my priorities for AI in health
Dagstuhl Seminar 2025
2025-01-27
post-deployment monitoring and evidence
- want safe and effective AI
- EU / FDA work on regulating post-deployment monitoring
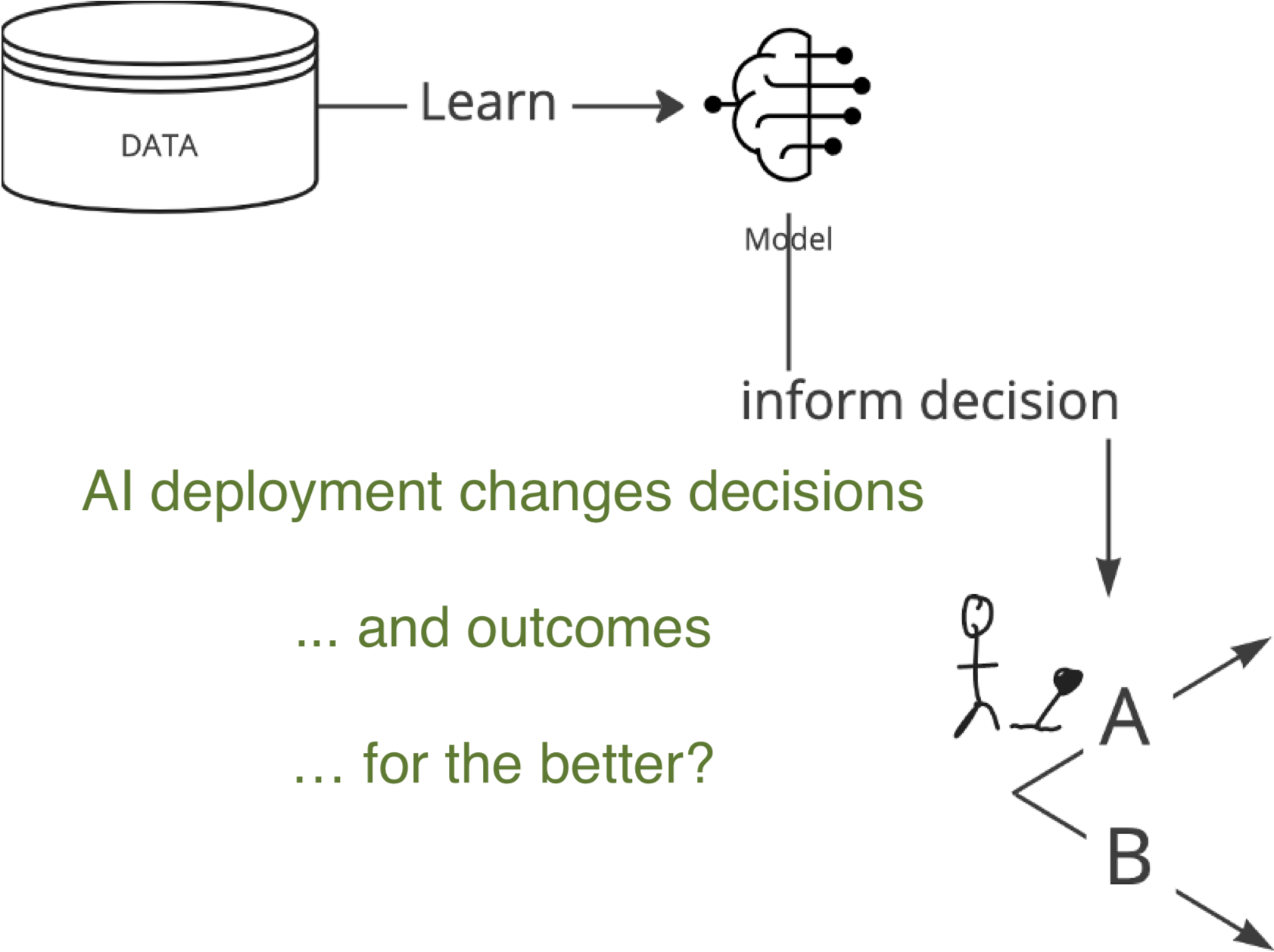
AI deployment as an intervention
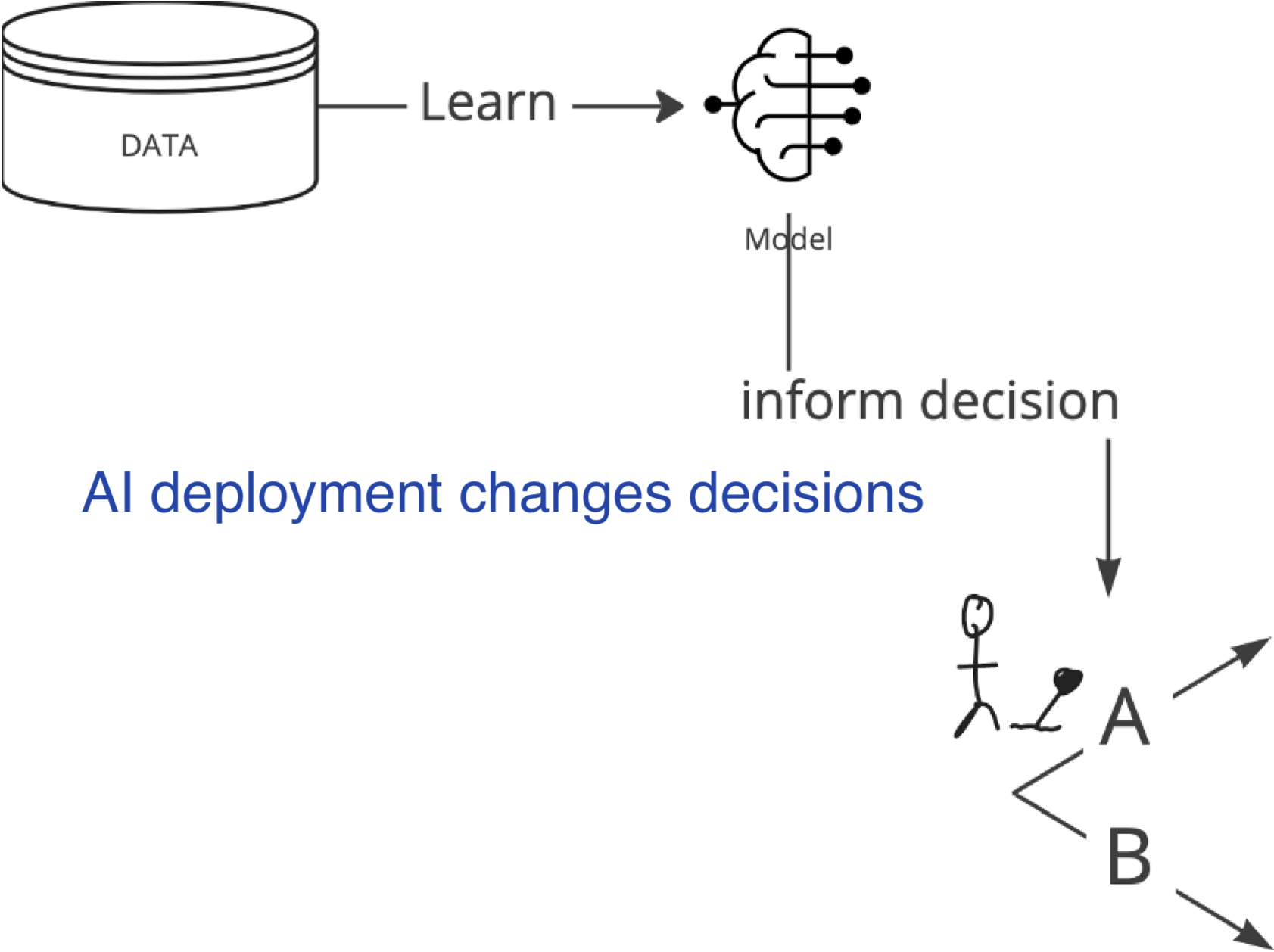
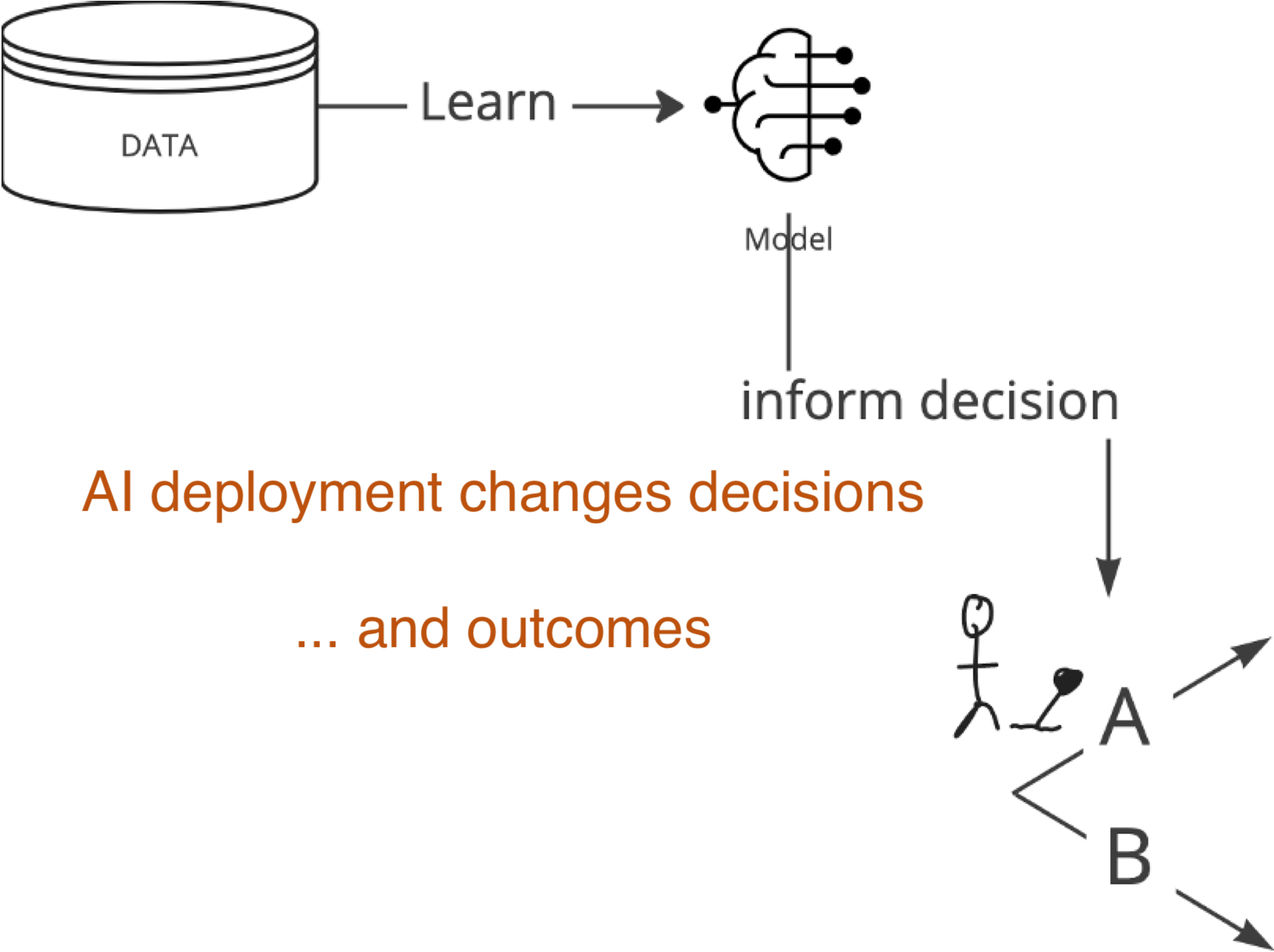
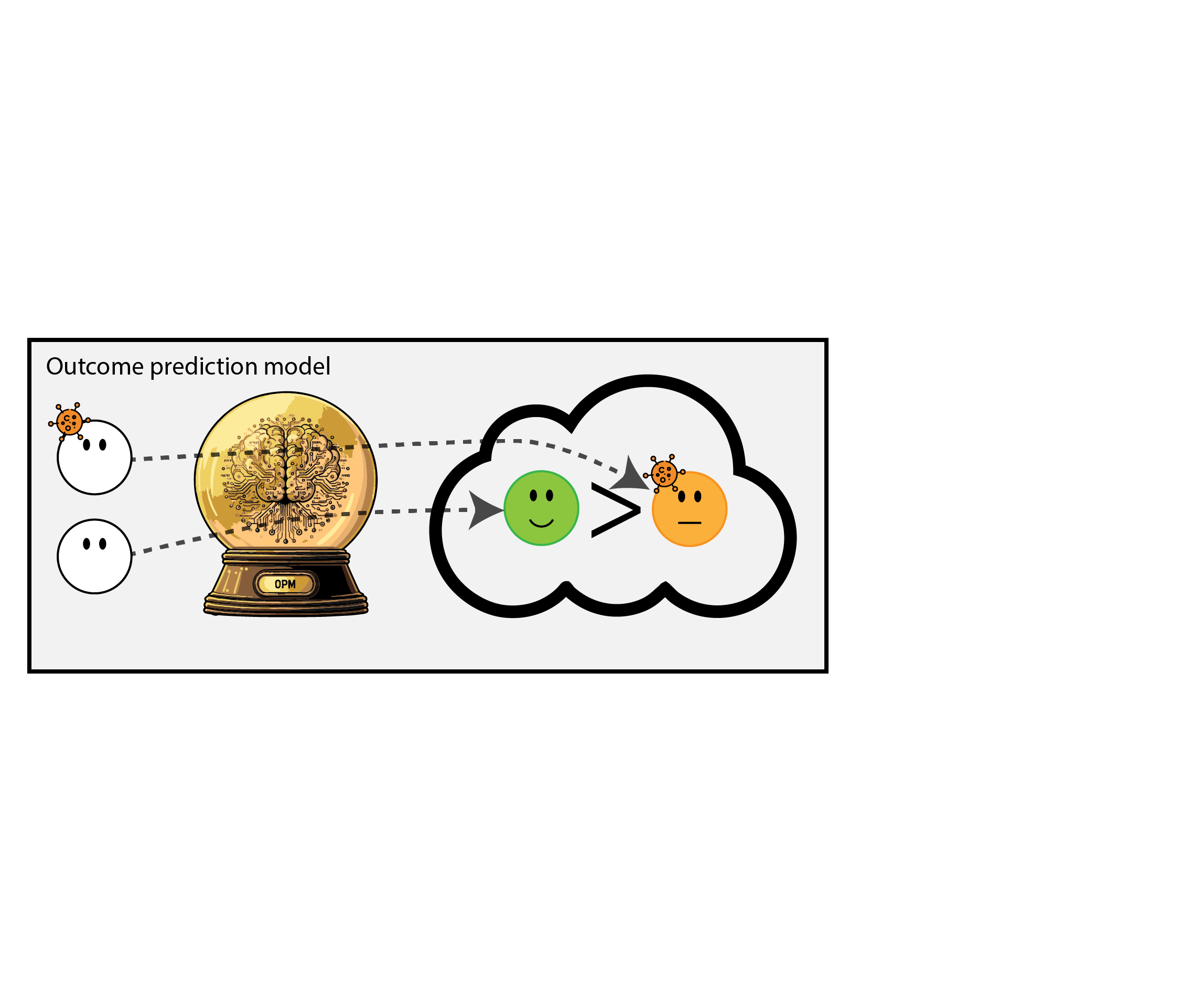
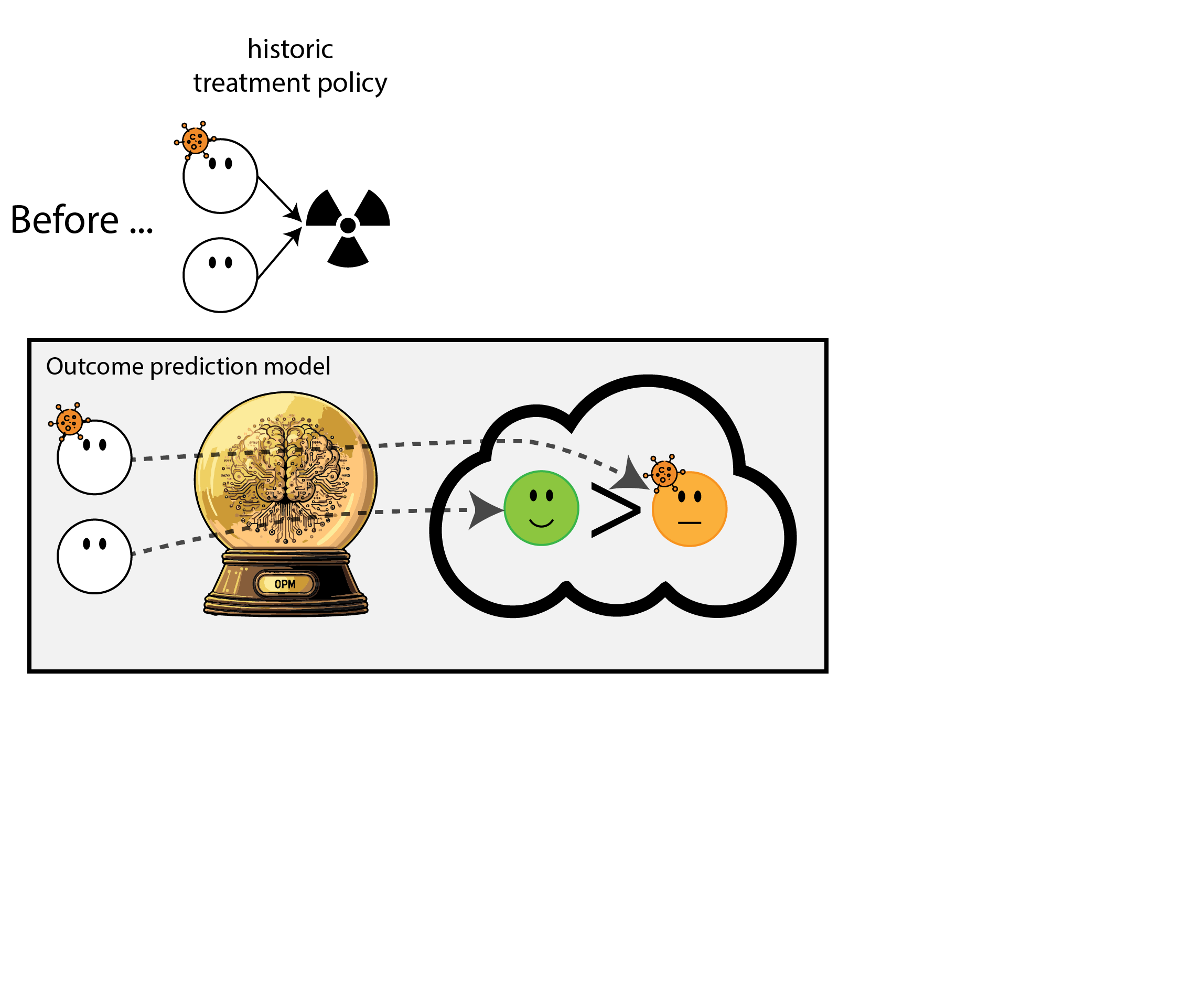
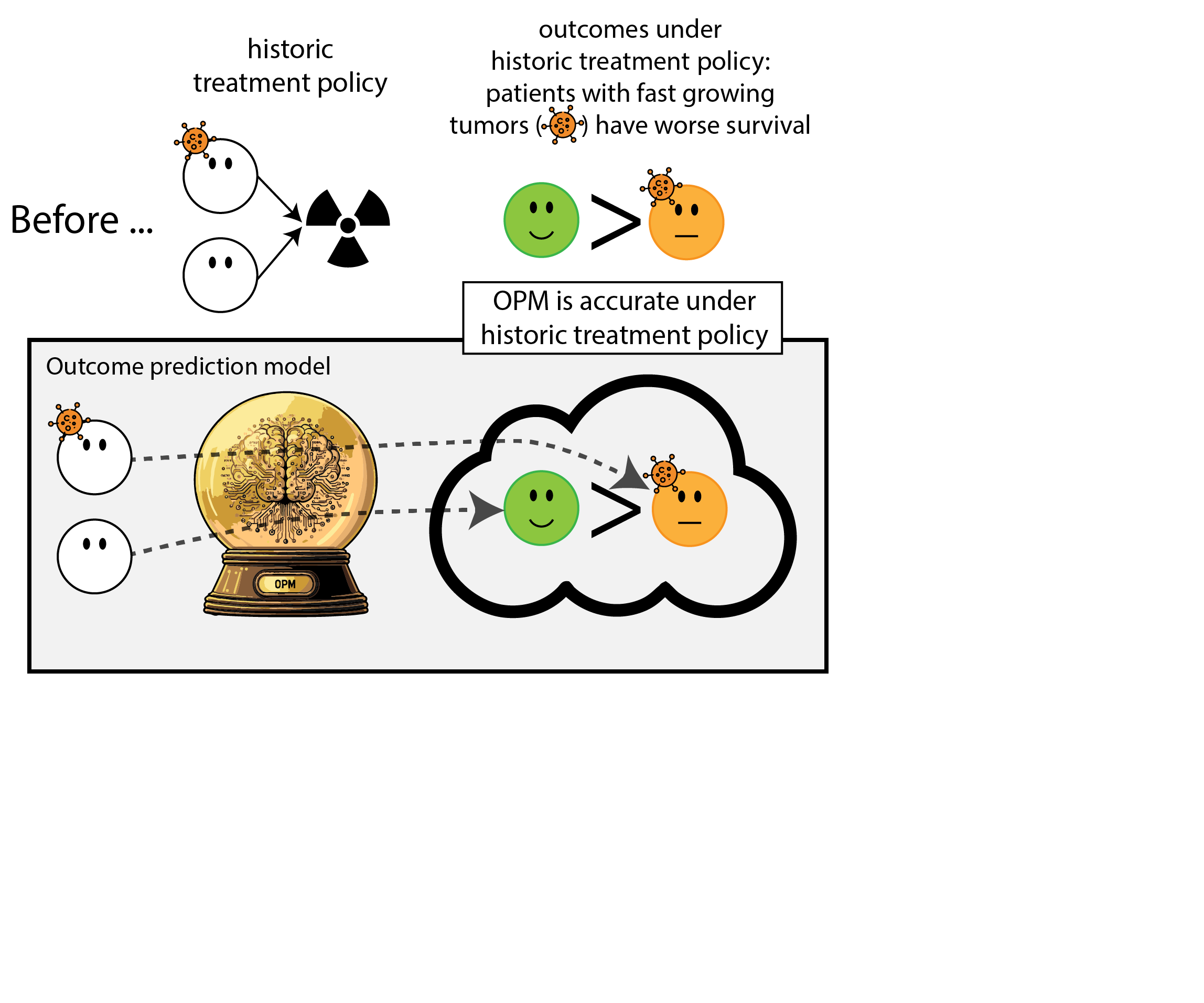
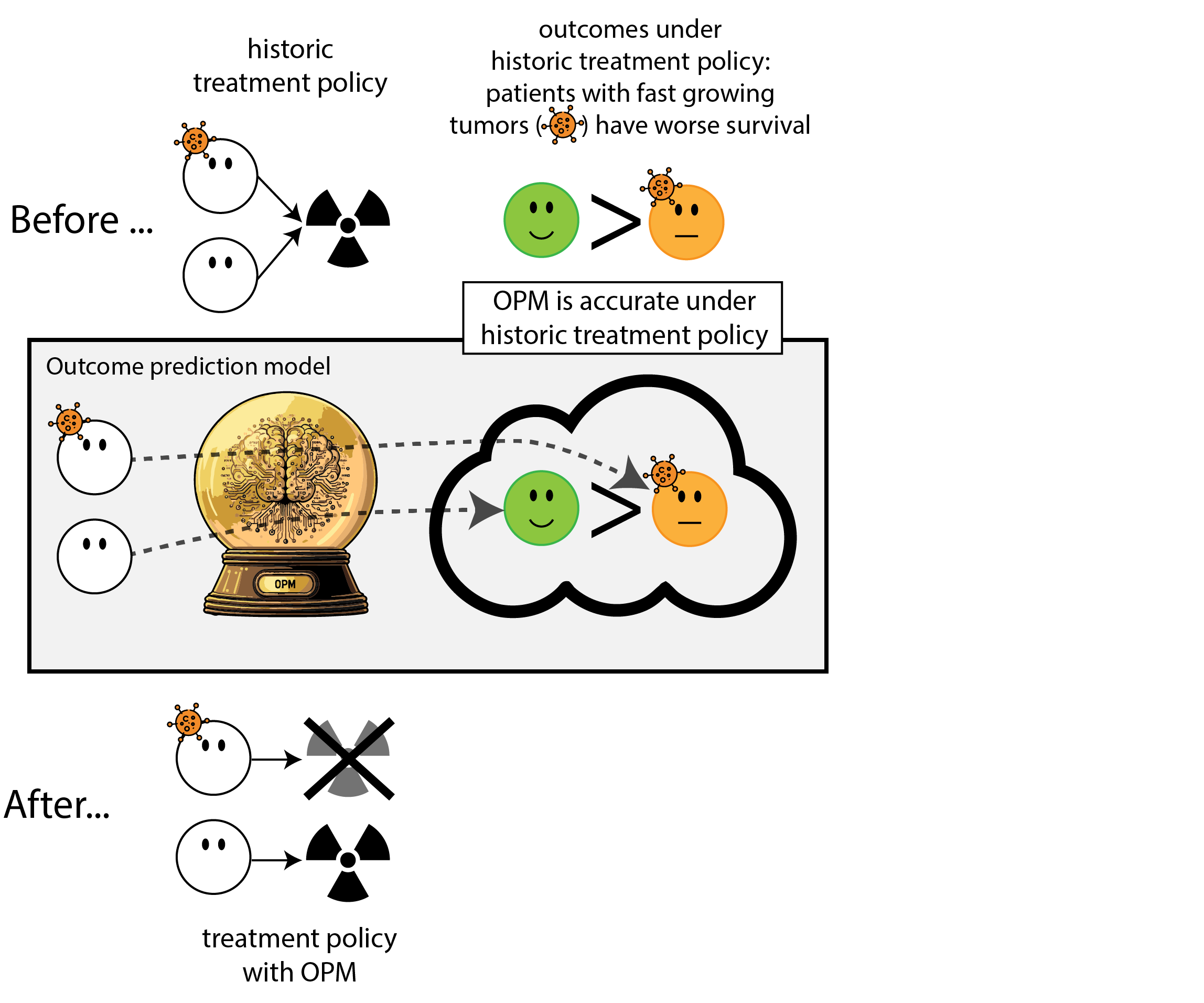
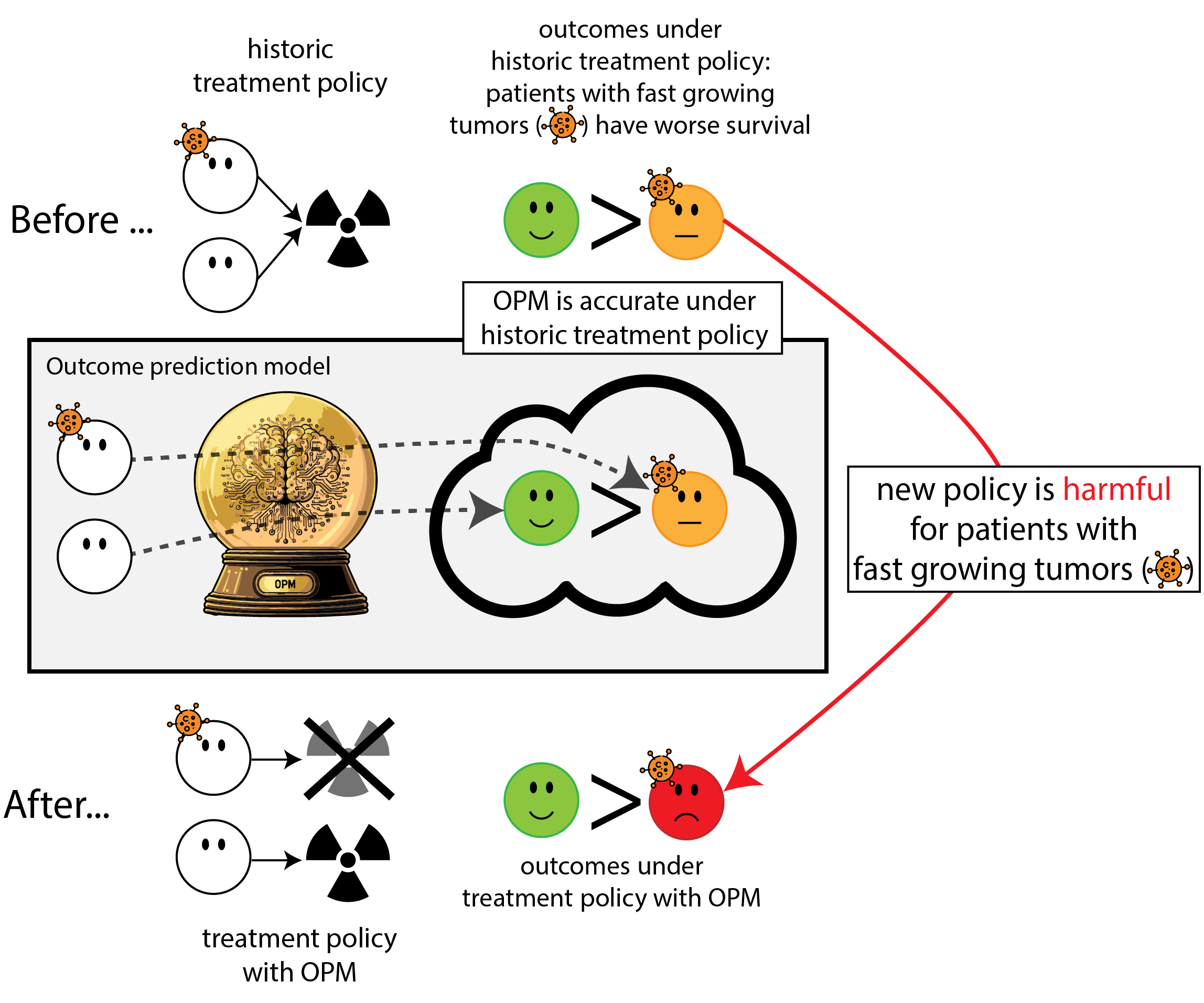
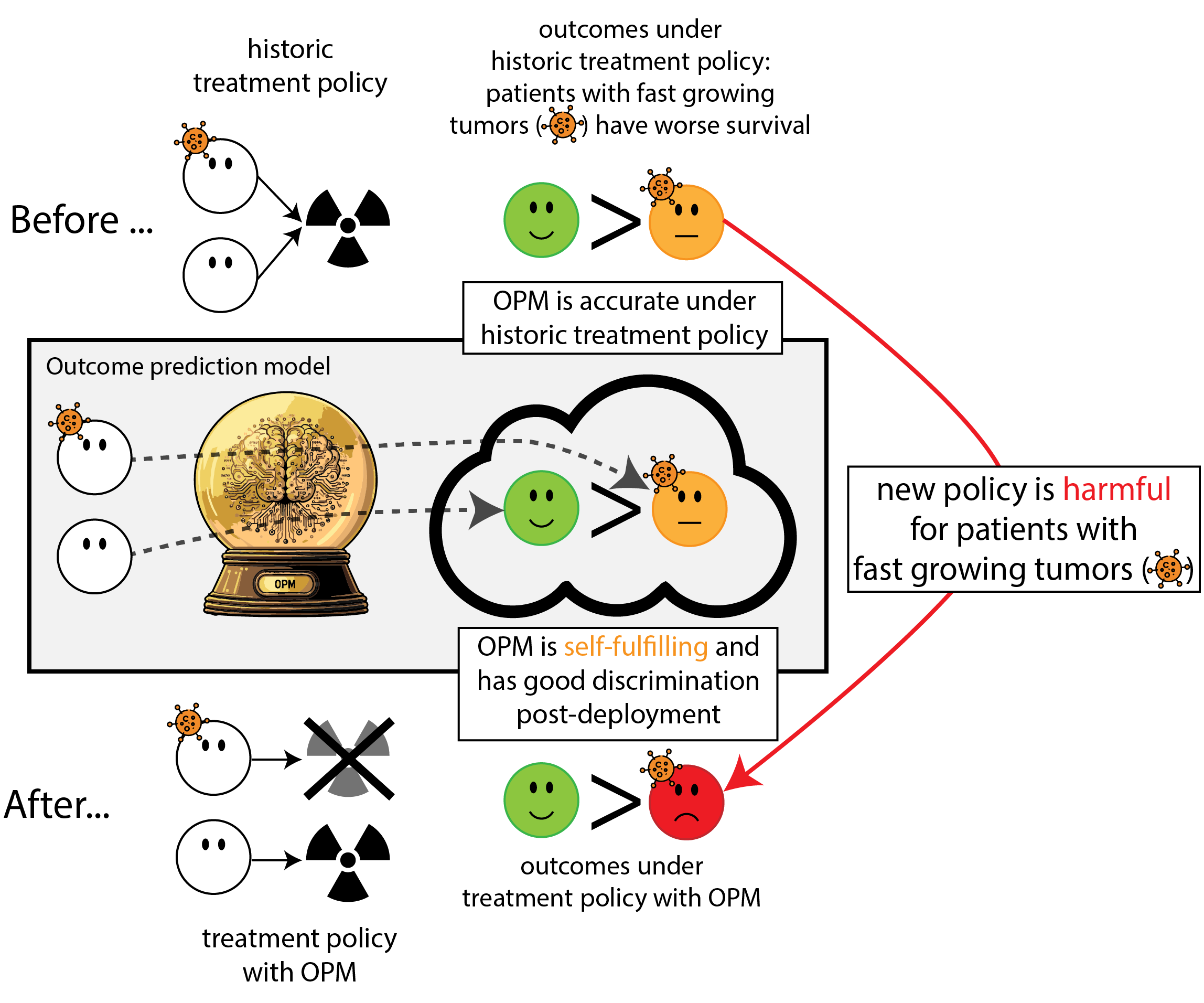
When accurate prediction models yield harmful self-fulfilling prophecies
How this can go wrong if we misalign the AI evaluation metric and the patient oucome
Patterns, 2025

why is it hard:
- AI deployment is an intervention, knowing whether this improved outcomes for patients is causal inference (Joshi et al. 2025)
- before-after comparison plagued by potential time-trends
- optimal pre-deployment evidence: (cluster) RCT
- after deployment: changes in the data
- by the deployment (that was what we wanted)
- and many other factors.
- measures of prediction accuracy do not automatically translate in patient benefit (Van Amsterdam et al. 2025)
opportunities
- what to track after deployment?
- accuracy, outcomes
- how to track after deployment?
- randomization on center level: need many centers (possible in large health systems in the US?);
- randomization on patient label: need consent
- ethics in randomization; who provides consent?
- combine AI + causal inference + trial design + ethics
prediction under intervention
Prediction-under-intervention, why work on it?
Prediction under intervention is estimating expected outcomes under hypothetical interventions, conditional on patient characteristics
(aka counterfactual prediction)
\[E[Y|X,\text{do}(T)]\]
this is not the fast road from computer science experiment to impact, but may be the most rewarding
- why work on it? holy grail: know what to do
What is not prediction under intervention
Using QRISK to decide on blood pressure medication (which it’s not intended for)
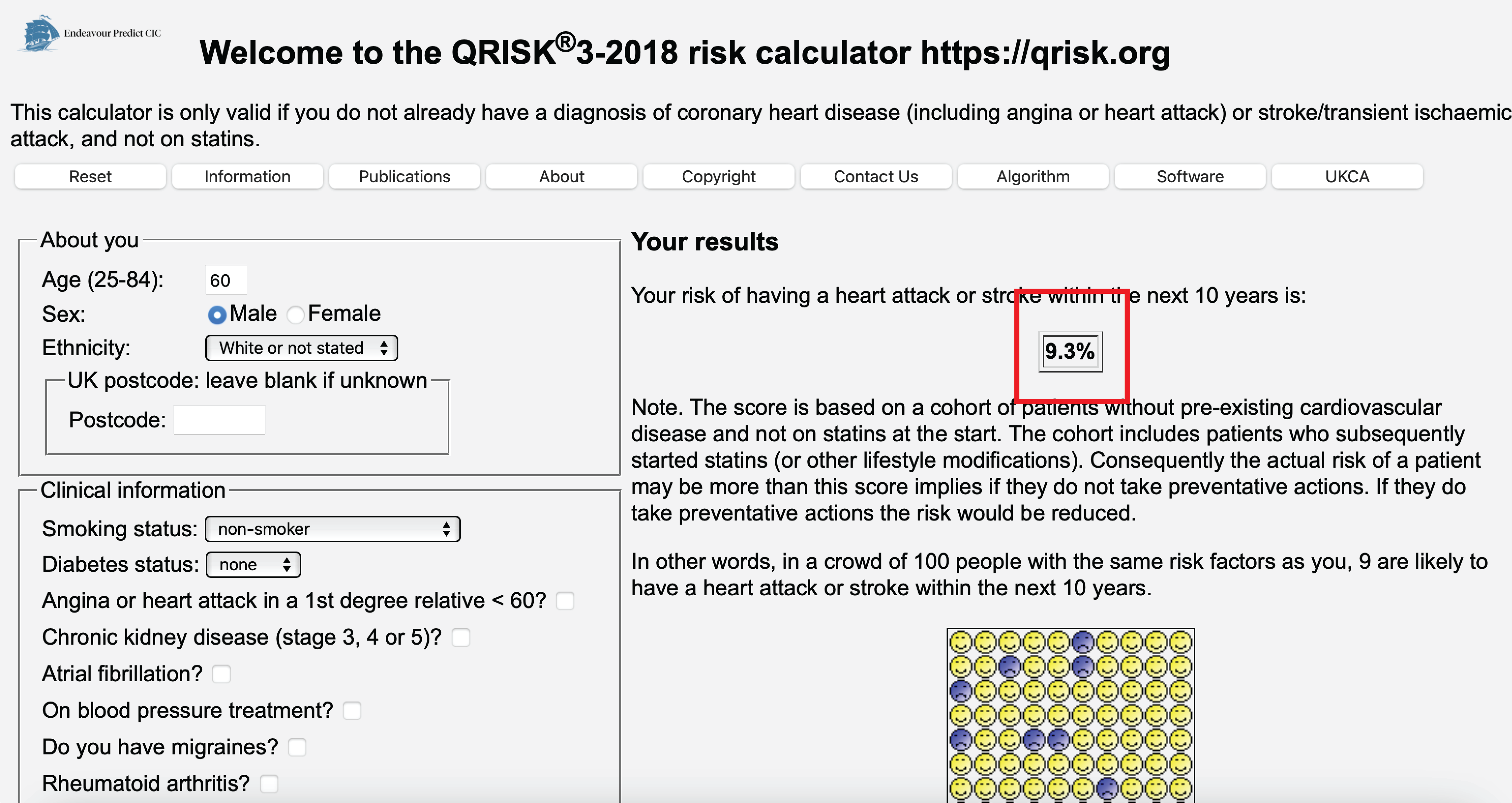
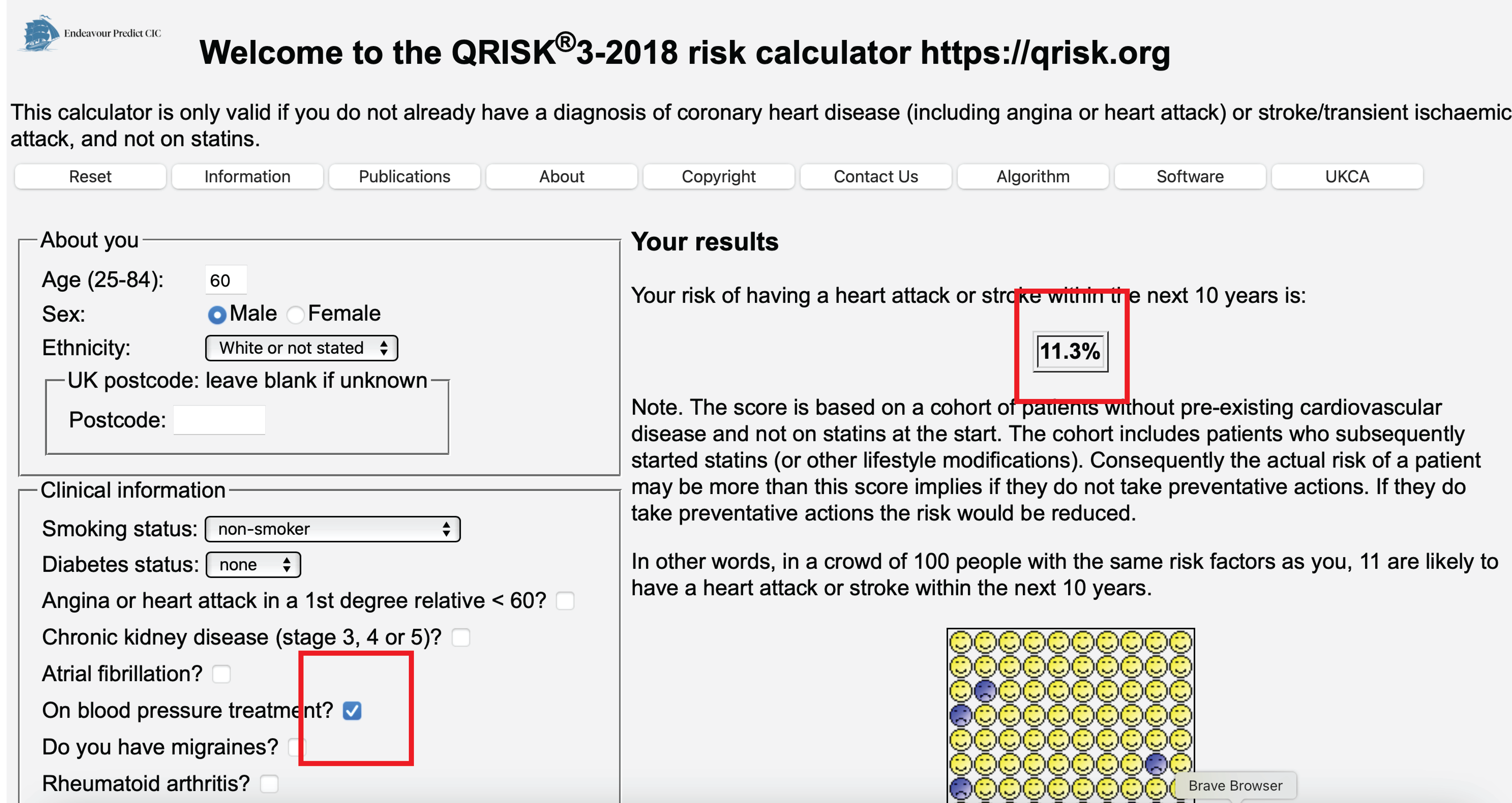
Is QRISK bad?
- is it inaccurate? no, it informs of the risk of an event given that the patient has blood pressure medication (post-decision model)
- this is not the same as the risk if we were to give blood pressure medication or not
- these are only the same when all factors going into the decision to given the blood pressure medication are accounted for (confounders, causal inference assumptions)
What is QRISK?
- intended for deciding on statin treatment, excludes patients who have statins ‘on baseline’
- is trained on patients of whom some recieced statins, reducing their risk of cardiovascular events
- predicts risk of cardiovascular events under current standard of care
- ‘a treatment-naive model’
Counseling with and without prediction under intervention
Imagine this dialogue between a patient who has just been diagnosed with cancer and their oncologist First, we’ll see a conversation informed by
- RCT data
- average outcomes (or contrast) between treatment \(A\) and \(B\)
- non-causal prediction models:
- predict outcome given features \(X\), ignoring effects of potential treatments (treatment-naive / average treatment policy)
- predict outcome given features \(X\) and treatment \(T\), ignoring confounding by \(Z\) (post-decision models)
Oncologist: Your work-up is done, we now know your cancer type and stage
Patient: What is my prognosis?
Oncologist (treatment-naive model): on average, other patients who share characteristics X with you live … more years.
Patient: Is there a treatment you can give me to improve my prognosis?
Oncologist (RCTs): treatment A leads to several more months survival than treatment B on average, though some patients have severe side effects
Patient: And how long do patients live with treatment A?
Oncologist: The average patient in the randomized trial who got treatment A lived … years, but those patients were younger and in better overall health than you so their results may not apply to your specific case.
Patient: So how long do patients like me survive when they get treatment A?
Oncologist (post-decision model): Looking back, patients who share characteristics X with you and got treatment A lived … years. However, these patients may differ with respect to characteristics Z from you.
Patient: This is getting a bit confusing, should I or should I not get treatment A?
Oncologist: I know this is a very tough decision, but ultimately, it’s yours to make.
Now a conversation with prediction-under-intervention models
Oncologist: Your work-up is done, we now know your cancer type and stage
Patient: What is my prognosis?
Oncologist (prediction under intervention): That depends on the treatment we choose; patients like you would on average live … years on treatment A, versus … years on treatment B.
Patient: Thank you for this information. I will discuss this with my family and friends to decide what we think is best for me.
Prediction under intervention, why is it hard:
- answer a causal question, often cannot do (big enough) experiment (RCT), need assumptions otherwise (confounding, positivity)
- assumptions undermine trust; is it rigorous?
- this holds for development and evaluations, cannot simply evaluate on held-out data
- as with any AI deployment: a trial is best level of evidence
- other forms of off policy evaluation possible (especially attractive when you have RCTs that randomized the treatments) (Uehara et al. 2022)
opportunities:
- key pieces of puzzle for personalized treatment
- boom in causal inference interest, applications can improve
References
©Wouter van Amsterdam — WvanAmsterdam — wvanamsterdam.com/talks