Uses and pitfalls with AI for decision support - harmful self-fulfilling prophecies
WEON masterclass 2024 - AI-based prediction models in healthcare: from development to implementation
2024-05-30
The in-between: using prediction models for (medical) decision making
- prognosis (e.g. survival given medical image)


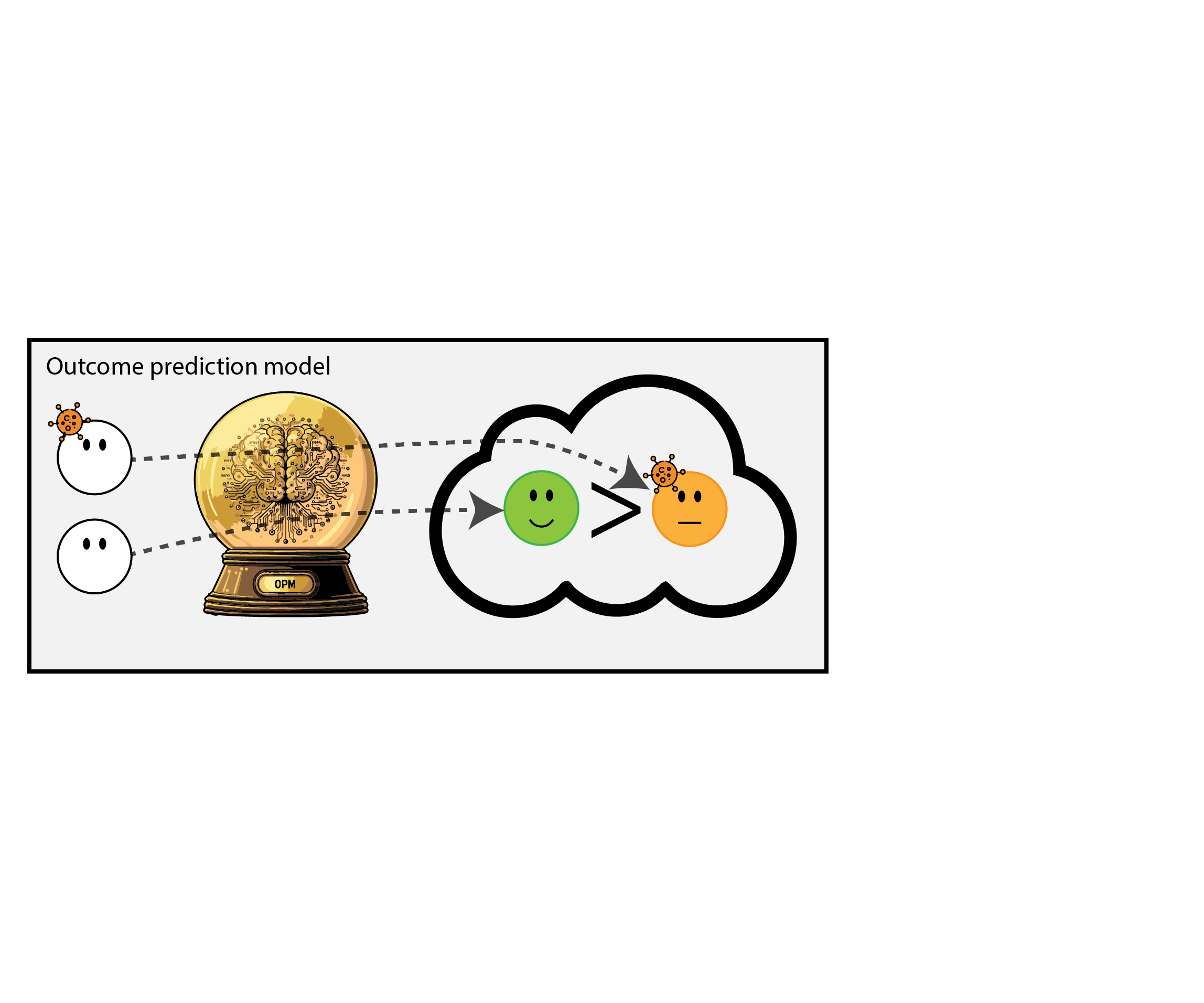
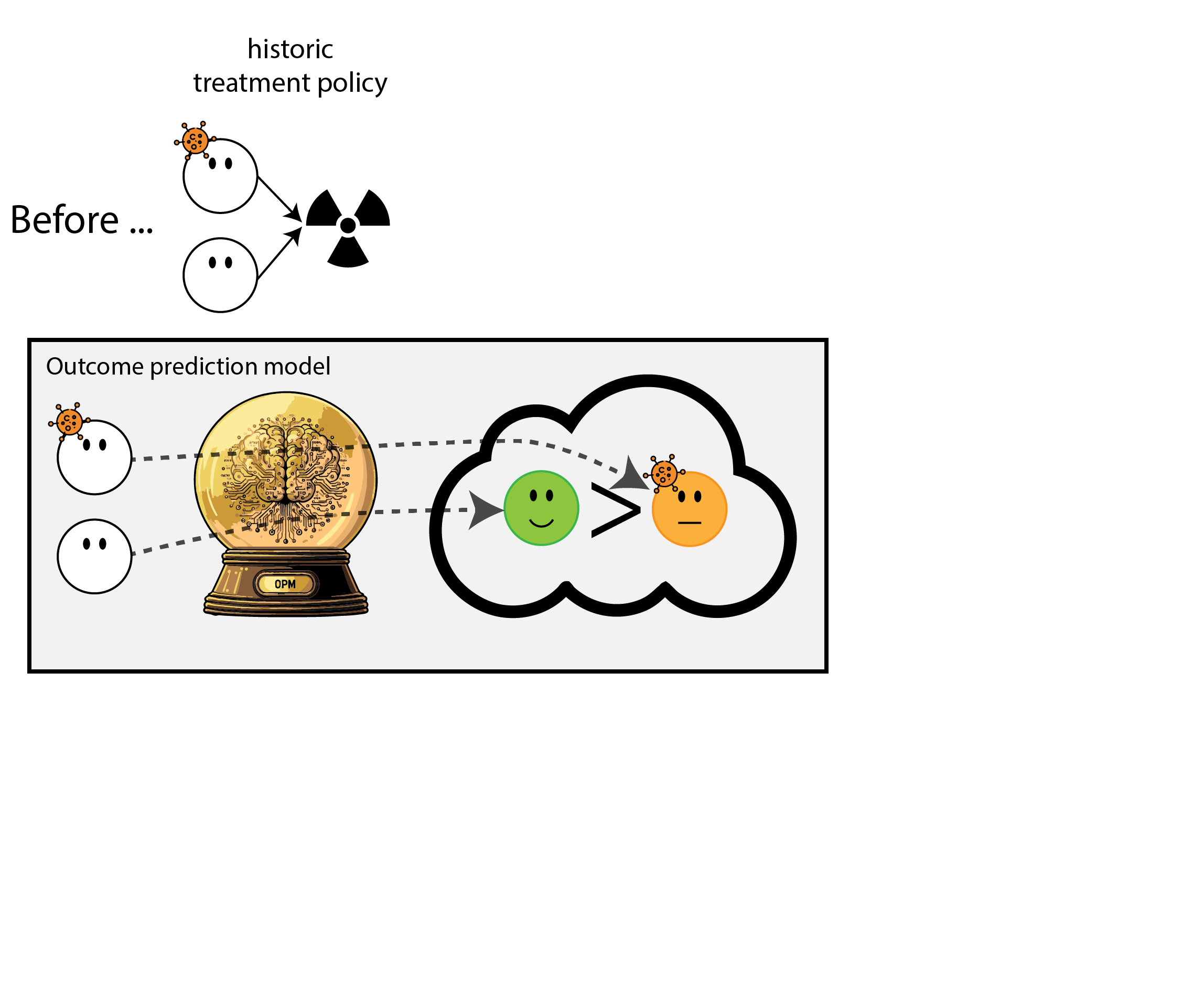
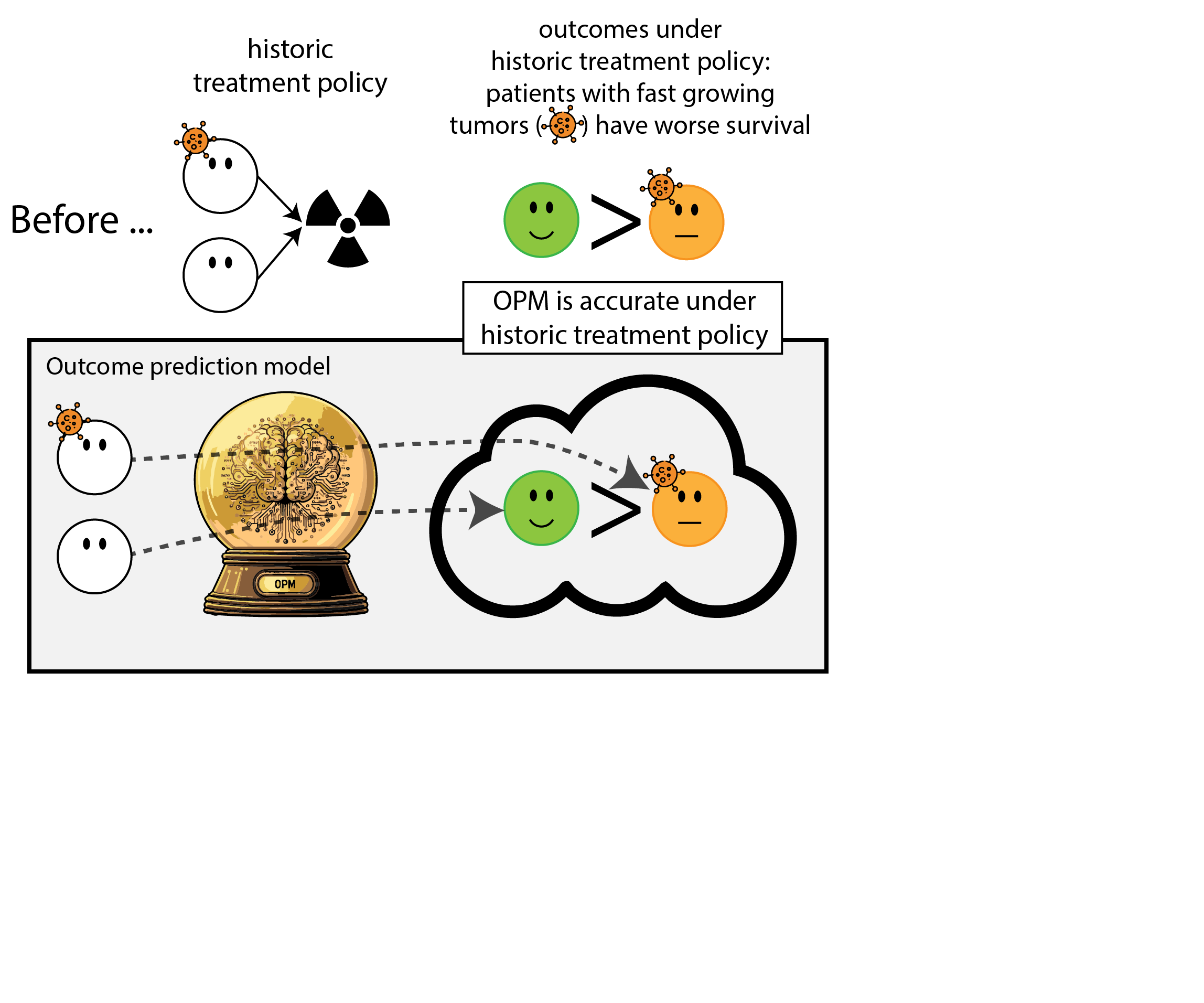
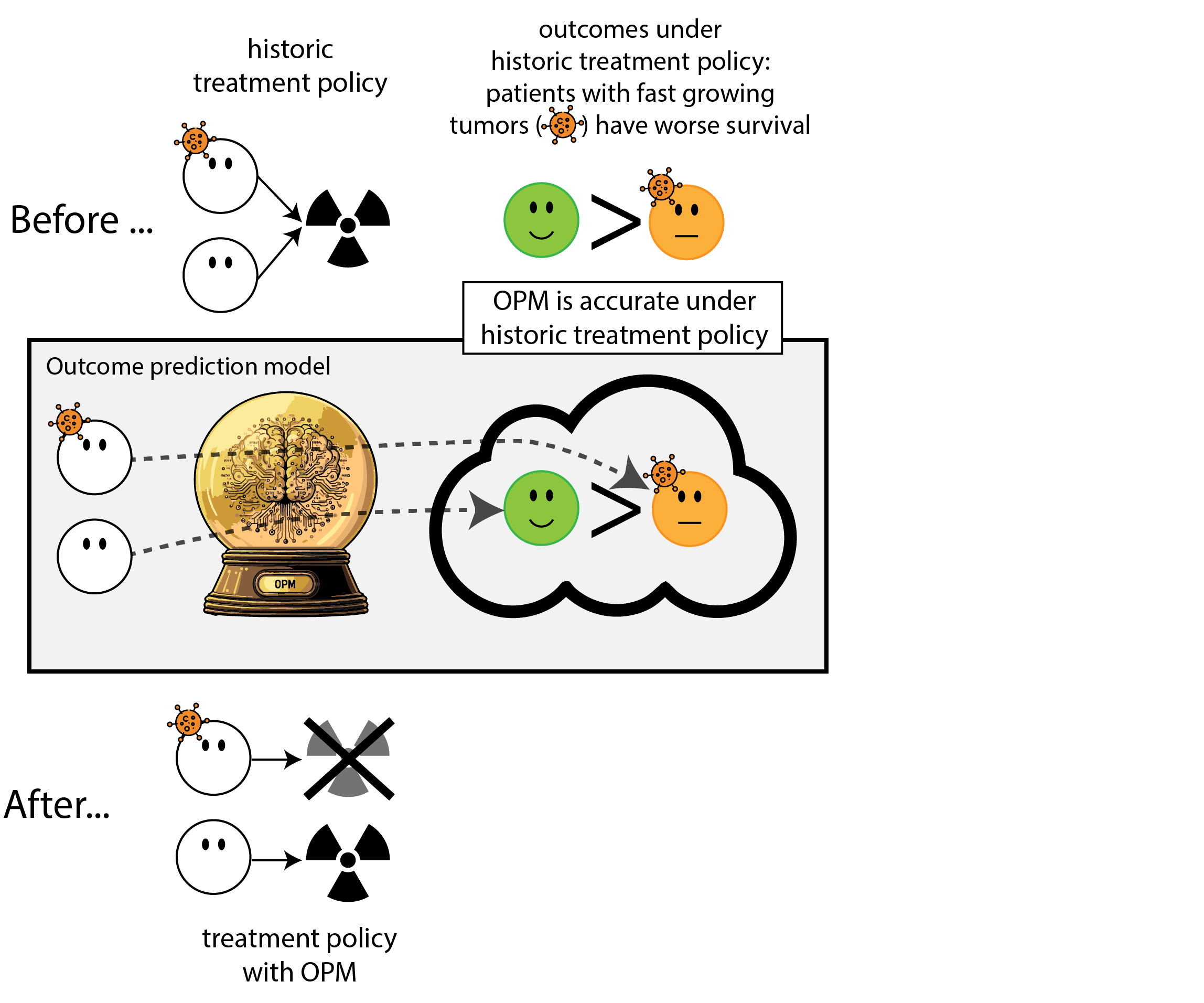
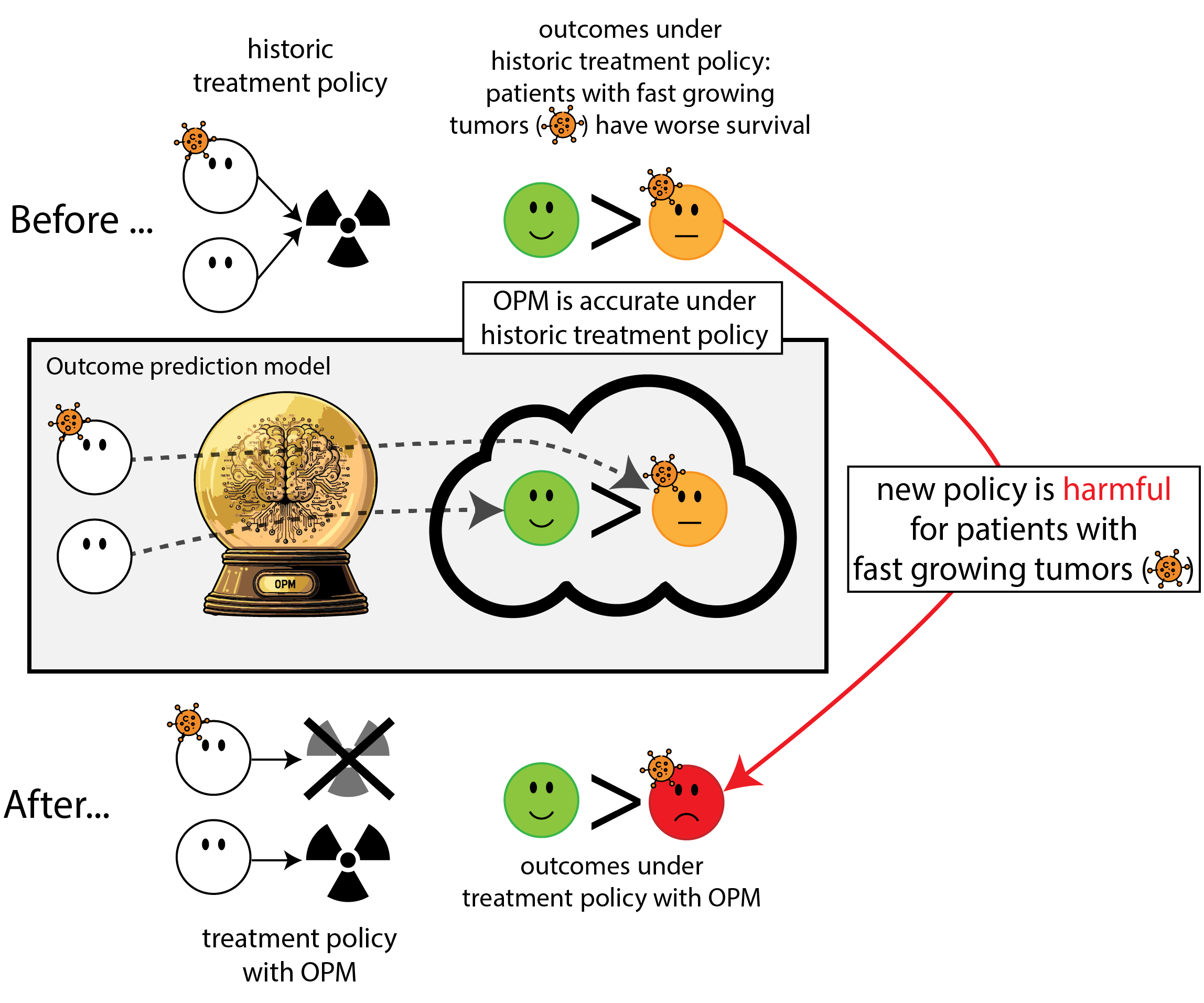
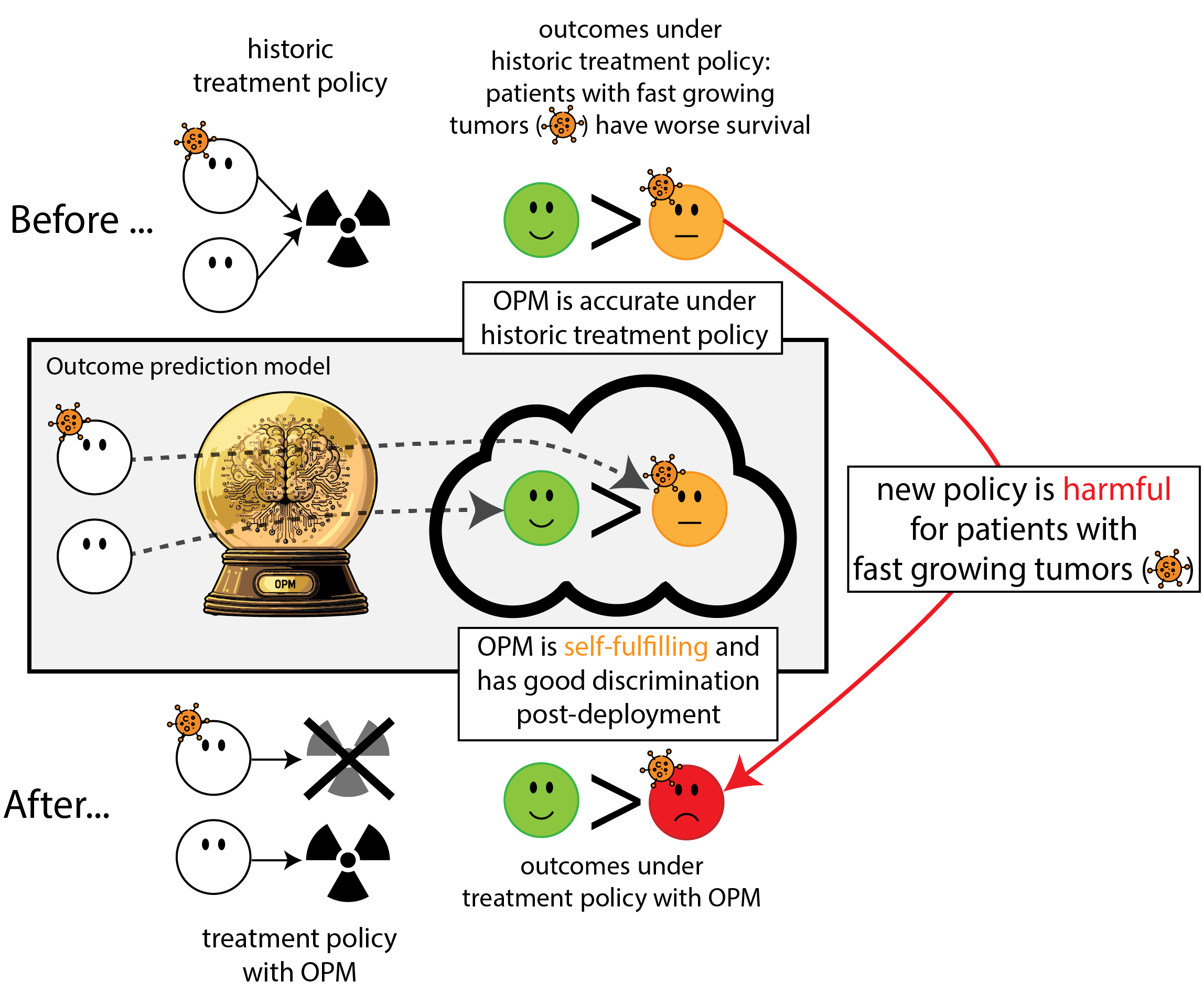
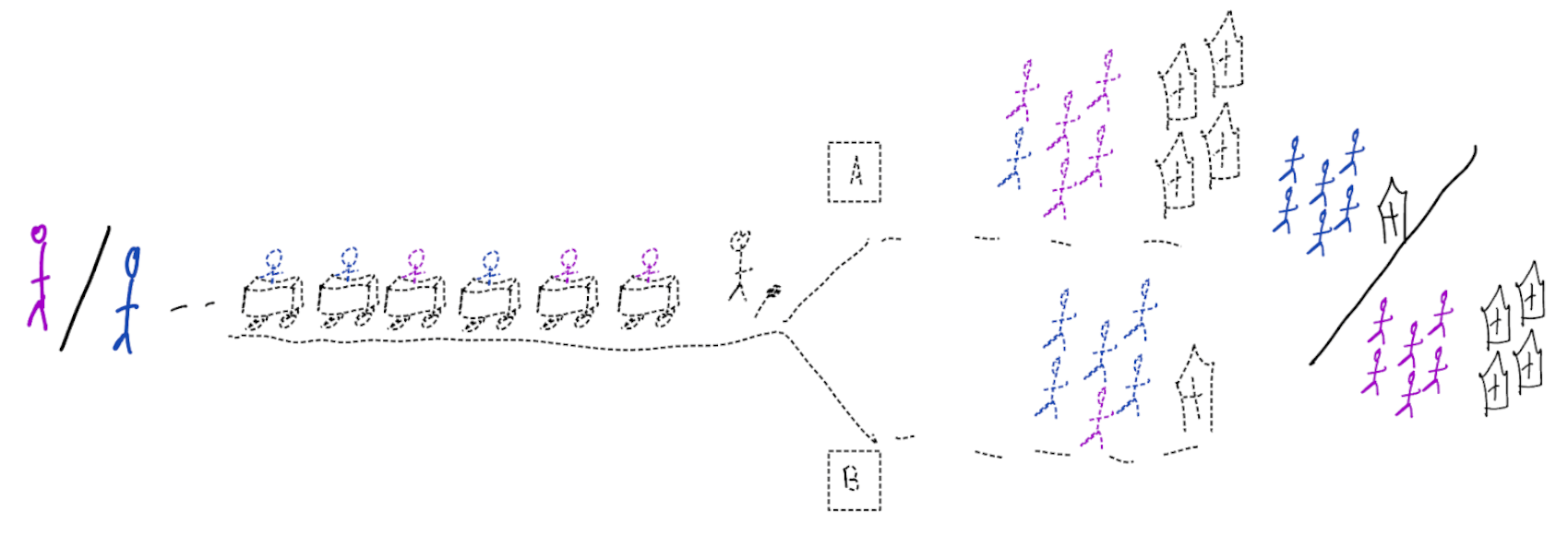
Building models for decision support without regards for the historic treatment policy is a bad idea
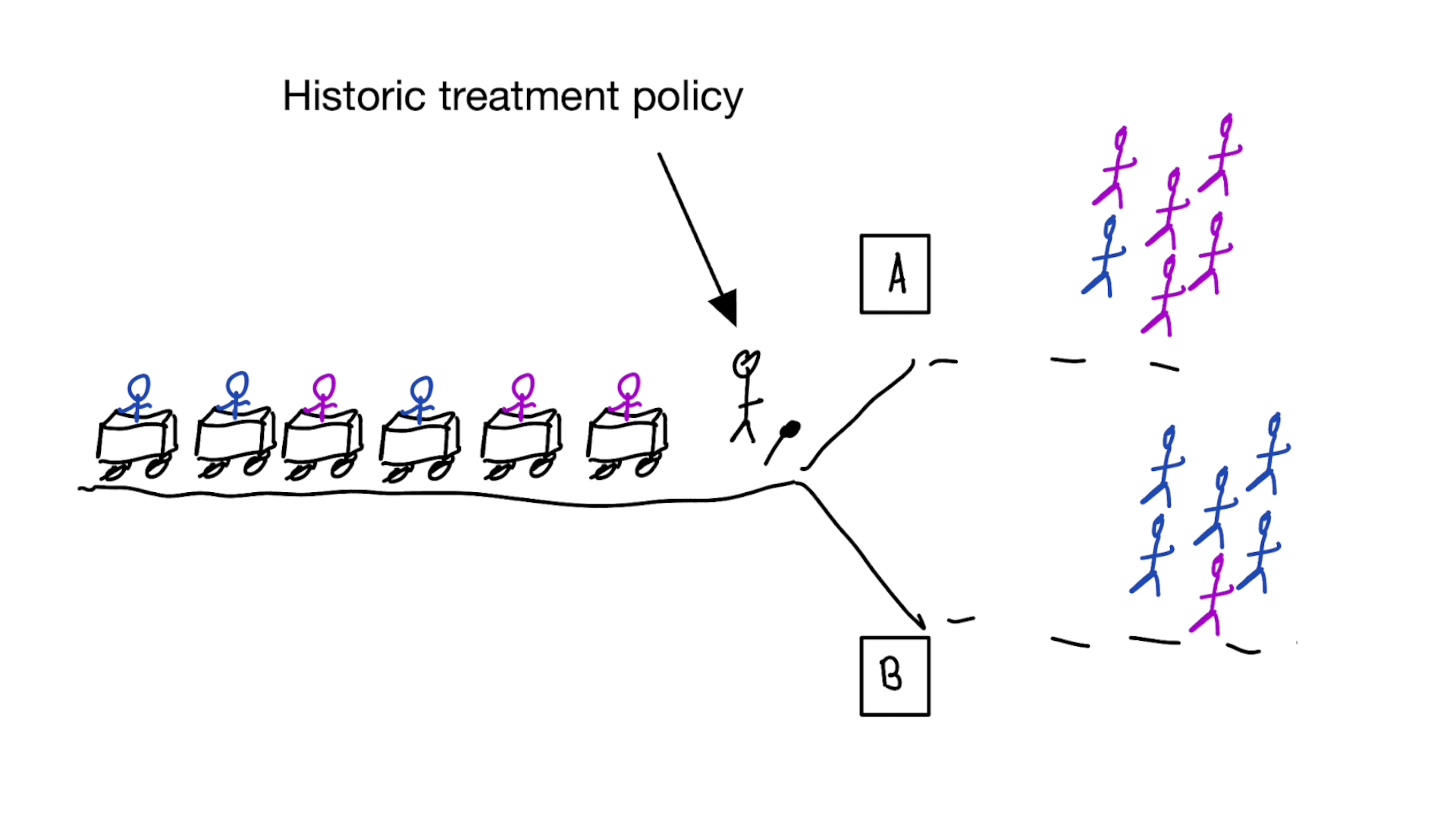
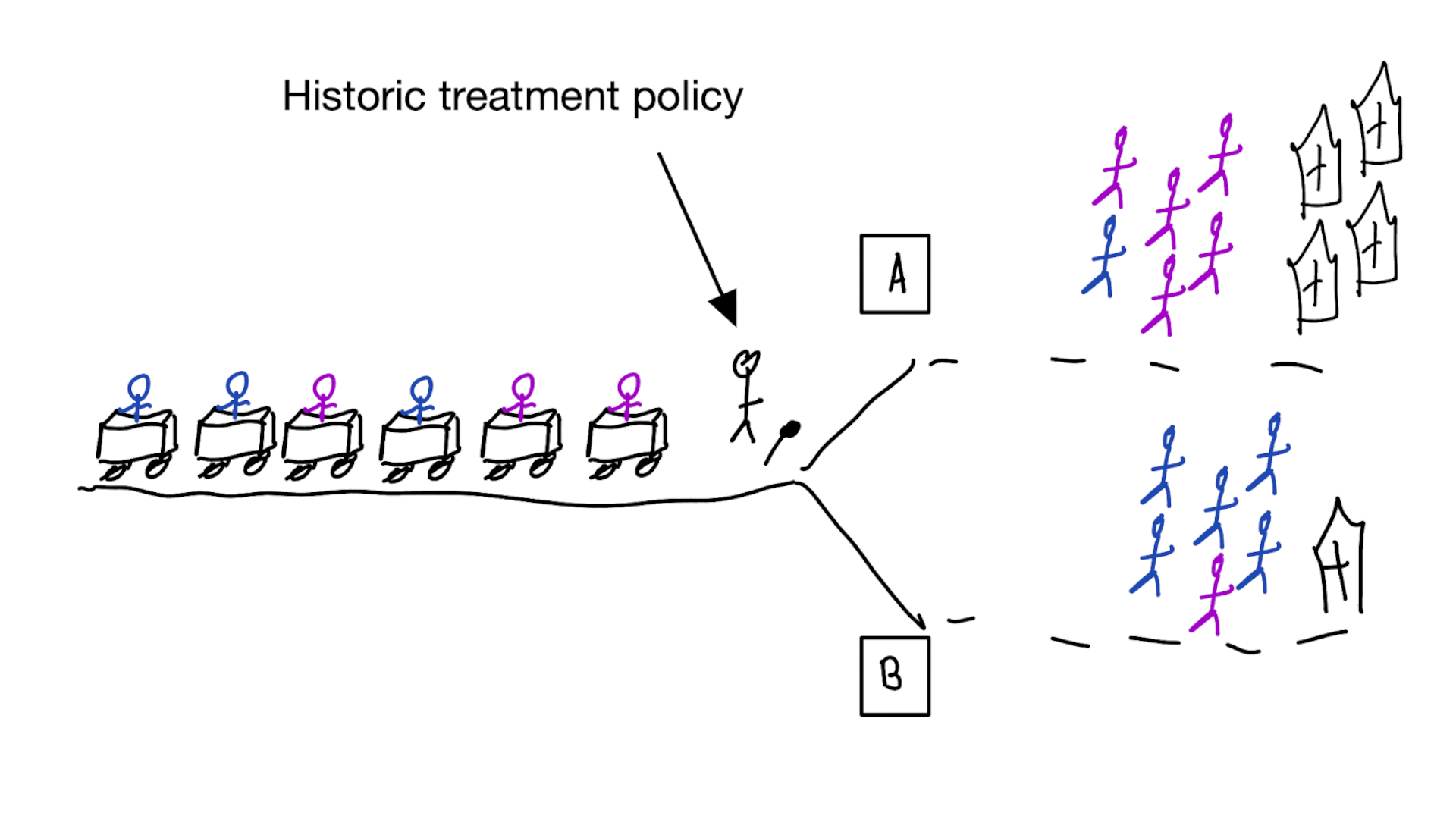
Treatment-naive prediction models
\[\begin{align} E[Y|X] \class{fragment}{= E[E_{t~\sim \pi_0(X)}[Y|X,t]]} \end{align}\]
Prediction modeling is very popular in medical research

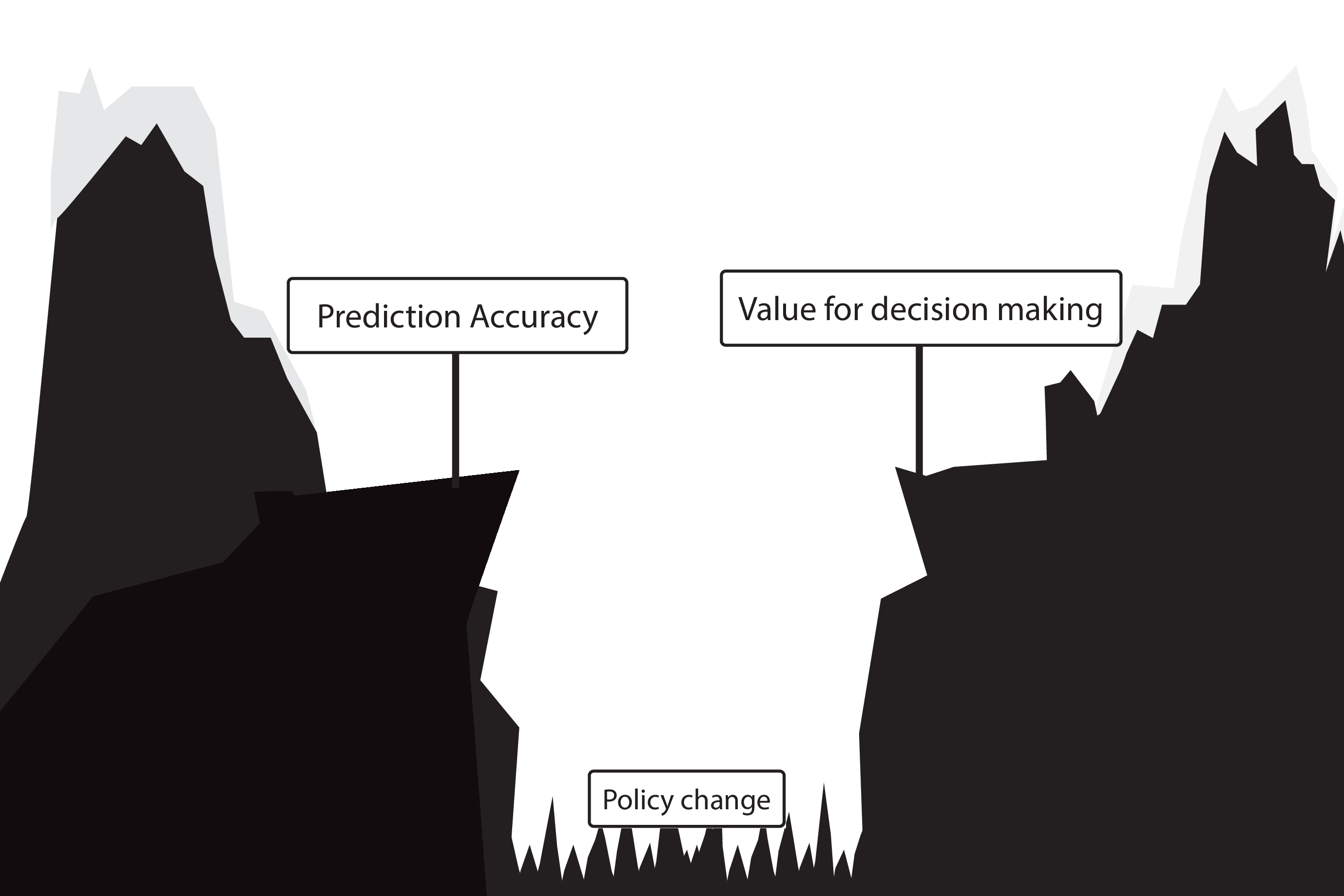
Recommended validation practices and reporting guidelines do not protect against harm
because they do not evaluate the policy change


Bigger data does not protect against harmful prediction models
More flexible models do not protect against harmful prediction models

Gap between prediction accuracy and value for decision making
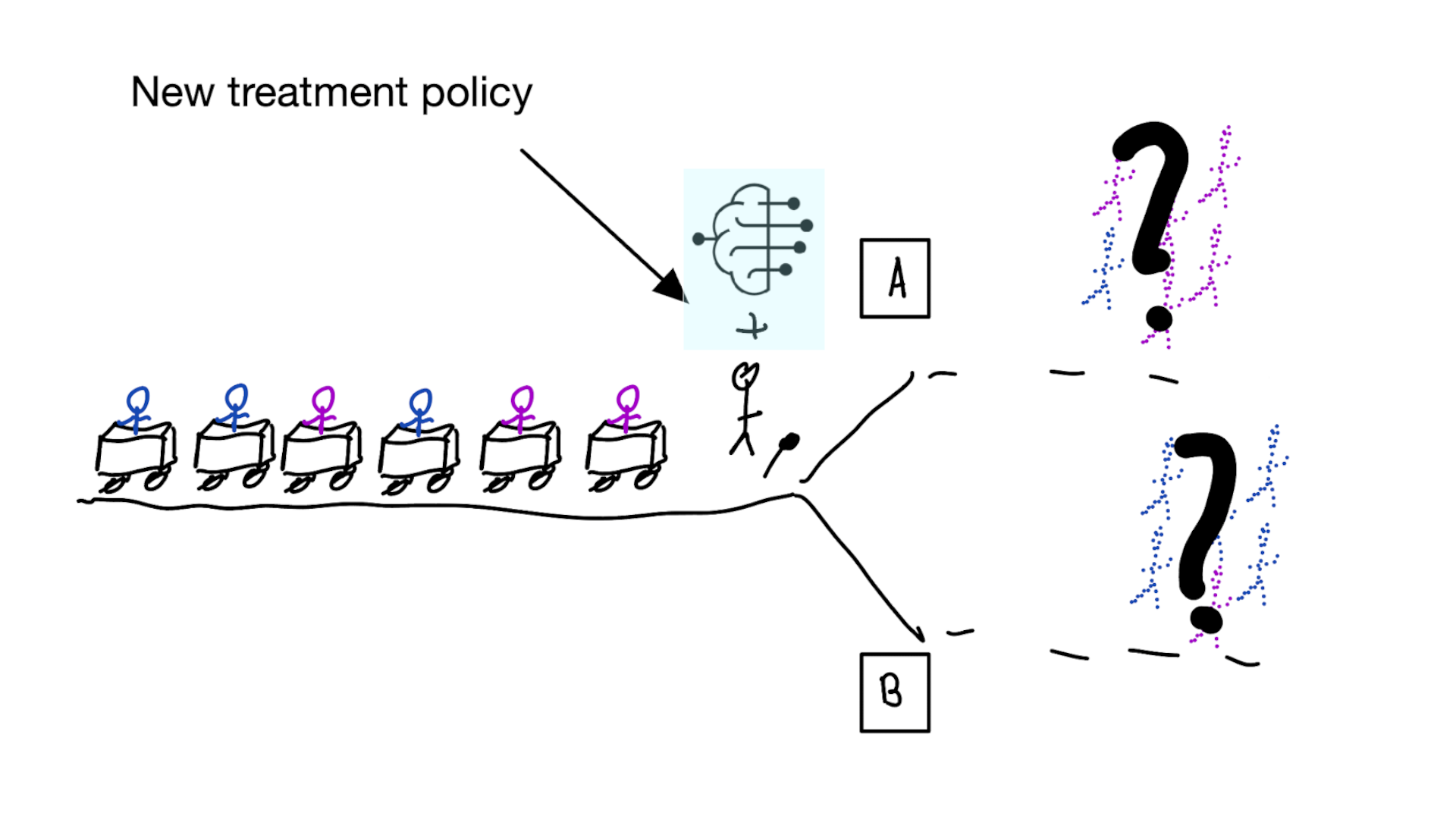
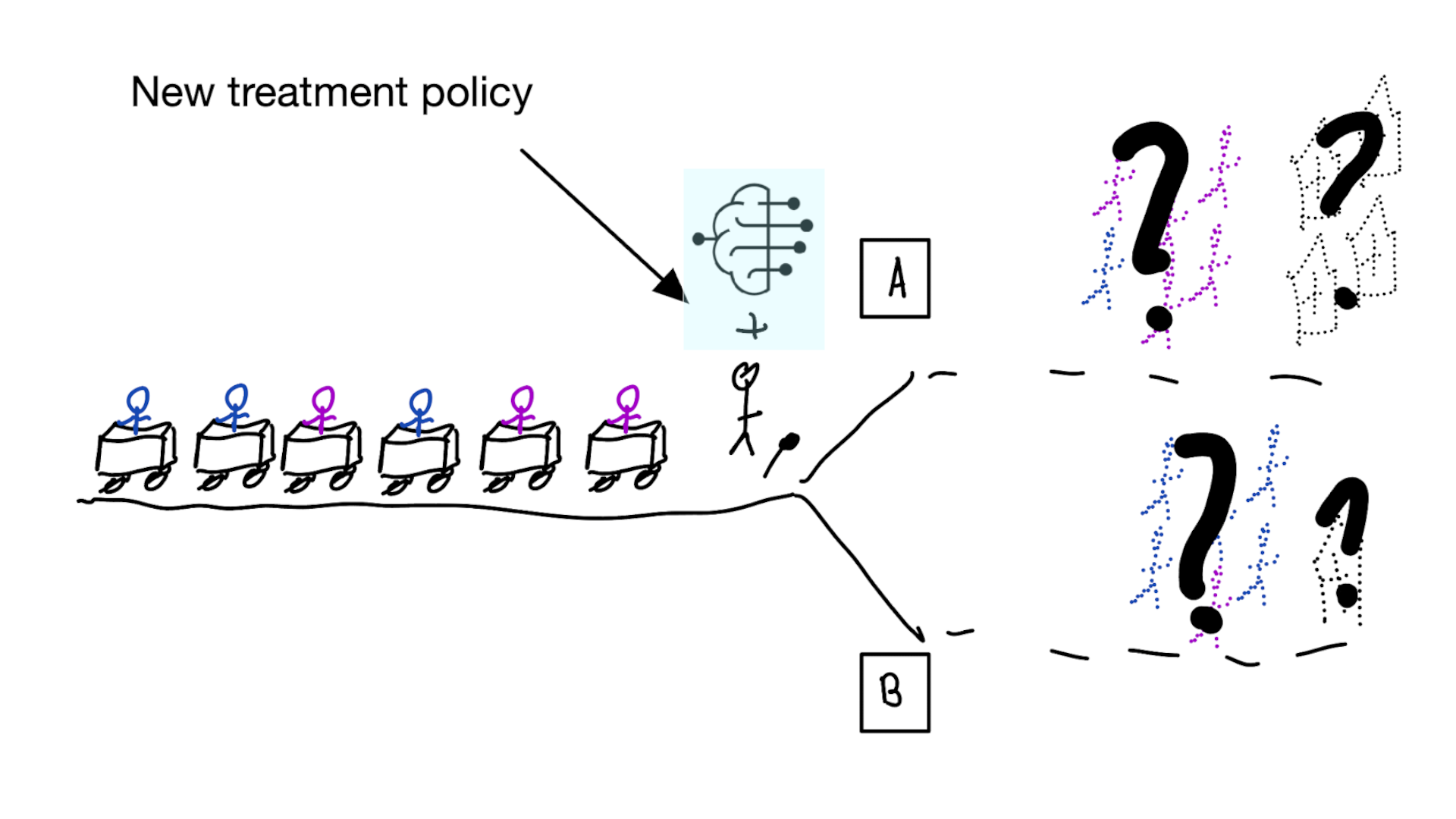
Deploying a model is an intervention that changes the way treatment decisions are made
using treatment naive prediction models for decision support
prediction-under-intervention

Take-aways
- when developing or evaluating (AI) prediction models for medical decisions, think about
- what is the effect of using this model on medical decisions?
- what is the effect of this policy change on patient outcomes?
- deploying models for decision support is an intervention and should be evaluated as such
- prediction-under-intervention models have a foreseeable effect on patient oucomes when used for decision making

From algorithms to action: improving patient care requires causality (amsterdamAlgorithmsActionImproving2024?)

When accurate prediction models yield harmful sel-fulfilling prophecies (vanamsterdamWhenAccuratePrediction2024a?)
New summerschool: Introduction to Causal Inference and Causal Data Science
Learn more about causal data science
- Dates: 5 Aug. - 9 Aug. 2024
- Location: Utrecht
- Instructors:
- Oisin Ryan
- Bas Penning-de Vries
- Wouter van Amsterdam
- Sign up still possible

