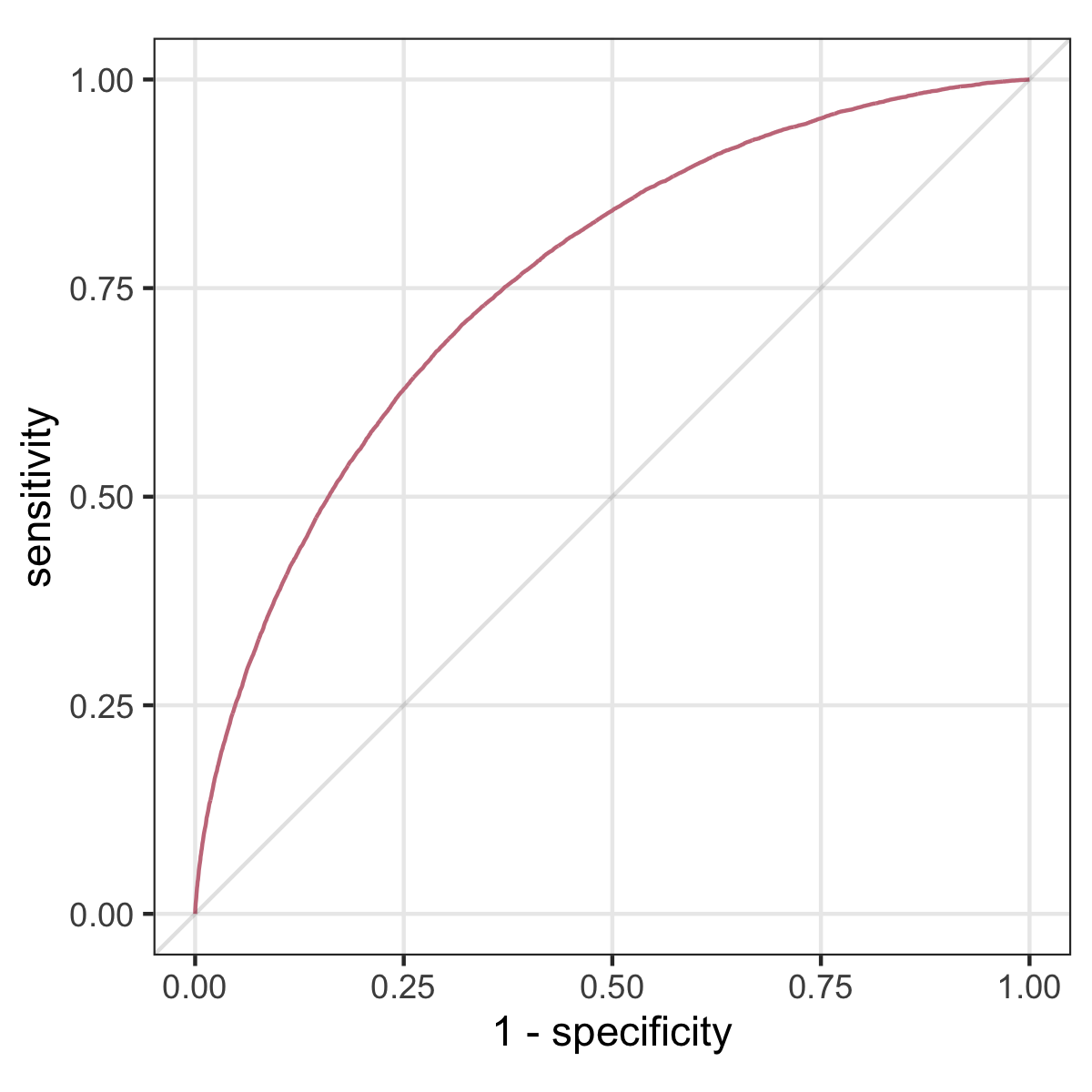
Discrimination: ROC curve and AUC
if we vary the threshold \(0 \leq \tau \leq 1\), we get a ROC curve, and the AUC is the area under this curve
Calibration
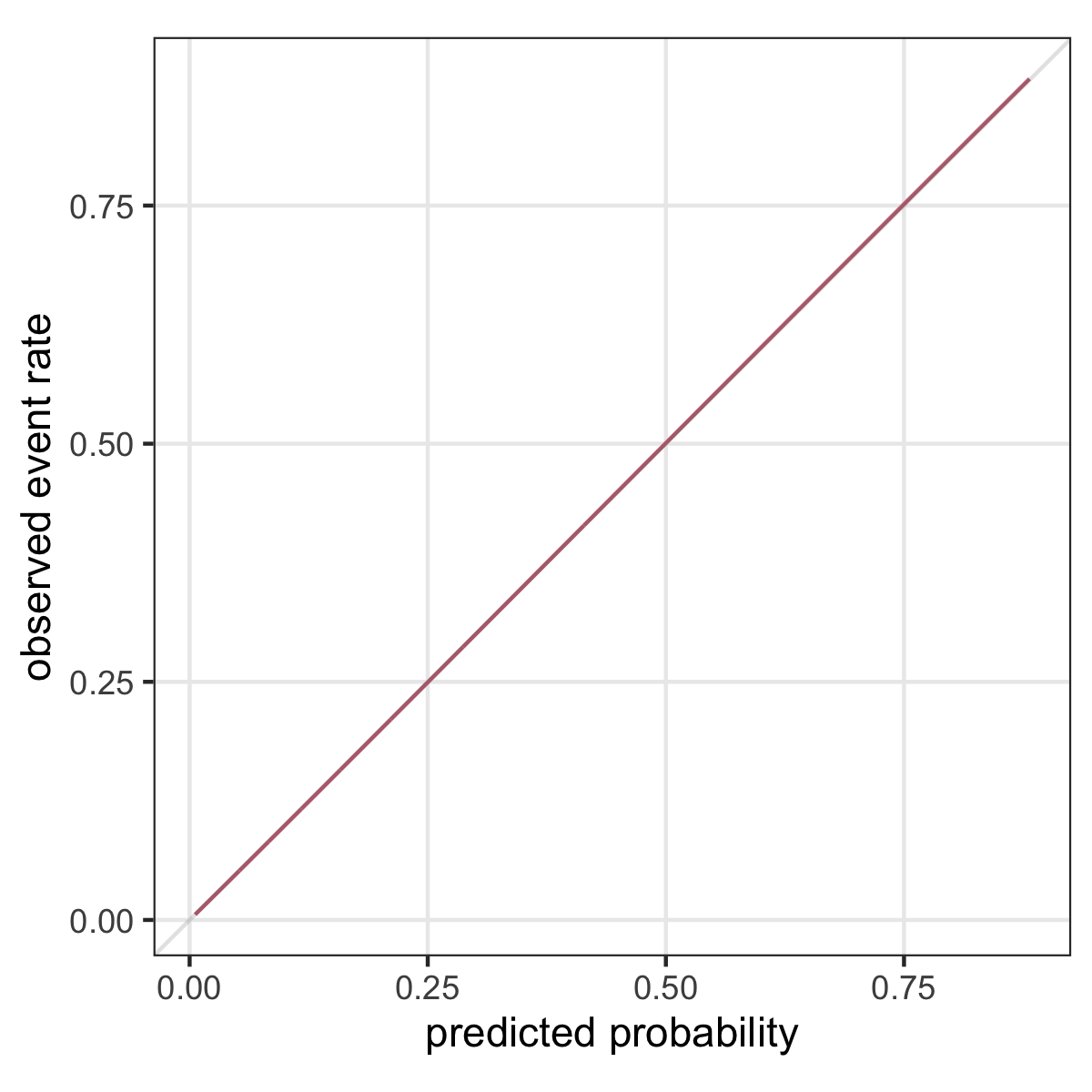
“A model is said to be well calibrated if for every 100 patients given a risk of x%, close to x have the event.” (Van Calster and Vickers 2015)



Calibration plot
\(p(Y=1|X)\) versus \(f(x)\)

Where does the association come from?
In prediction, we have features \(X\) and outcome \(Y\) and model \(Y|X\)
1. \(X\) causes \(Y\): often in prognosis (\(Y\): heart-attack, \(X\): cholesterol and age)
2. \(Y\) causes \(X\): often in diagnosis (stroke, based on neurological symptoms)
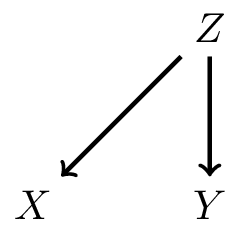
3. \(Z\) causes both \(X\) and \(Y\): confounding (yellow fingers predict lung cancer)
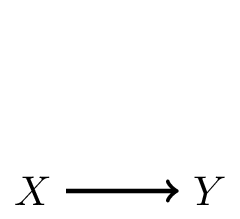
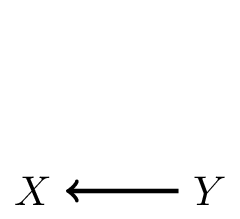
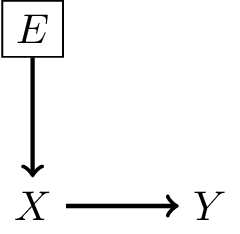
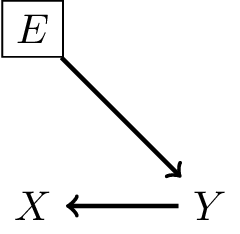
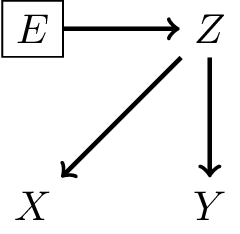
Defining a shift in case-mix
Define a shift in case-mix a change in the marginal distribution of the cause variable. Denoting environment as variable \(E\):
- pregnancy outcome prediction
- general ‘midwife’ population
- pregnant women with type 1 diabetes are counselled by gynaecologists in hospital
- this is filtering on patient characteristics (making distribution of \(X\) different)
- predict occurence of stroke
- general emergency center
- patients with clear neurological symptoms are sent to stroke center
- filter on outcome risk (different distribution of \(Y\))
What does this definition imply?
- in general, may decompose \(P(X,Y,E)\) as:
- \(P(Y|X,E)P(X,E)\)
- \(P(X|Y,E)P(Y,E)\)
- …
- looking at the DAG: \(P(Y|X,E) = P(Y|X)\)
- in words: \(P(Y|X)\) is transportable across environments
- because there is no arrow from \(E\) to \(Y\), \(X\) blocks effect of \(E\) on \(Y\)
- \(P(X|Y,E) \neq P(X|Y)\)
- in words: \(P(X|Y)\) is not transportable across environments
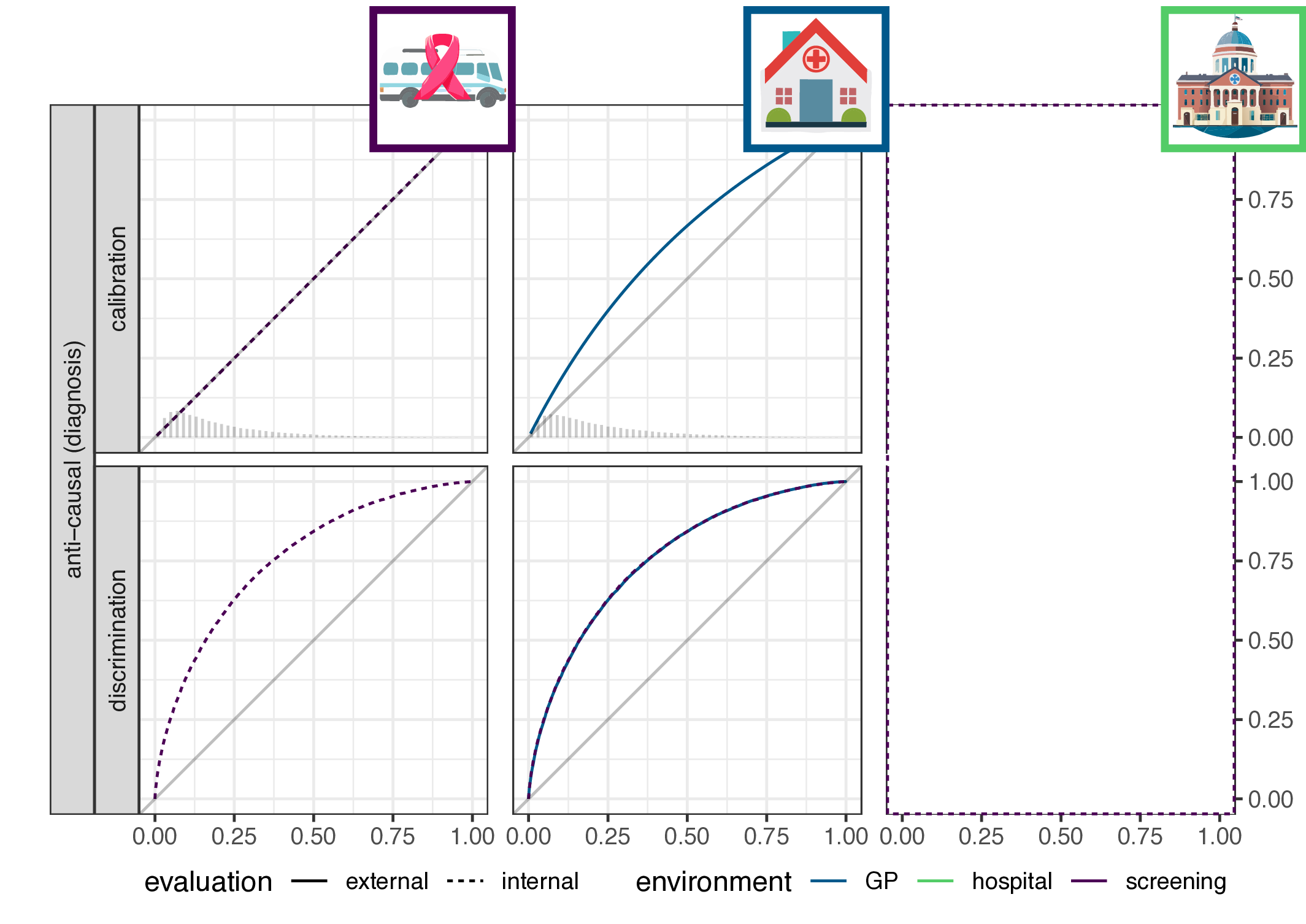
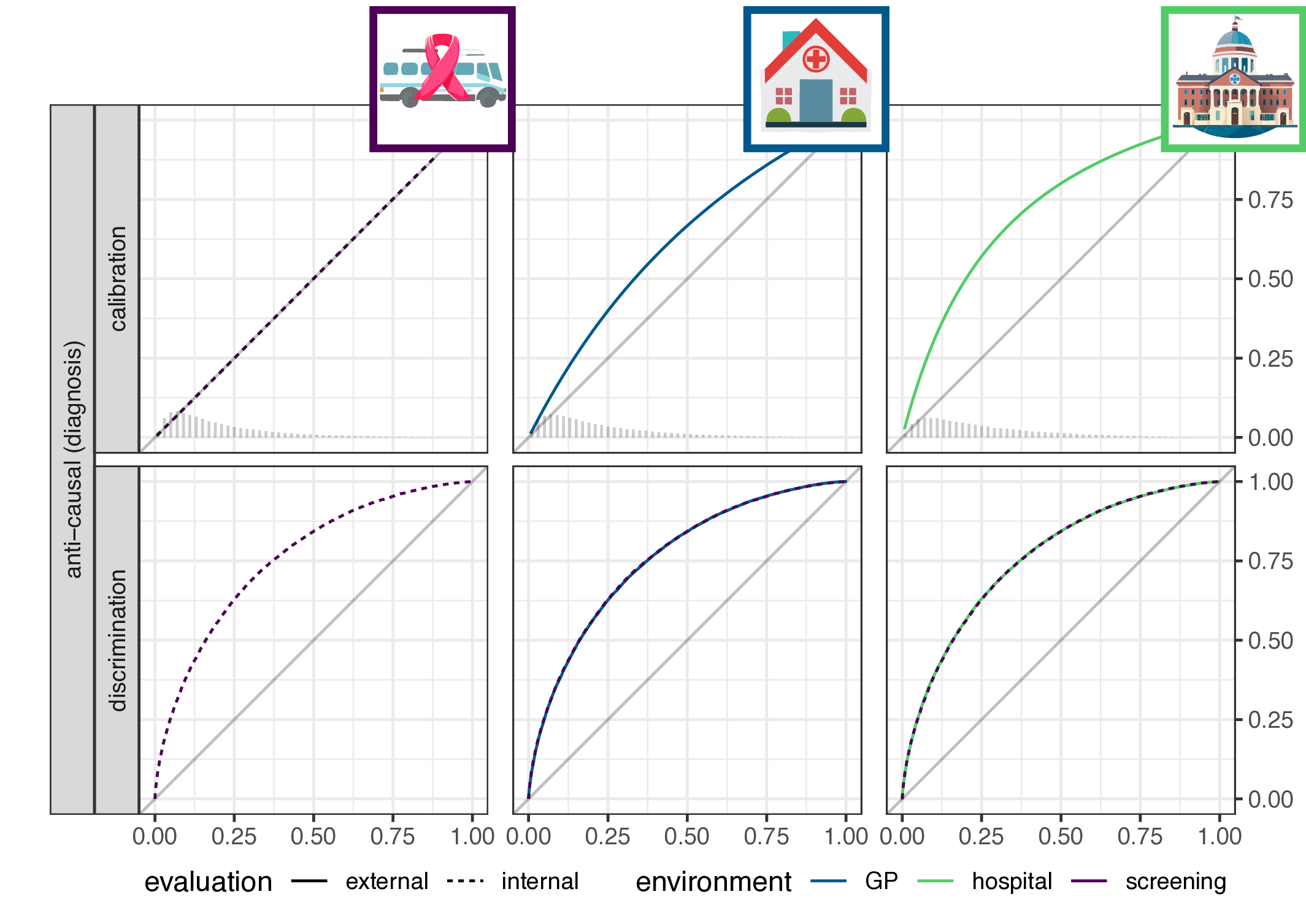
- implication for causal (prognosis) prediction:
- calibration is functional of \(P(Y|X)\), thus stable
- discrimination is functional of \(P(X|Y)\), thus not stable
- for anti-causal (diagnosis) prediction: the reverse
- main result: discrimination or calibration may be preserved under changes in case-mix, but never both
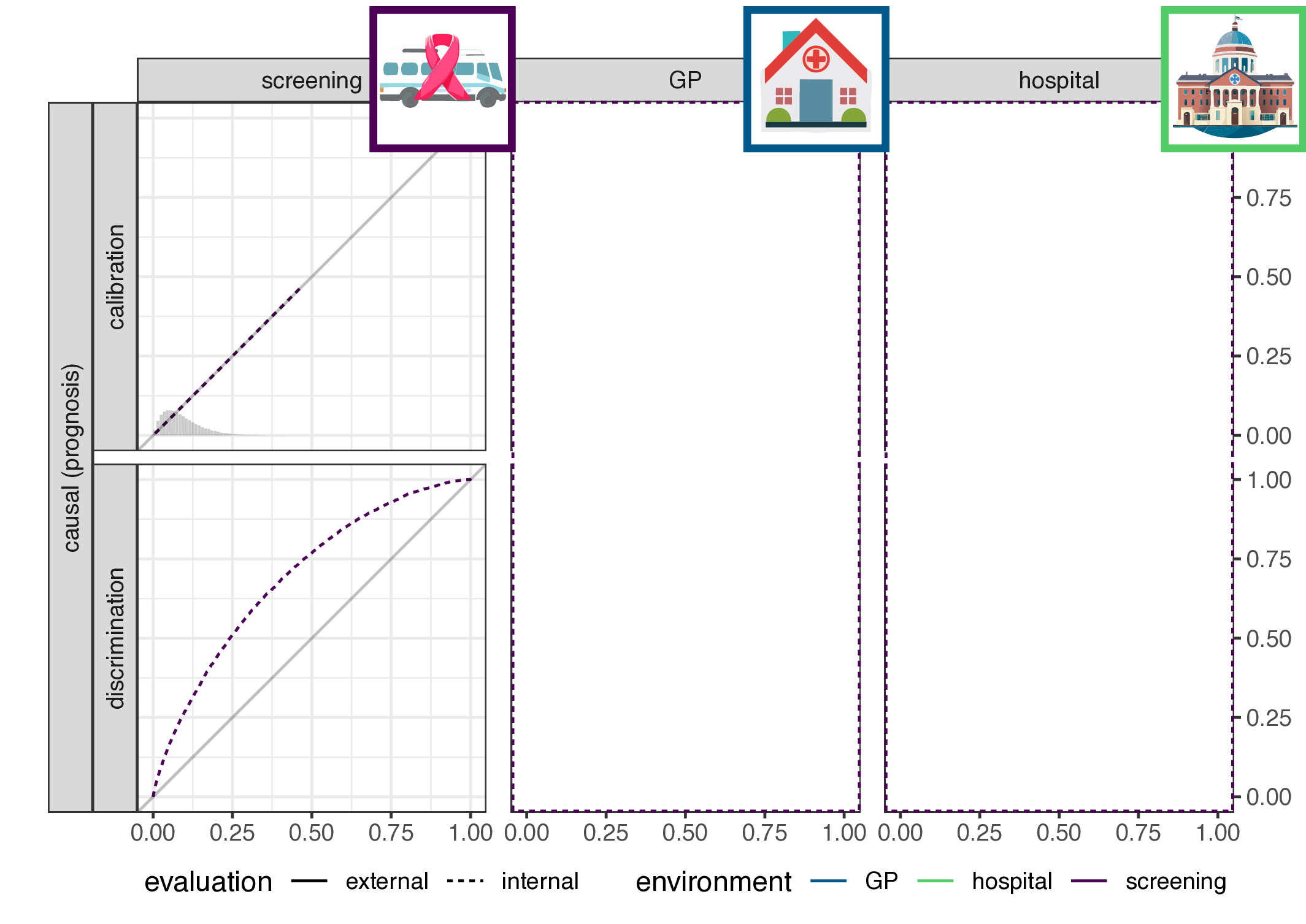
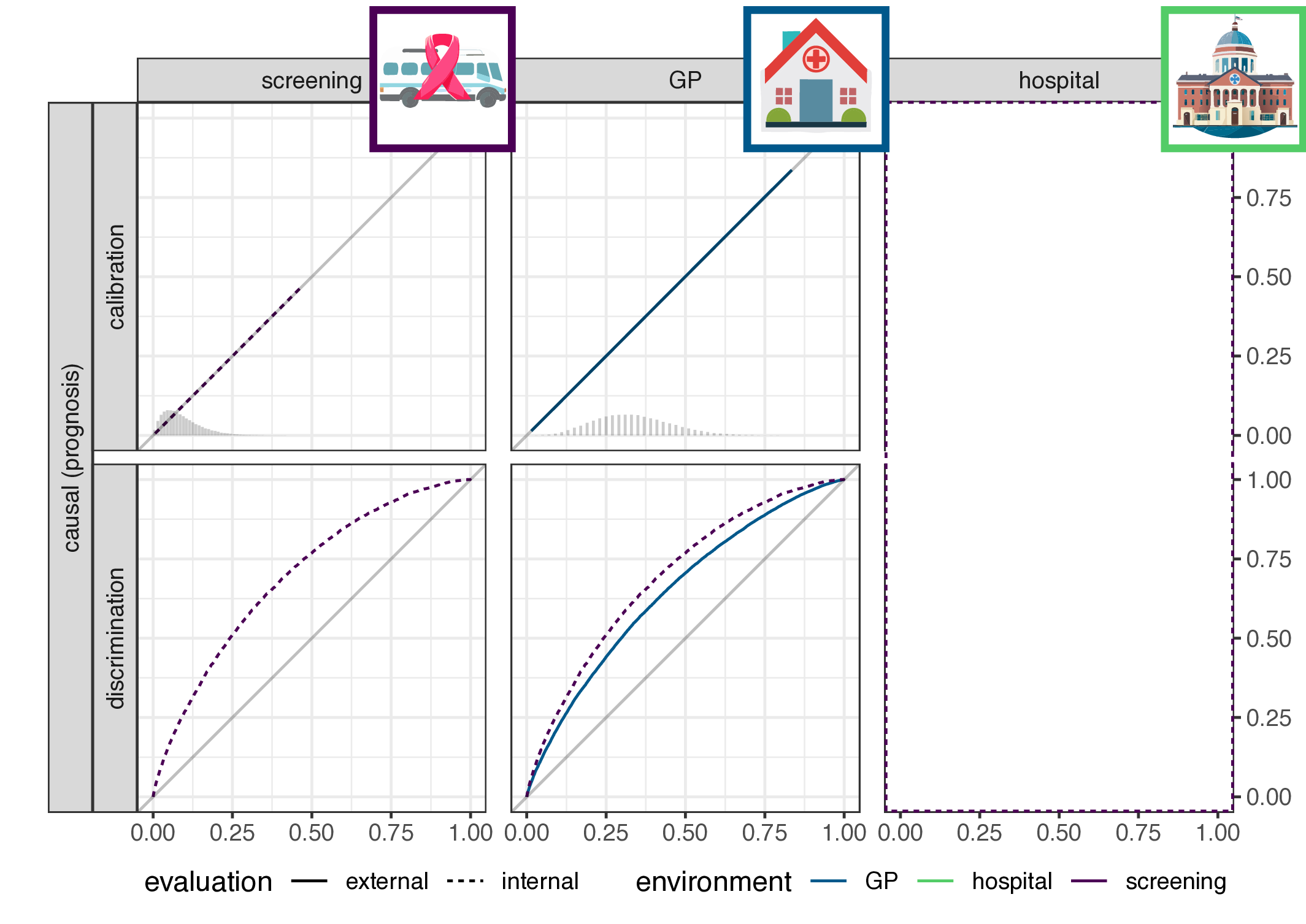
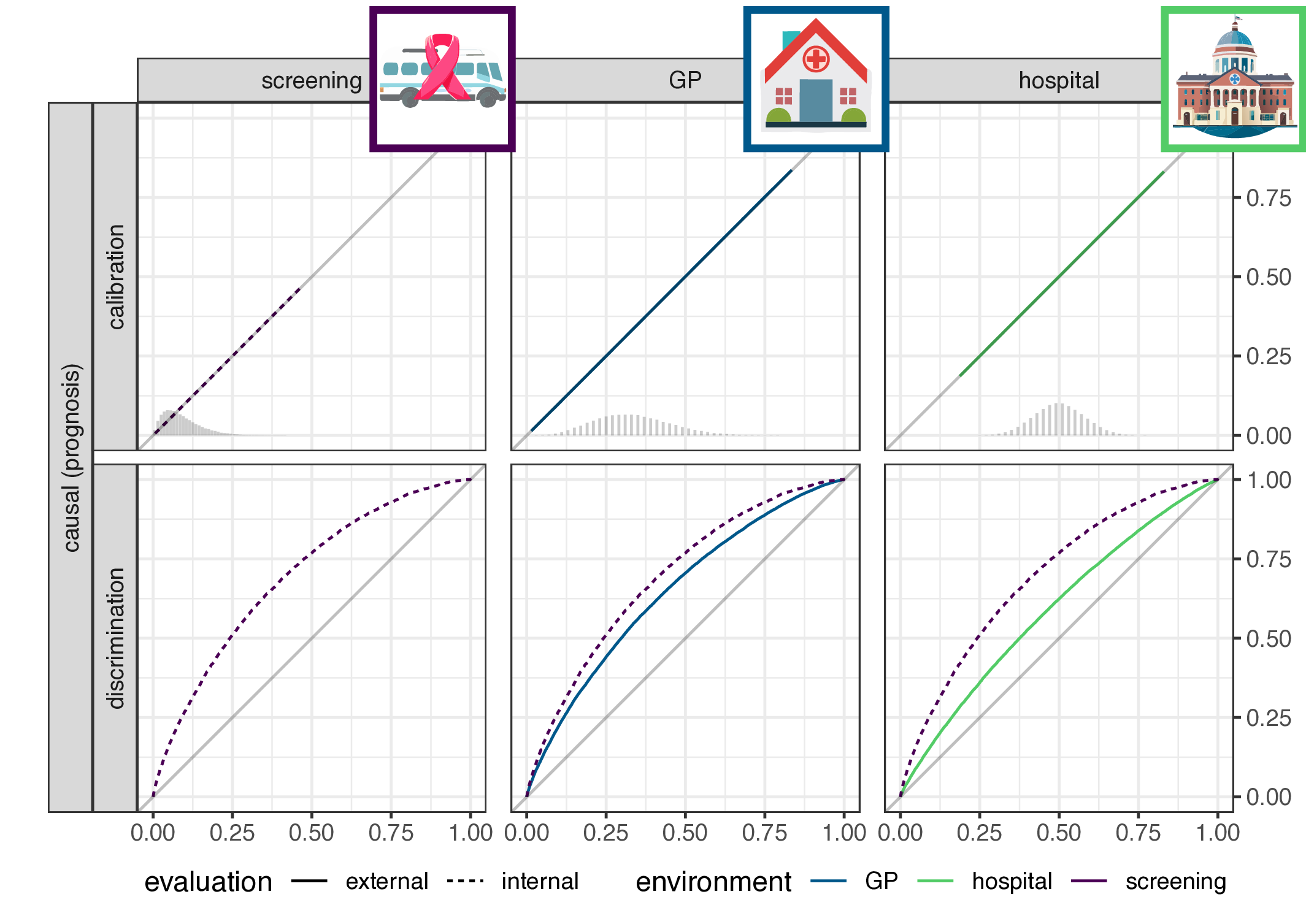
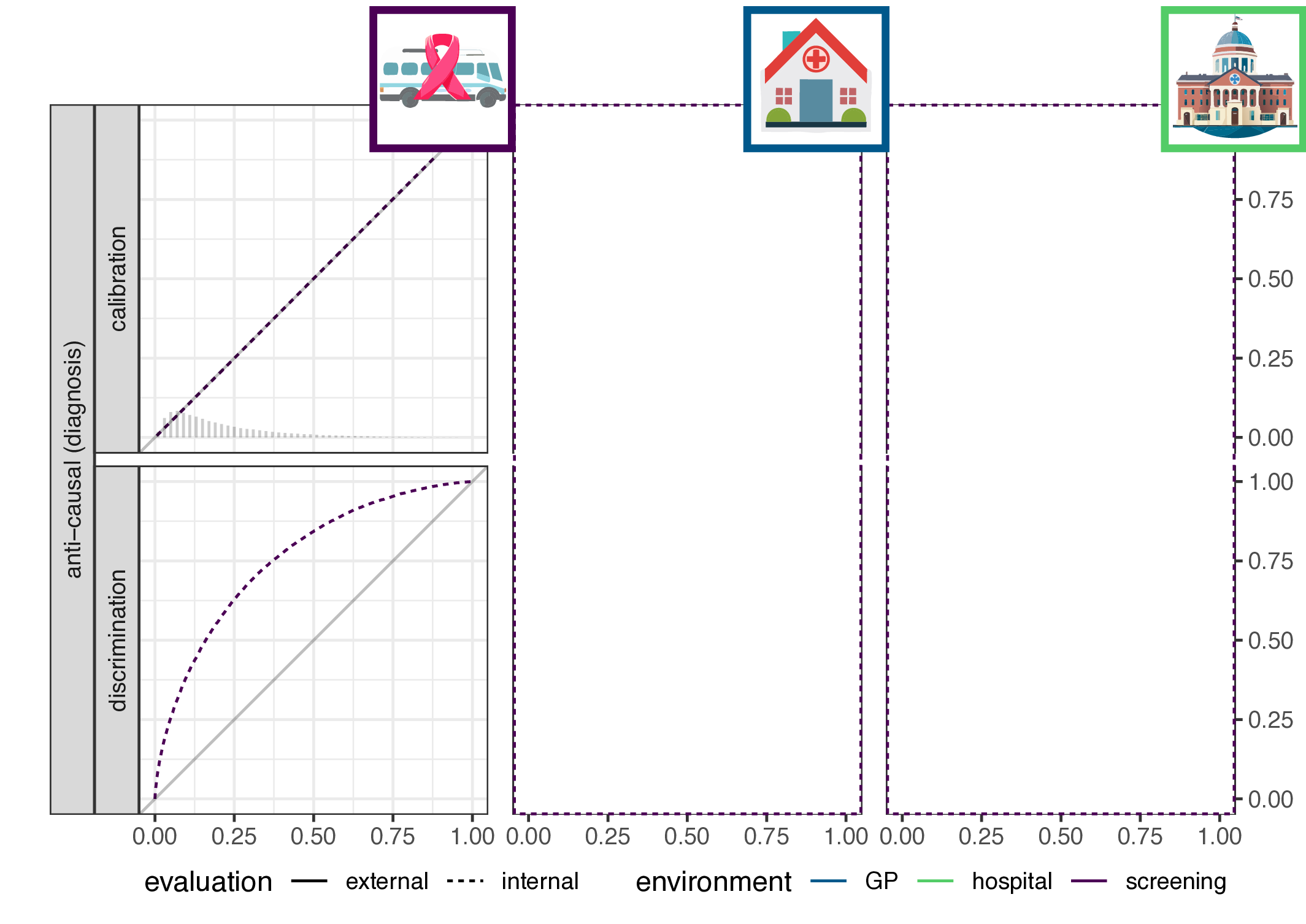
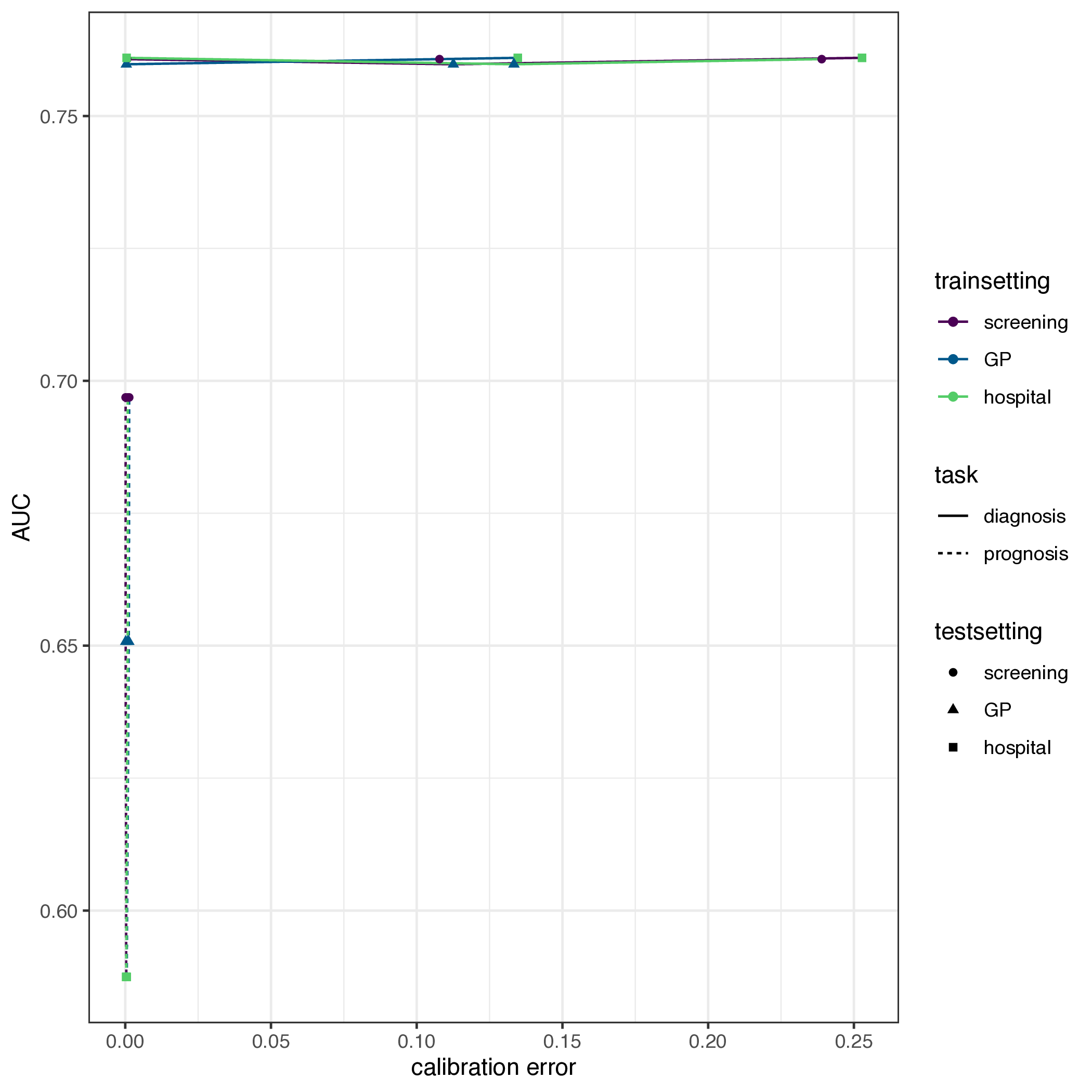
Empirical evaluation
- a study of 2030+ evaluations of 1300+ prediction models (Wessler et al. 2021)

- registry: all data available with only 4000 clicks
- solution: scrape the website