An introduction to AI for biostatisticians
BMS-Aned seminar
2024-09-26

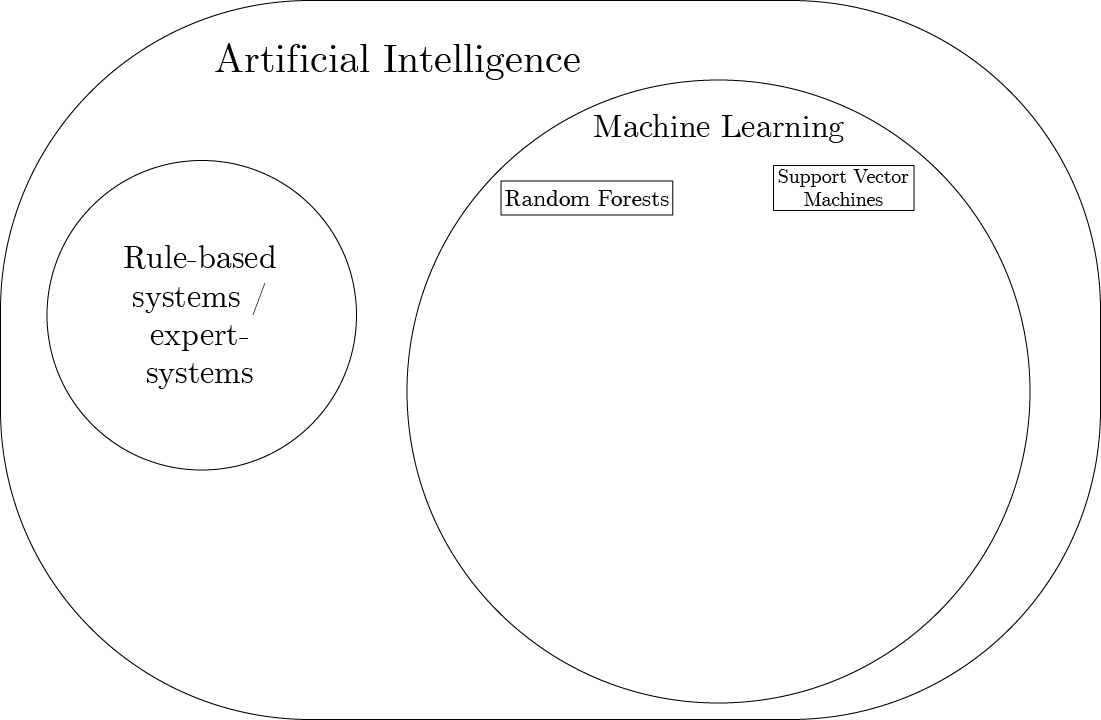
Rule-based systems are AI
- rule: all cows are animals
- observation: this is a cow \(\to\) it is an animal
- applications in health care:
- medication interaction checkers
- bedside patient monitors
- e.g. if heart rate > 100, alert nurse

Assume we have this data
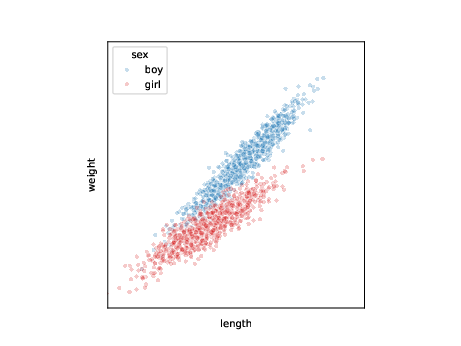
| i | length | weight | sex |
|---|---|---|---|
| 1 | 137 | 30 | boy |
| 2 | 122 | 24 | girl |
| 3 | 101 | 18 | girl |
| … | … | … | … |
We typically assume these data are (i.i.d.) samples from some unknown distribution \(p(l,w,s)\):
\[l_i,w_i,s_i \sim p(l,w,s)\]
ML tasks: generation
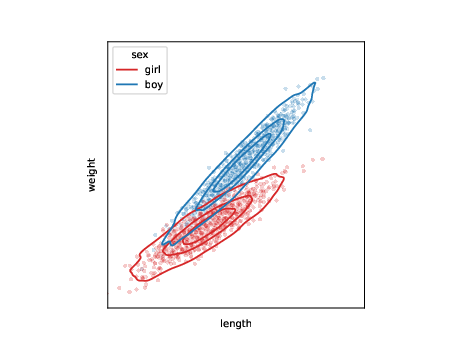
- formulate a model for joint distribution \(p_{\theta}\)
- statistics: ‘small’ model family
- machine learning: ‘large’ model family
- use samples to optimize \(\theta\)
- generate new samples
\[l_j,w_j,s_j \sim p_{\theta}(l,w,s)\]
| task | |
|---|---|
| generation | \(l_j,w_j,s_j \sim p_{\theta}(l,w,s)\) |
- application: simulate data for power calculations, privacy-preserving data sharing
ML tasks: conditional generation
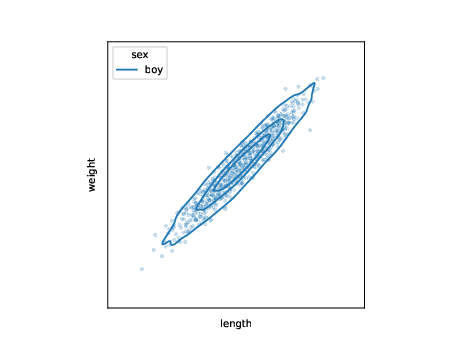
use samples to learn model for conditional distribution \(p\) \[ l_j,w_j \sim p_{\theta}(l,w|s=\text{boy}) \]
| task | |
|---|---|
| generation | \(l_j,w_j,s_j \sim p_{\theta}(l,w,s)\) |
| conditional generation | \(l_j,w_j \sim p_{\theta}(l,w|s=\text{boy})\) |
- application: imputation, question answering
ML tasks: conditional generation 2
use samples to learn model for conditional distribution \(p\) of one variable \[ s_j \sim p_{\theta}(s|l=l',w=w') \]
| task | |
|---|---|
| generation | \(l_j,w_j,s_j \sim p_{\theta}(l,w,s)\) |
| conditional generation | \(l_j,w_j \sim p_{\theta}(l,w|s=\text{boy})\) |
ML tasks: discrimination / classification
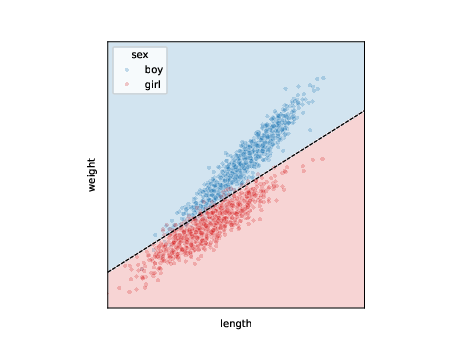
call this one variable outcome and - classify when majority of generated samples are of a certain class - or: have a model that outputs expected values \[ s_j = p_{\theta}(s|l=l',w=w') > 0.5 \]
| task | |
|---|---|
| generation | \(l_j,w_j,s_j \sim p_{\theta}(l,w,s)\) |
| conditional generation | \(l_j,w_j \sim p_{\theta}(l,w|s=\text{boy})\) |
| discrimination | \(p_{\theta}(s|l=l_i,w=w_i) > 0.5\) |
- application: prediction, diagnosis
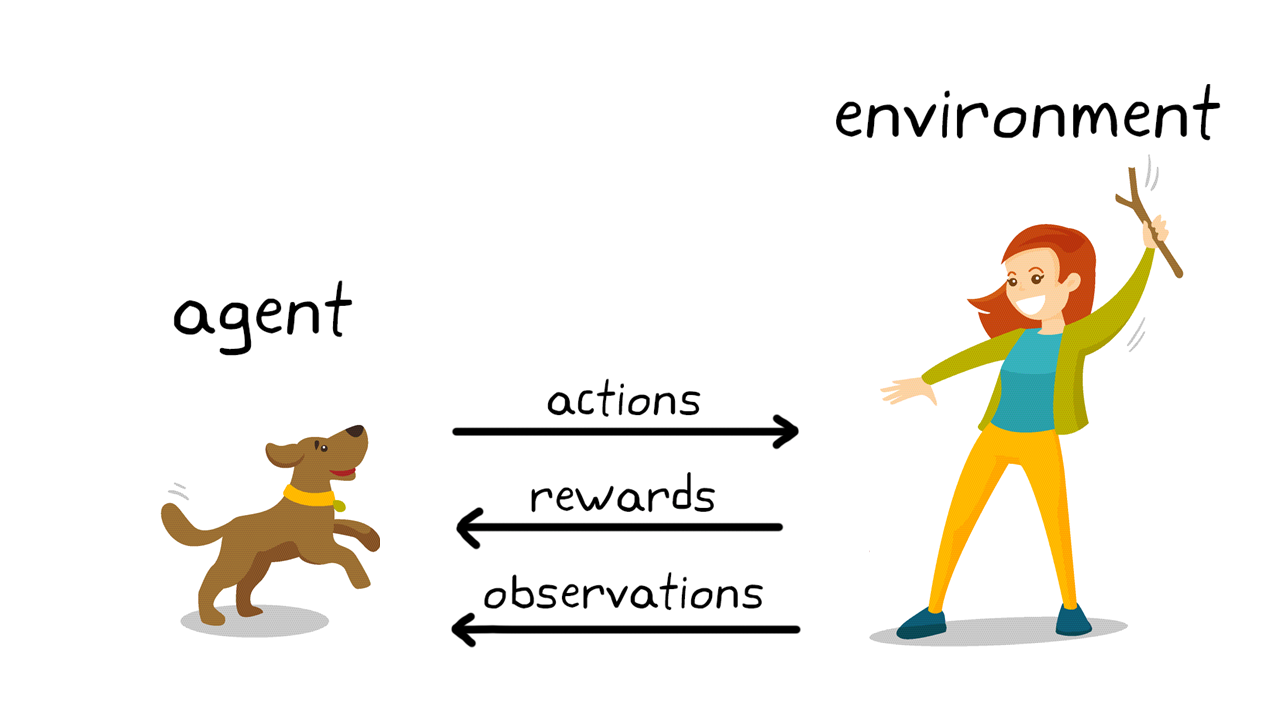
ML tasks: reinforcement learning
- e.g. computers playing games
- typically requires many experiments, maybe not too useful in health care

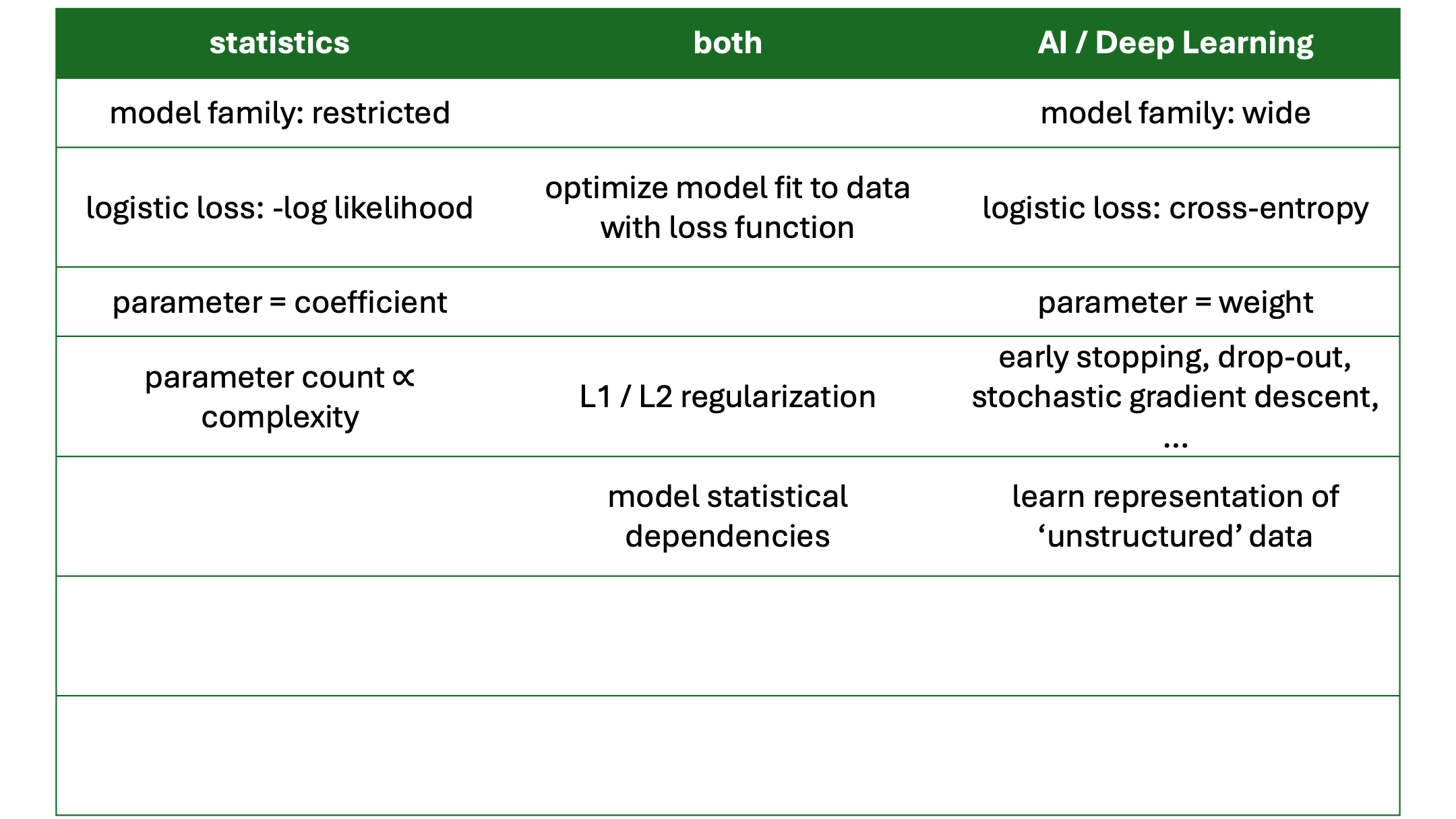
Neural Networks and Deep Learning
From Linear Regression …
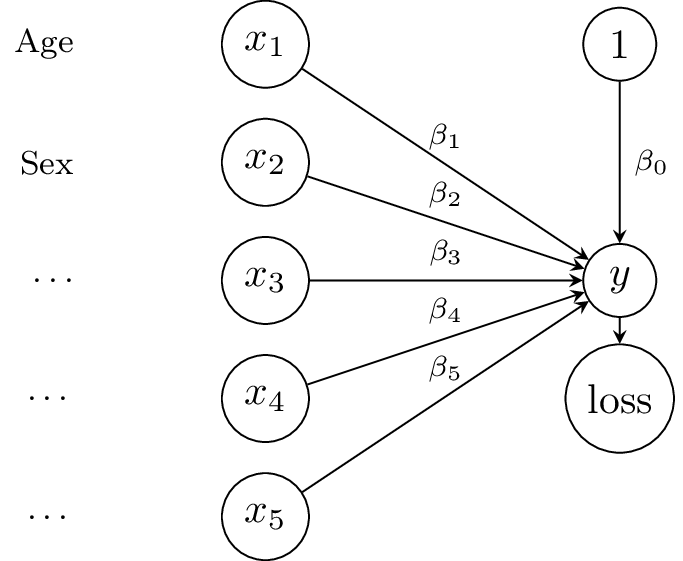
\[y = \sum_{i=0}^5 x_i \beta_i\]
- optimize \(\beta_i\) to minimize mean squared error, e.g. using second-order methods
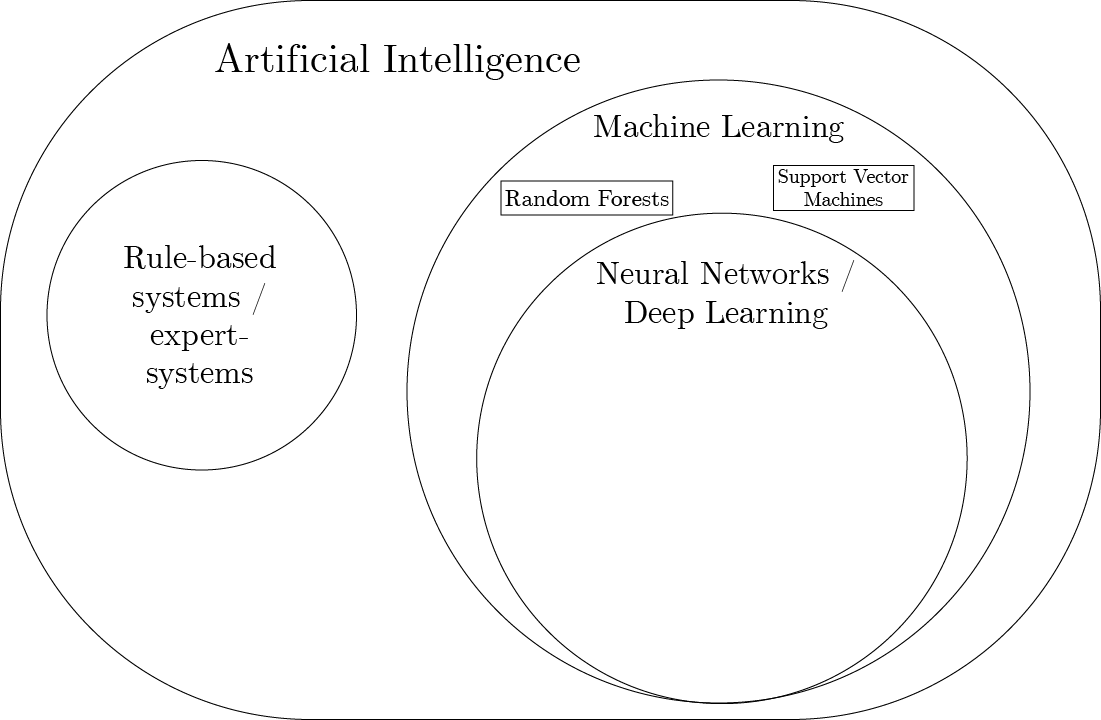
Neural Networks and Deep Learning
… to ‘Deep’ Learning
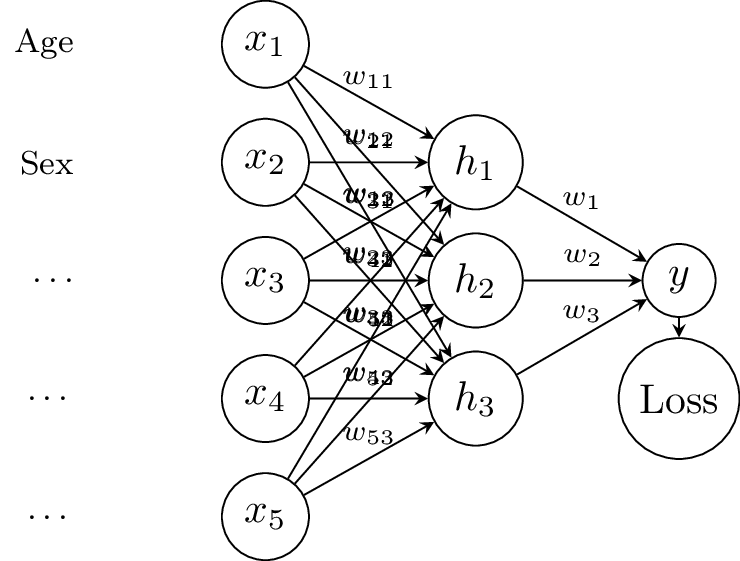
\[\begin{align} h_i &= w_{0i} + w_{1i} x_1 + \ldots \\ h_i &= g(h_i) \\ y &= \sum_{i=1}^3 h_i w_i \end{align}\]
- sticked \(h_i\) between input and output
- \(g\) is a non-linear function: each \(h_i\) is a non-linear transformation of the input
- renamed \(\beta_i\) (‘coefficients’) to \(w_{0i}\) and \(w_i\) (‘weights’)
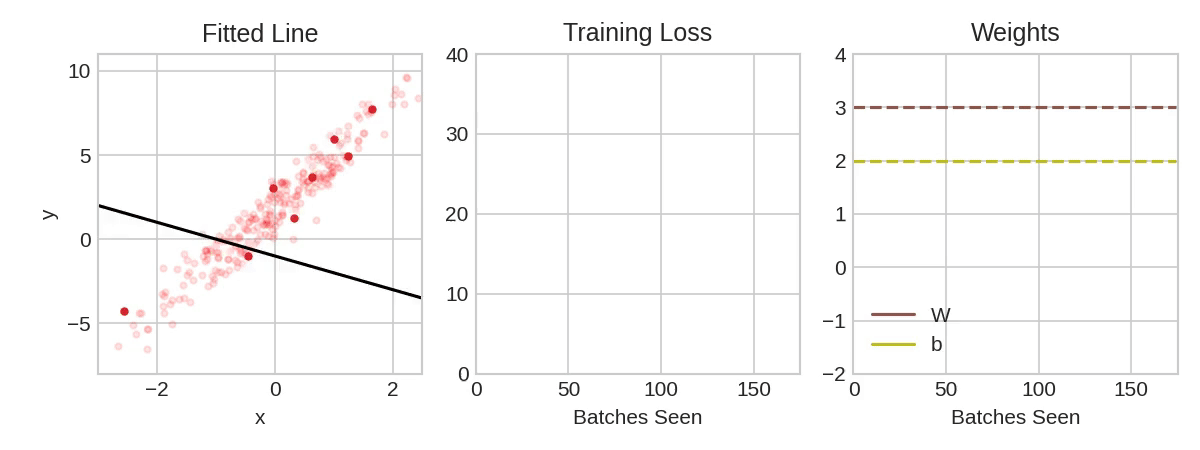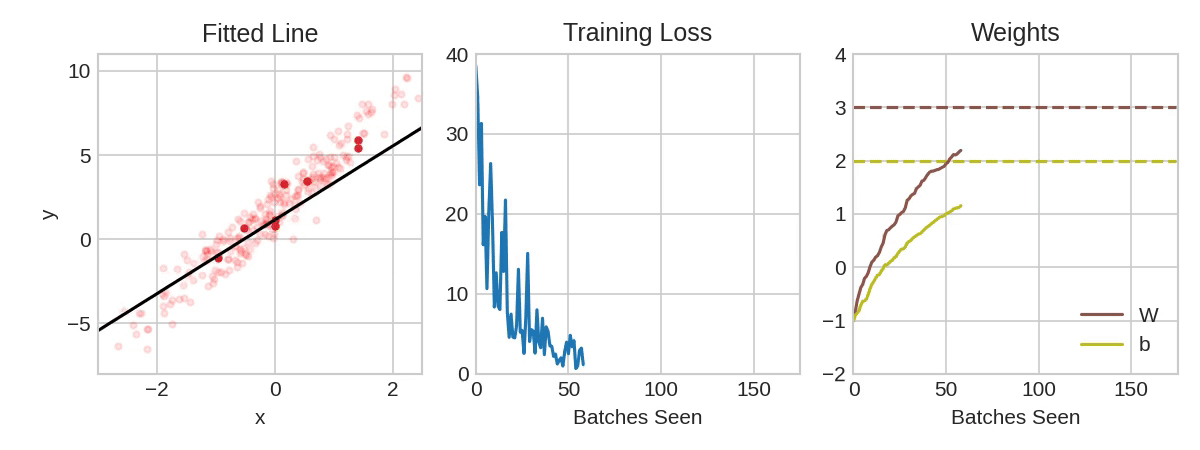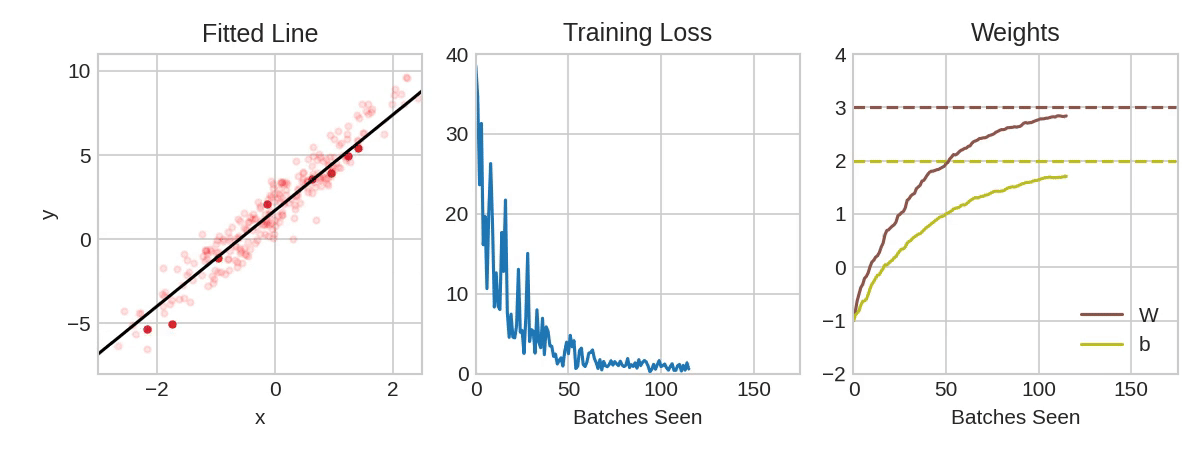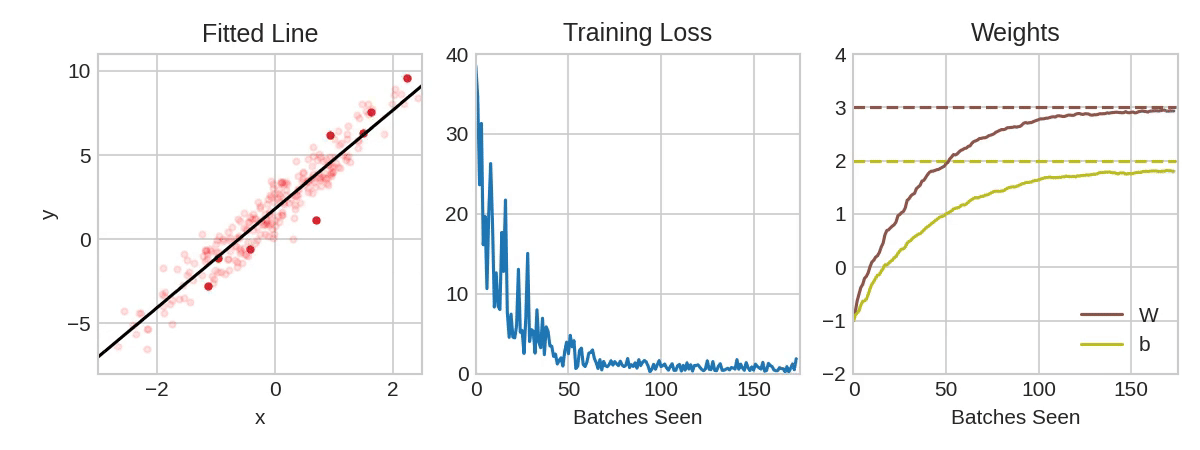
https://www.kaggle.com/code/ryanholbrook/stochastic-gradient-descent
Early stopping
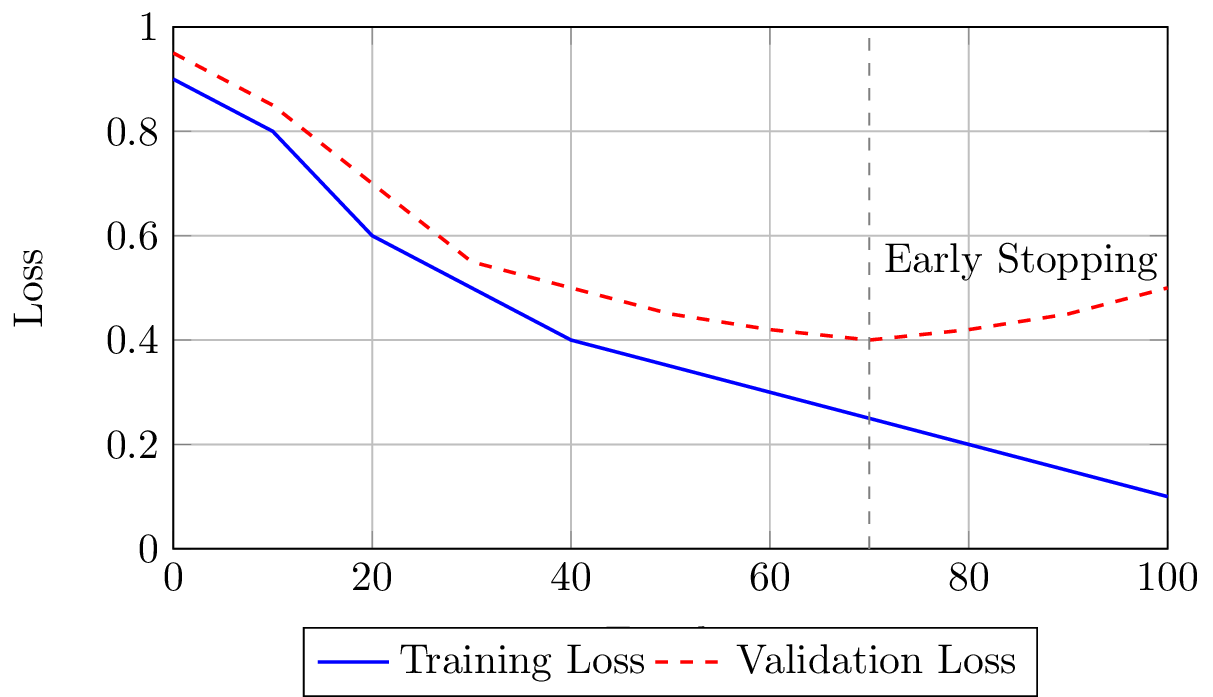
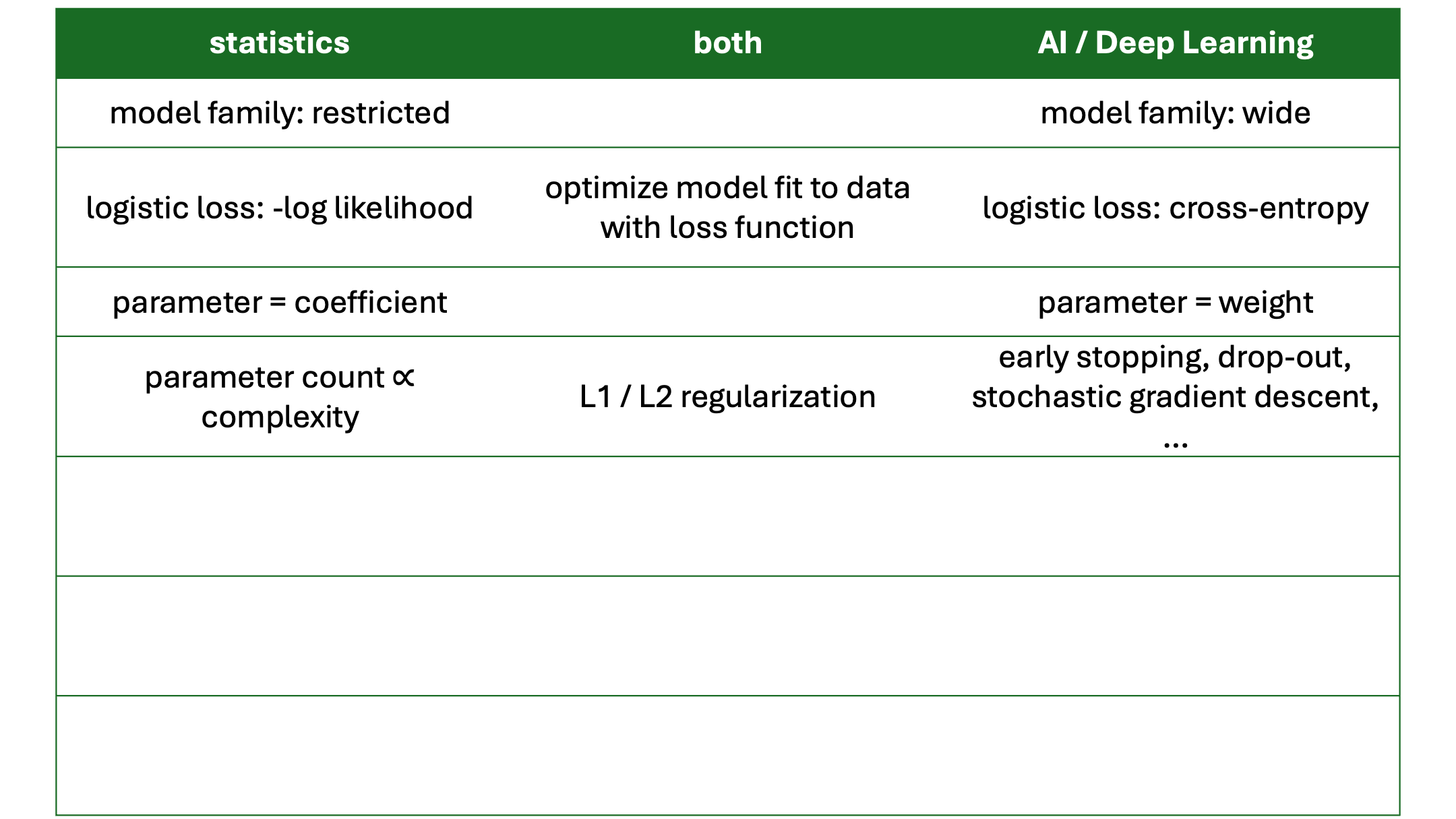
Convolutional Neural Networks
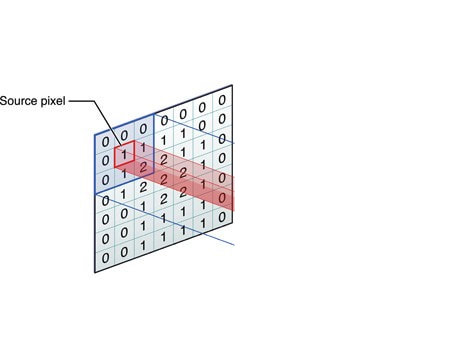
Image as matrix of pixel values
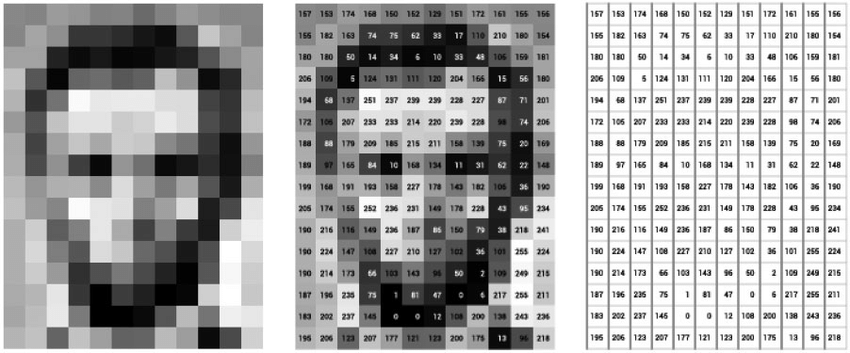
DOI: 10.1093/llc/fqy085
Convolutional Neural Networks
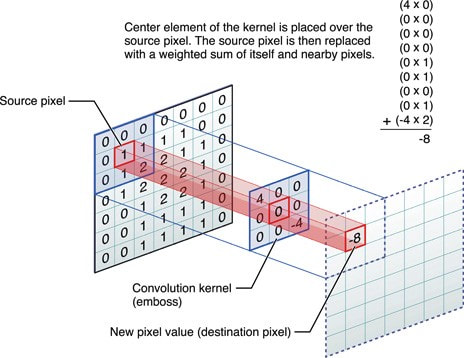
Convolution operation

Convolutional Neural Networks
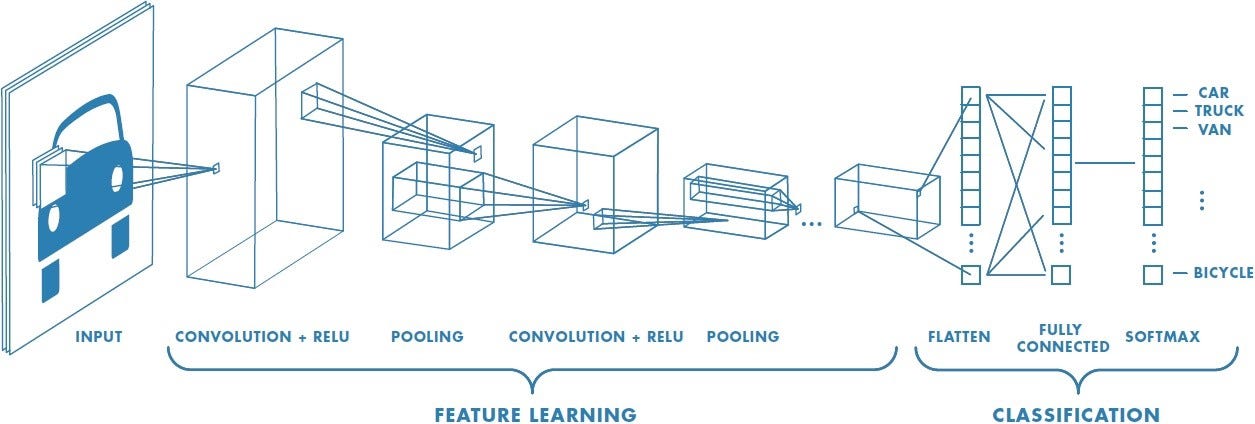
Images have local structure
Convolutional Neural Networks
CNNs build hierarchical features with local invariant structure

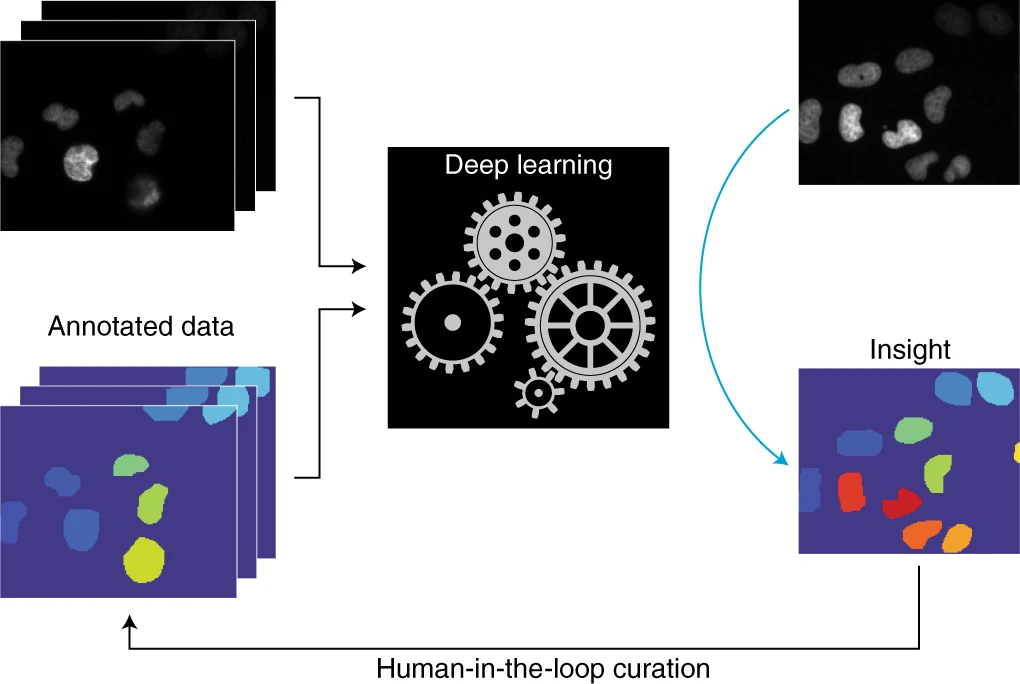
deep learning for cell counting (Moen et al. 2019)
Neural Networks for Sequence data
- many data are sequences: text, time series, DNA
- specific architectures for sequence data
- Recurrent Neural Networks (RNNs)
- natural language processing: Transformers (Vaswani et al. 2023)
![]()
chatGPT: a stochastic auto-regressive conditional generator with a chatbot interface
- trained by predicting the next <…> (word)
- in a large corpus of text
- with a large model
- for a long time on expensive hardware
- post-processed to optimize user experience (remove offensive language, etc.)
- present test-user with two generated answers, ask which is better
- if user picks one, use that as training signal

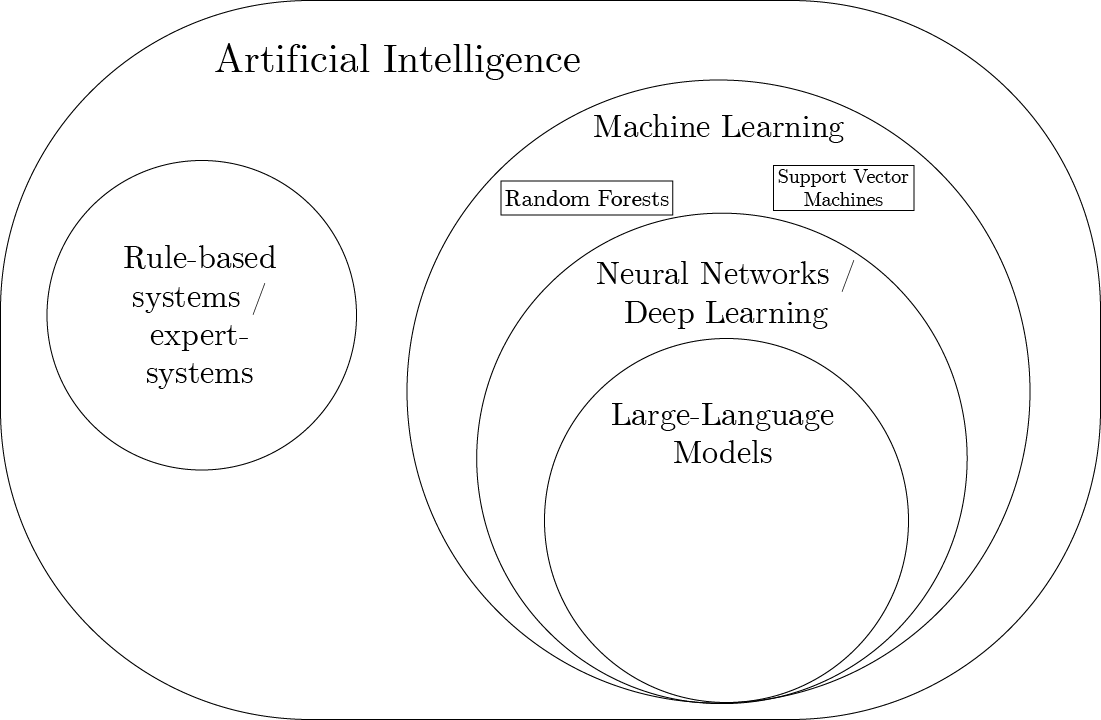
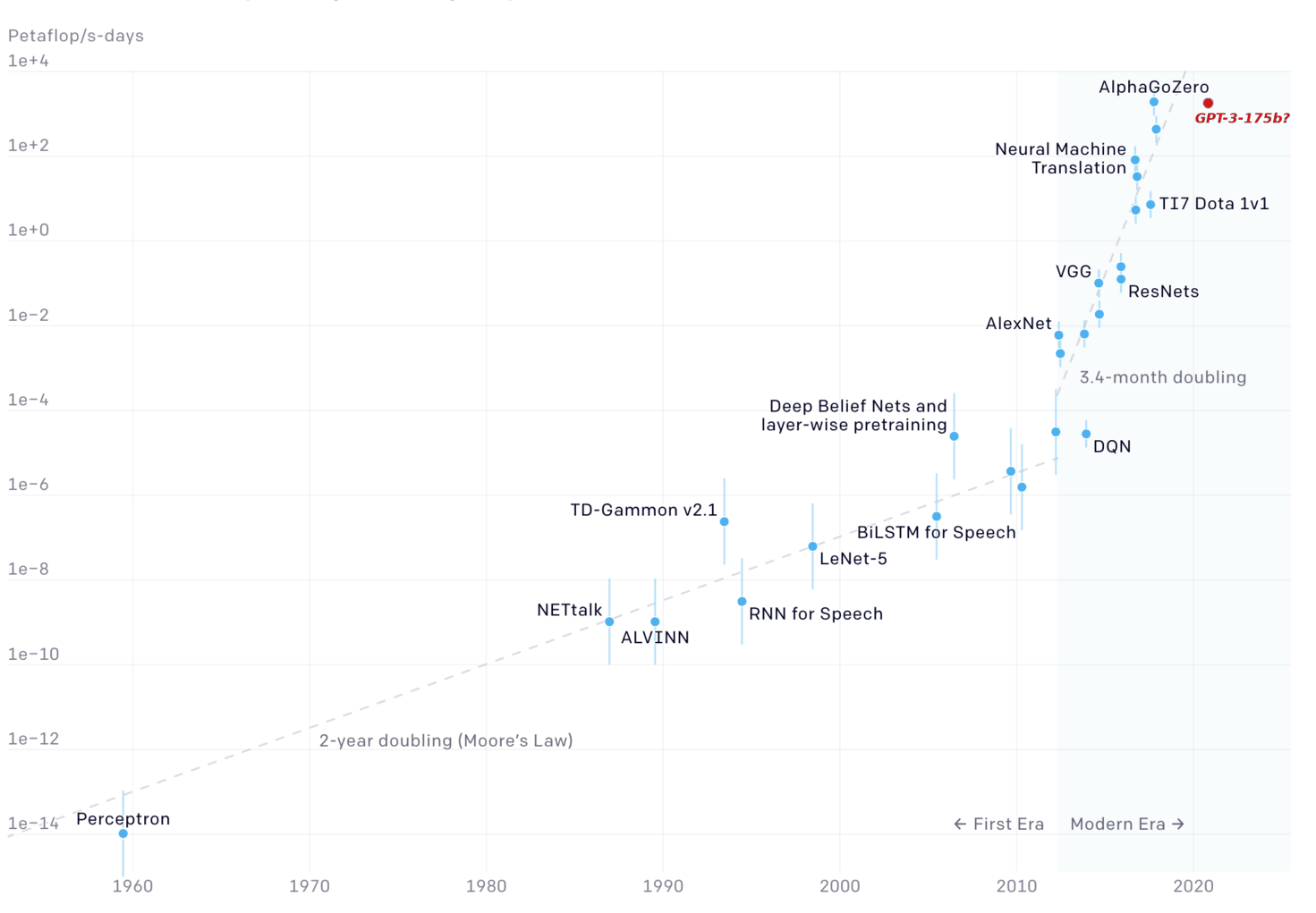
GPT-4 scale (underlying current ChatGPT)



For complex tasks, neural networks keep getting better with:
- more compute resources
- bigger data
- bigger models (enabled by data and compute)

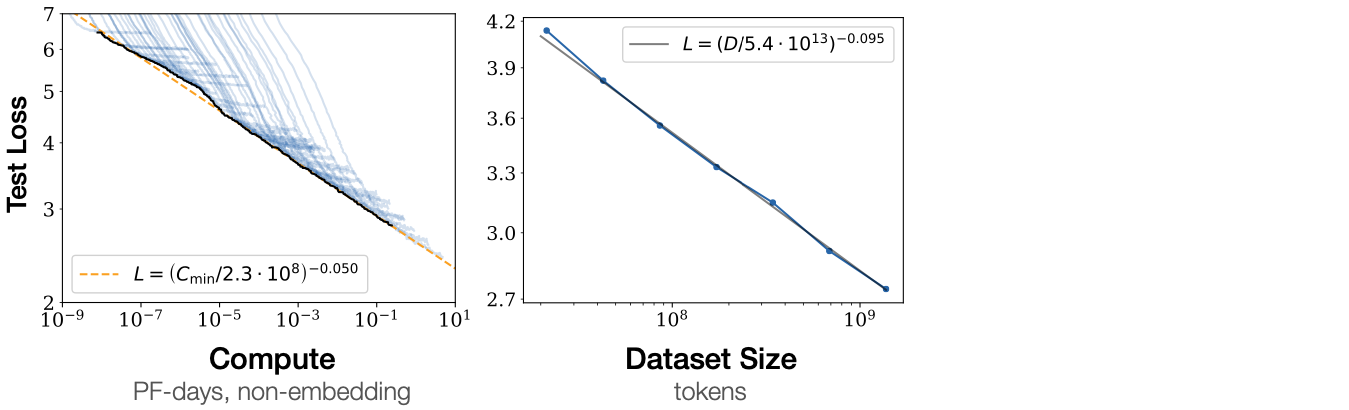
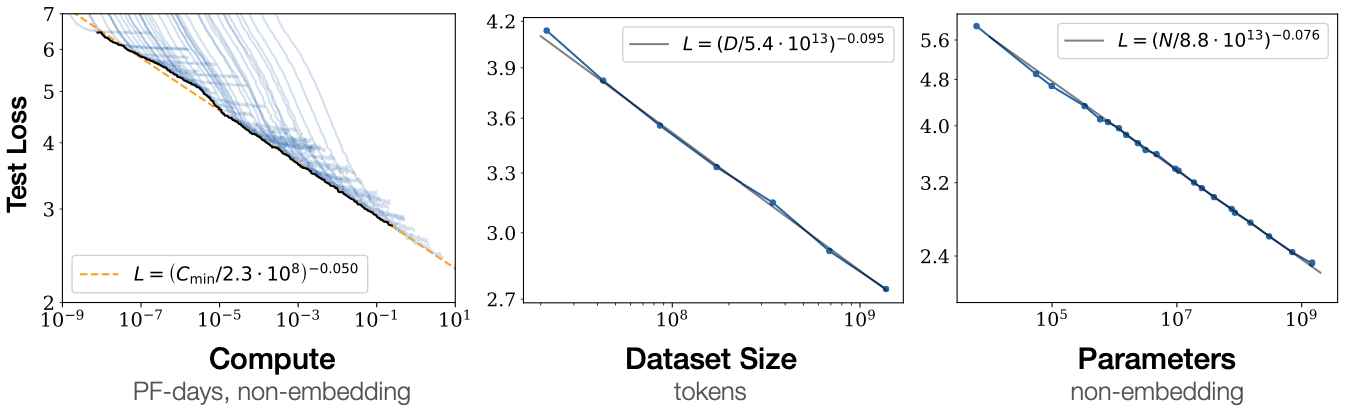
scaling over time
rule-based AI versus chatGPT
- rule-based AI:
- explicit rules
- no learning, restricted to rules
- dependable, verifiable
- LLMs:
- no explicit rules
- learned from data, can ‘learn’ almost anything
- not dependable, not verifiable
- produces text that may have appeared in training data (‘the internet’)