
Causality and prediction: developing and validating models for decision making
Causal Data Science Special Interest Group - Utrecht
2024-05-16
Causal inference
\(y^0:=\) imaginative outcome if I don’t treat the patient
\(y^1:=\) imaginative outcome if I do treat

\[\begin{align} y^0 &= \mu_0 + \epsilon, \quad \epsilon \overset{\mathrm{iid}}{\sim} N(0,\sigma) \to &P(Y=y|\text{do}(T=0))\\ y^1 &= \mu_1 + \epsilon, \quad \epsilon \overset{\mathrm{iid}}{\sim} N(0,\sigma) \to &P(Y=y|\text{do}(T=1)) \end{align}\]
\[\begin{align} \text{treatment effect} &:= E[y^1] - E[y^0] = \mu_1 - \mu_0 \\ &:= E[Y|\text{do}(T=1)] - E[Y|\text{do}(T=0)] \end{align}\]
The in-between: using prediction models for (medical) decision making


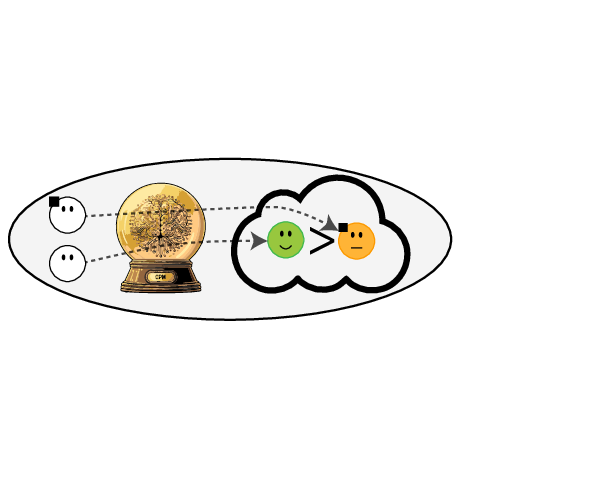
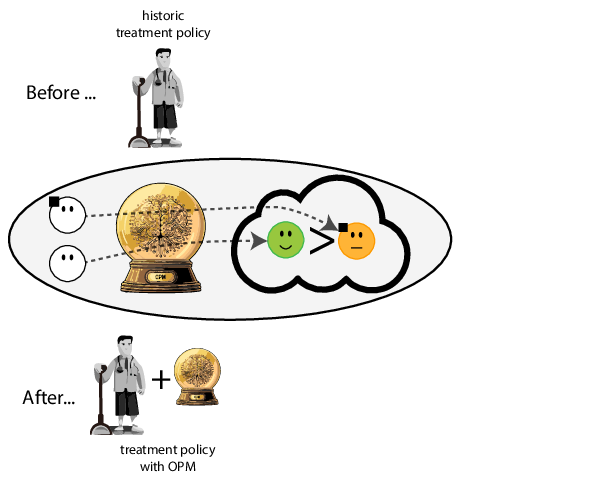
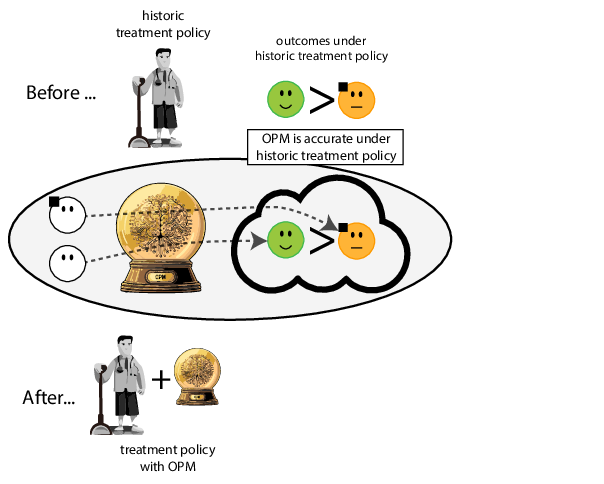
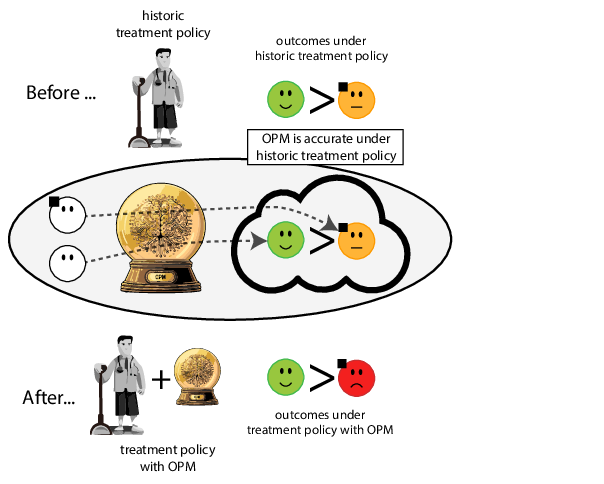
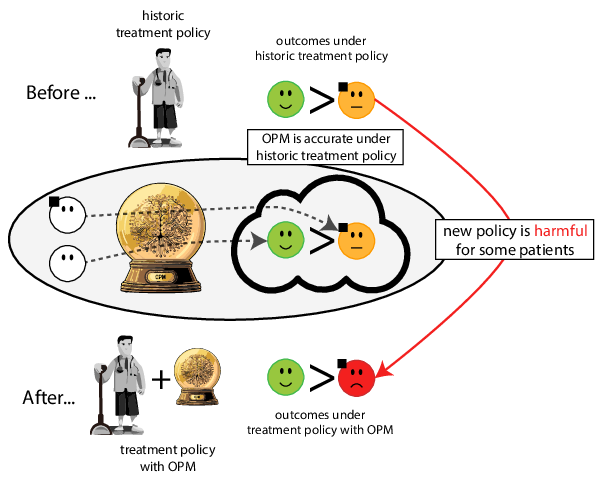
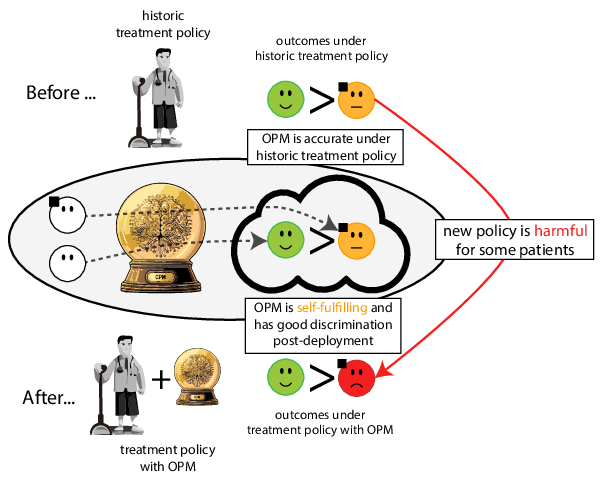
Prediction modeling is very popular in medical research

Tip
building models for decision support without regards for the historic treatment policy is a bad idea
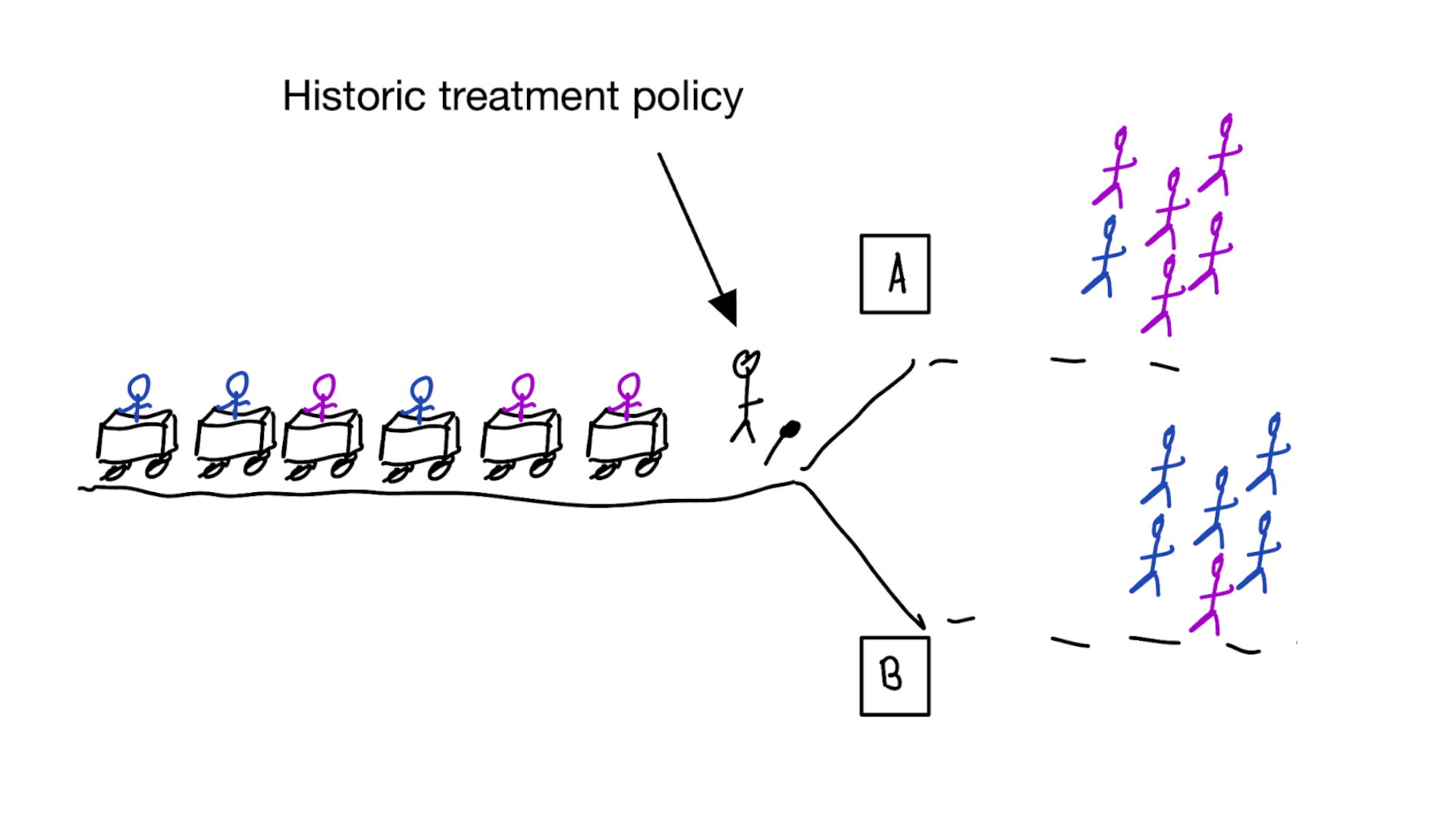
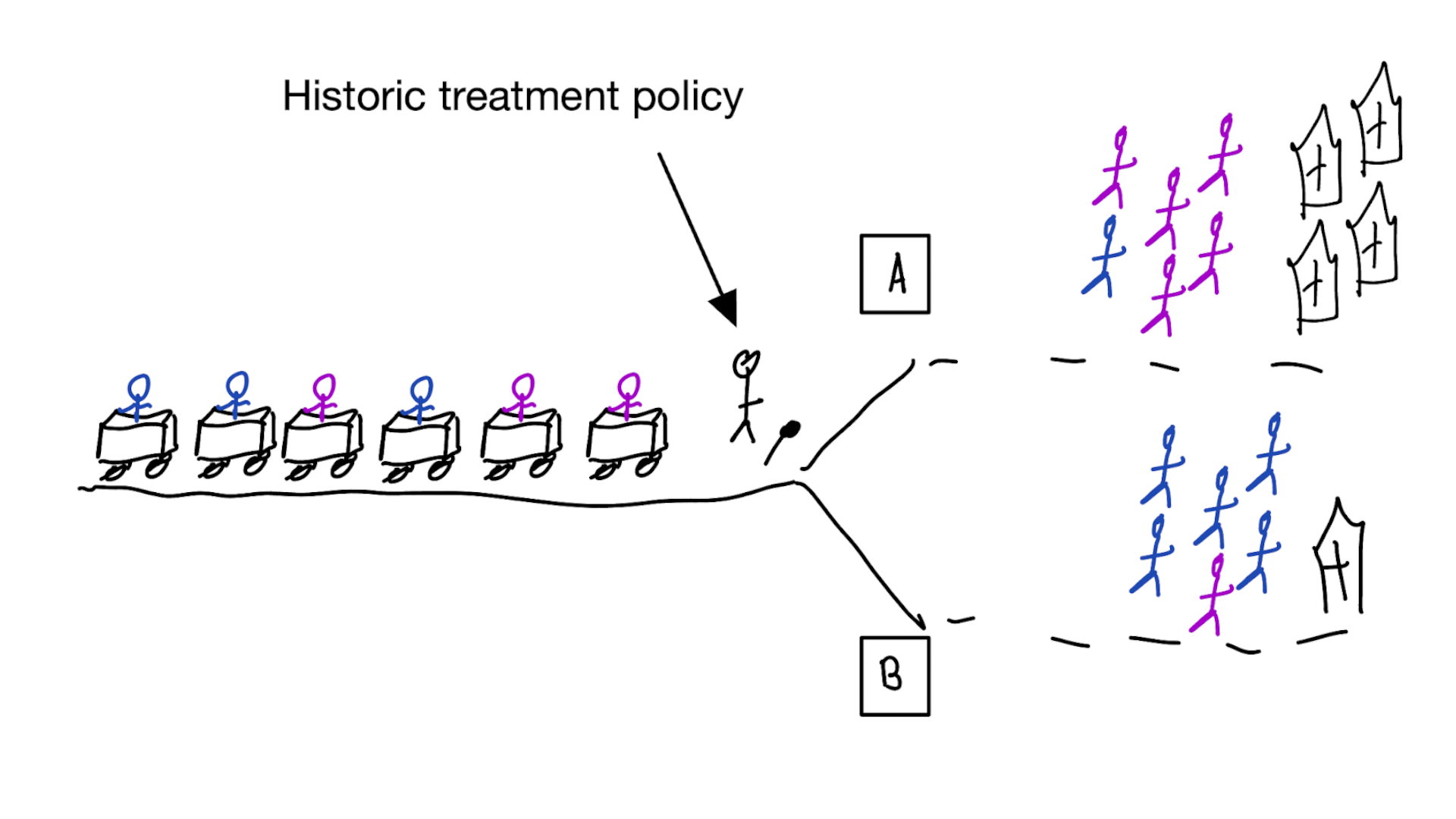
Treatment-naive risk models
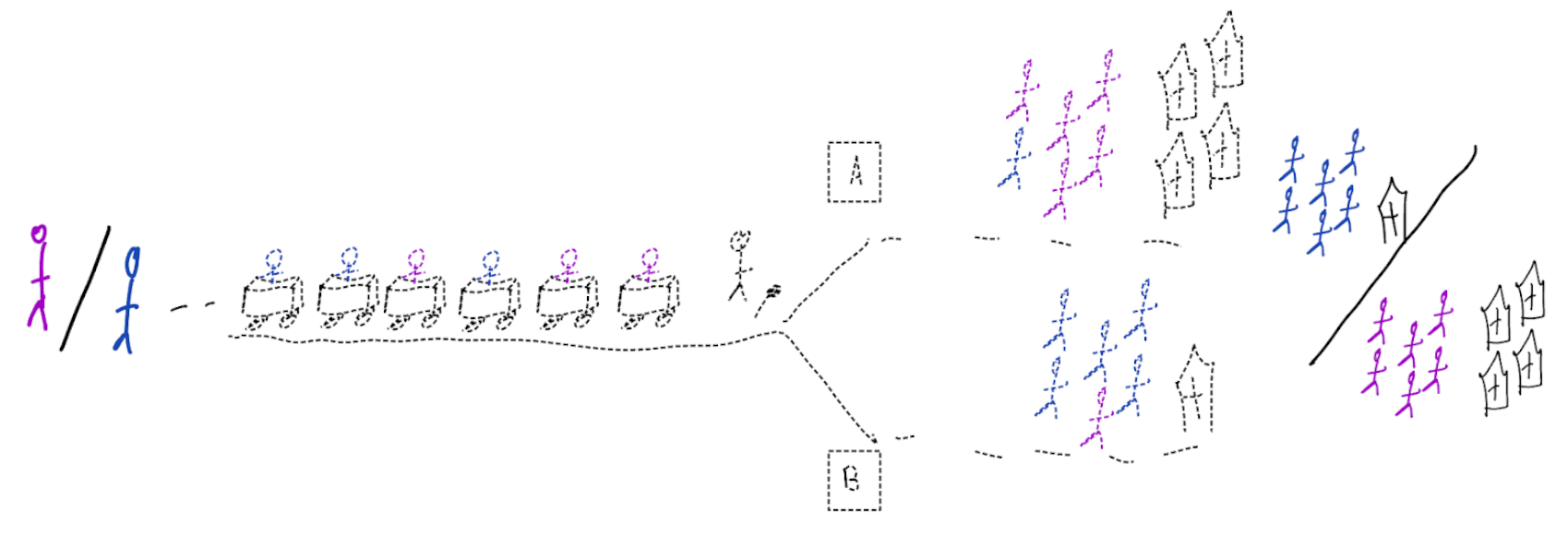
\[\begin{align} E[Y|X] \class{fragment}{= E[E_{t~\sim \pi_0(X)}[Y|X,t]]} \end{align}\]
Recommended validation practices do not protect against harm
because they do not evaluate the policy change


Bigger data does not protect against harmful risk models
More flexible models do not protect against harmful risk models

Gap between prediction accuracy and value for decision making
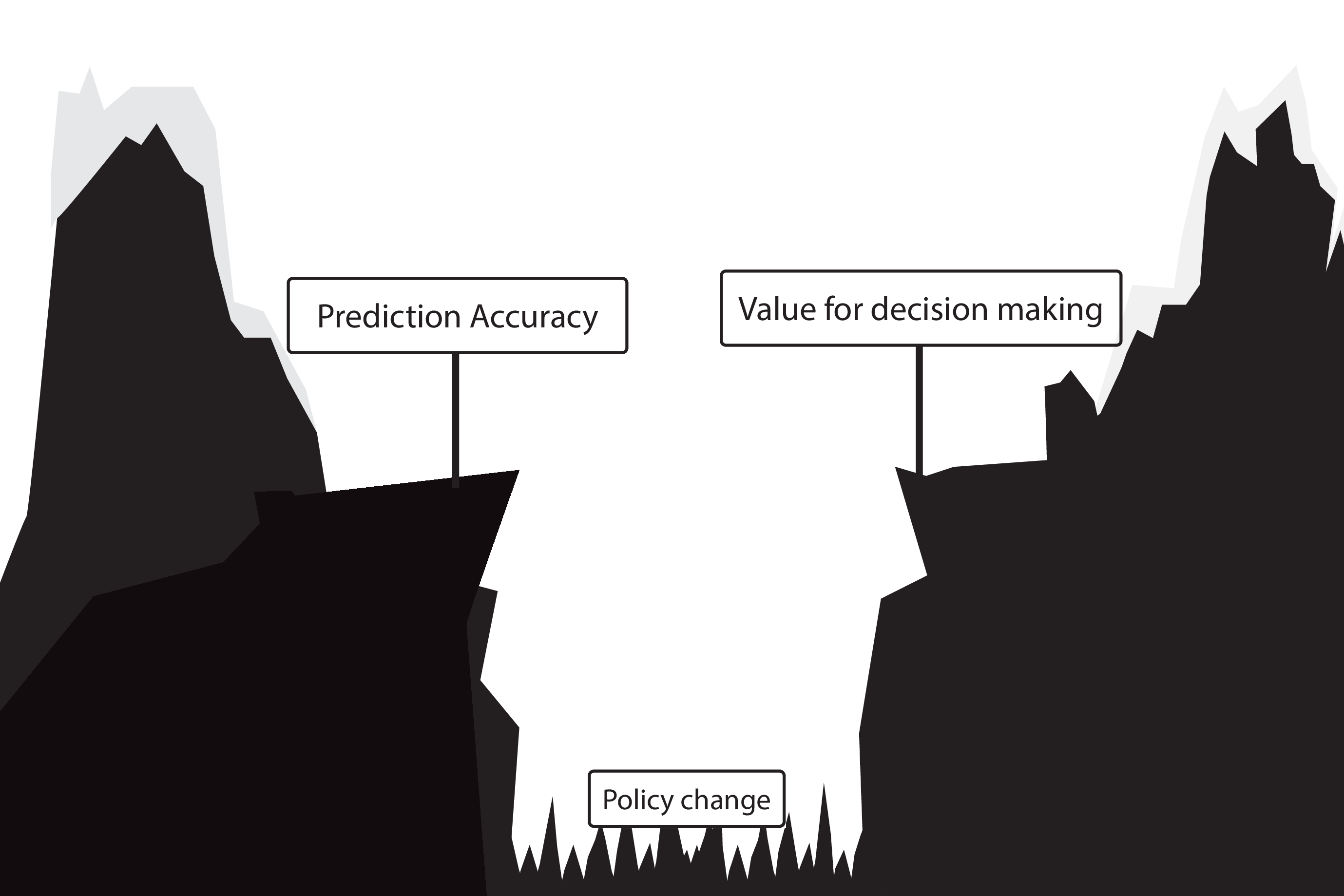
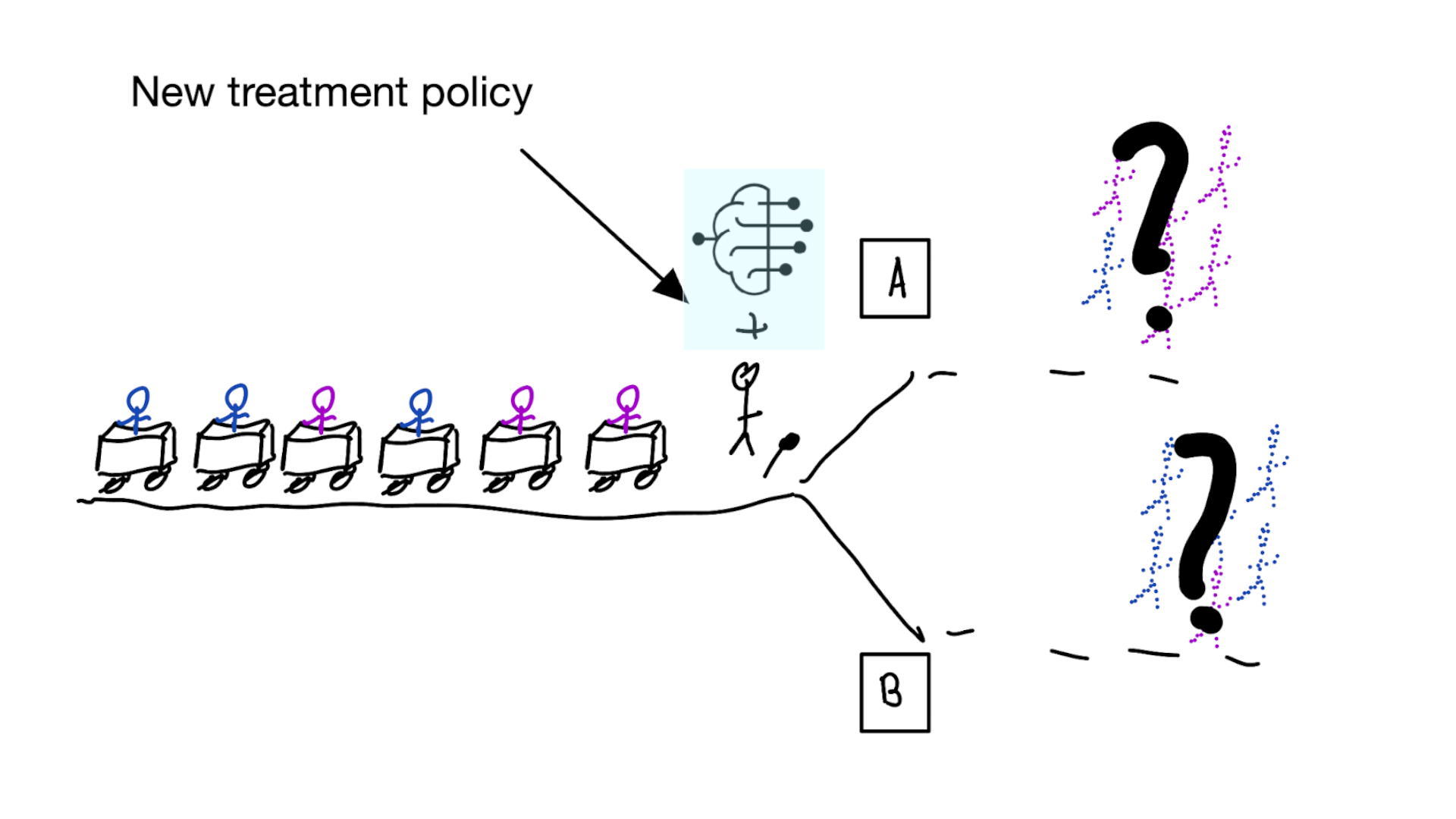
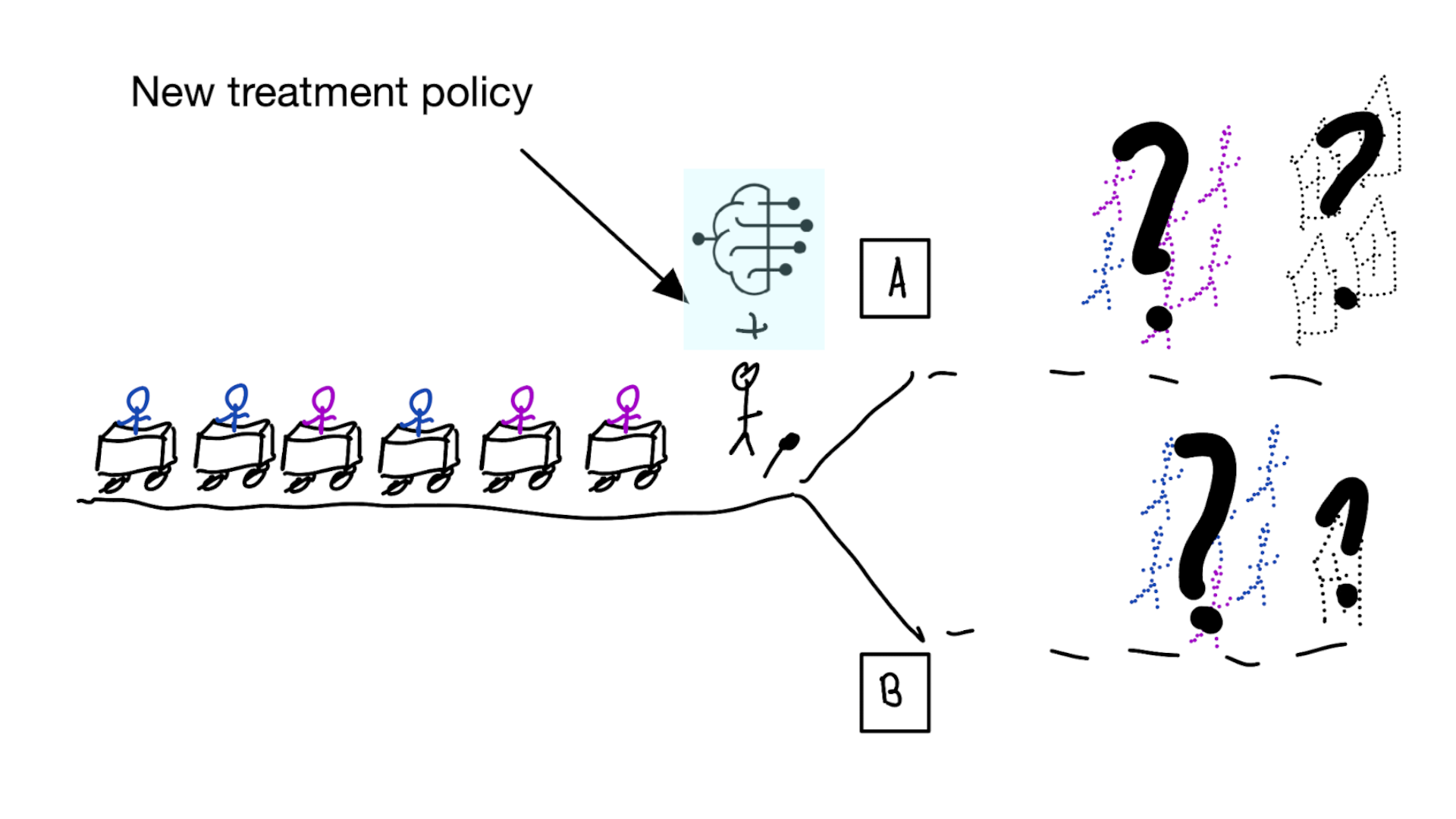
Deploying a model is an intervention that changes the way treatment decisions are made
using treatment naive prediction models for decision support
prediction-under-intervention

Proxy variables?
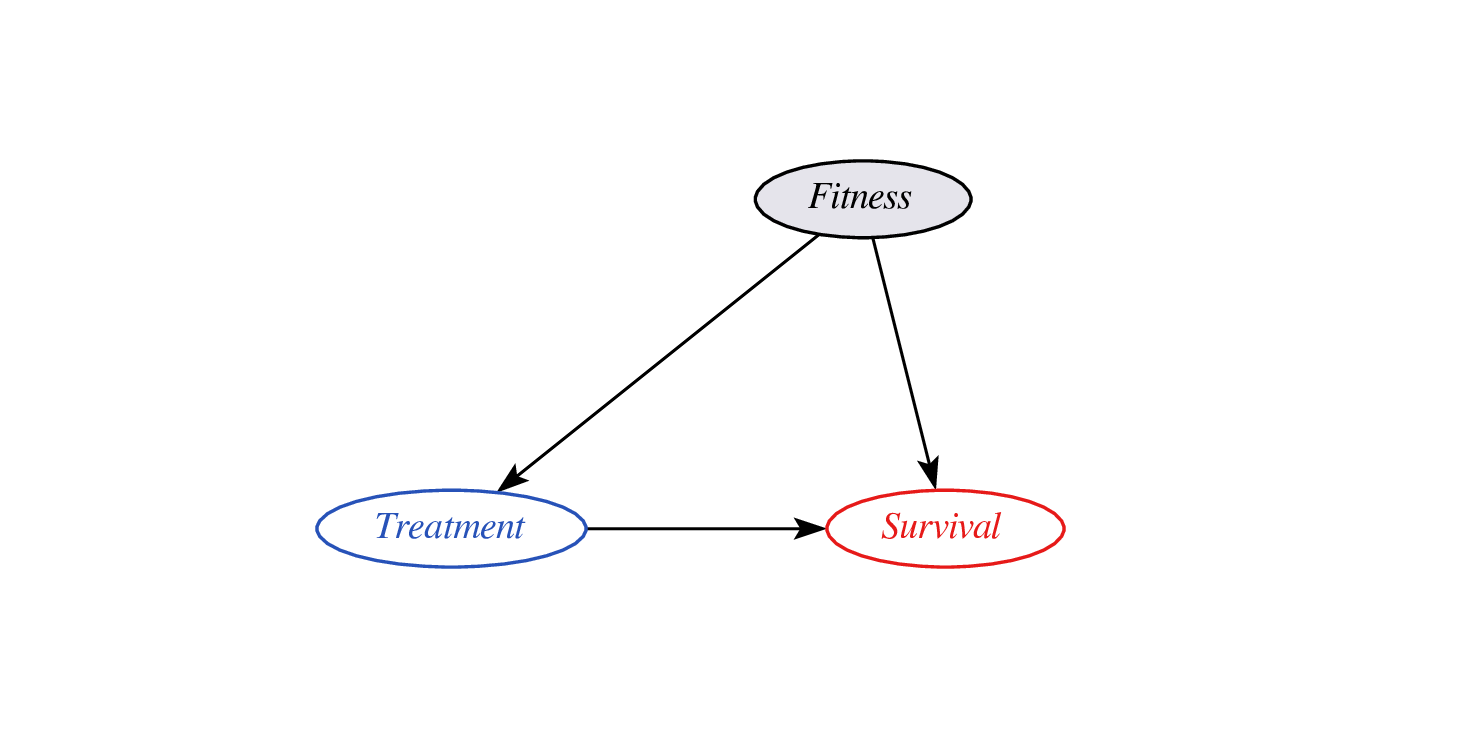
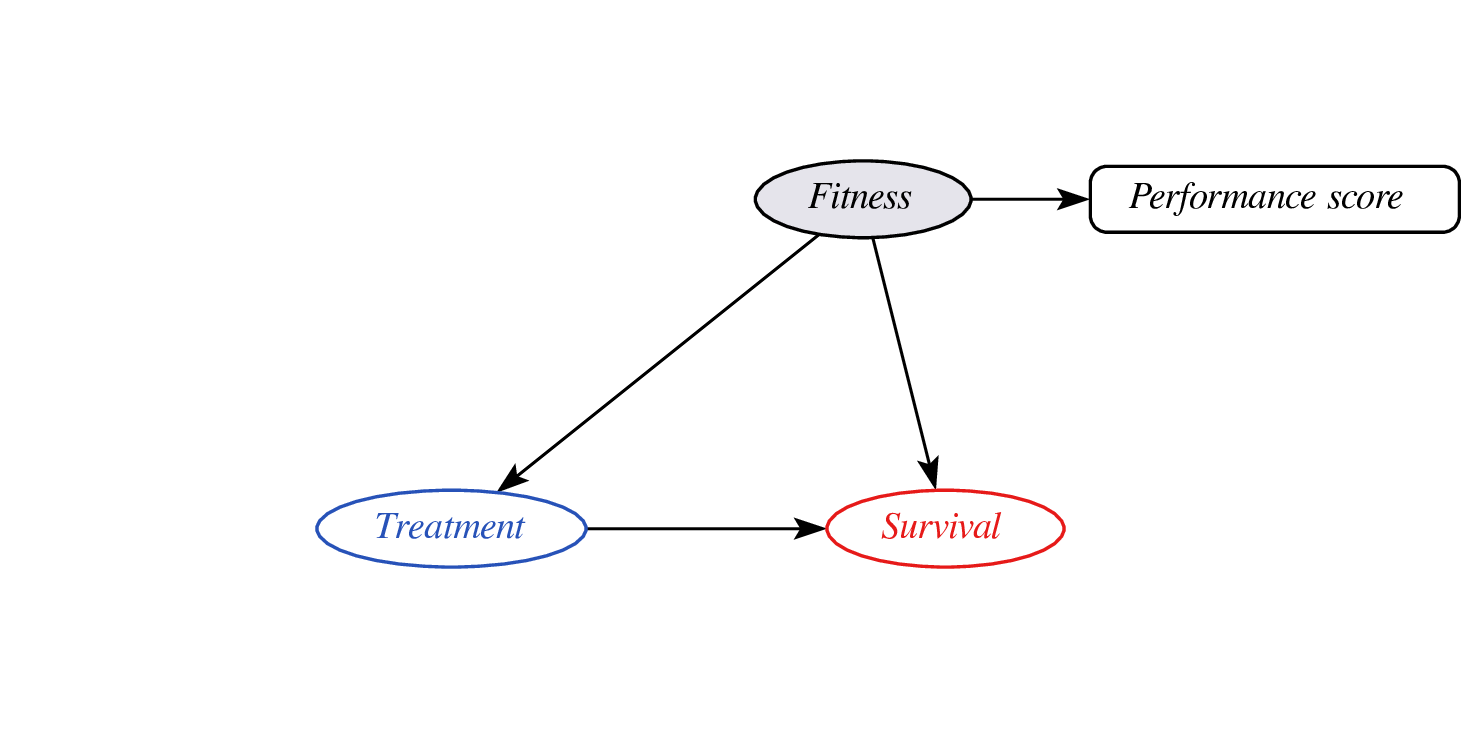
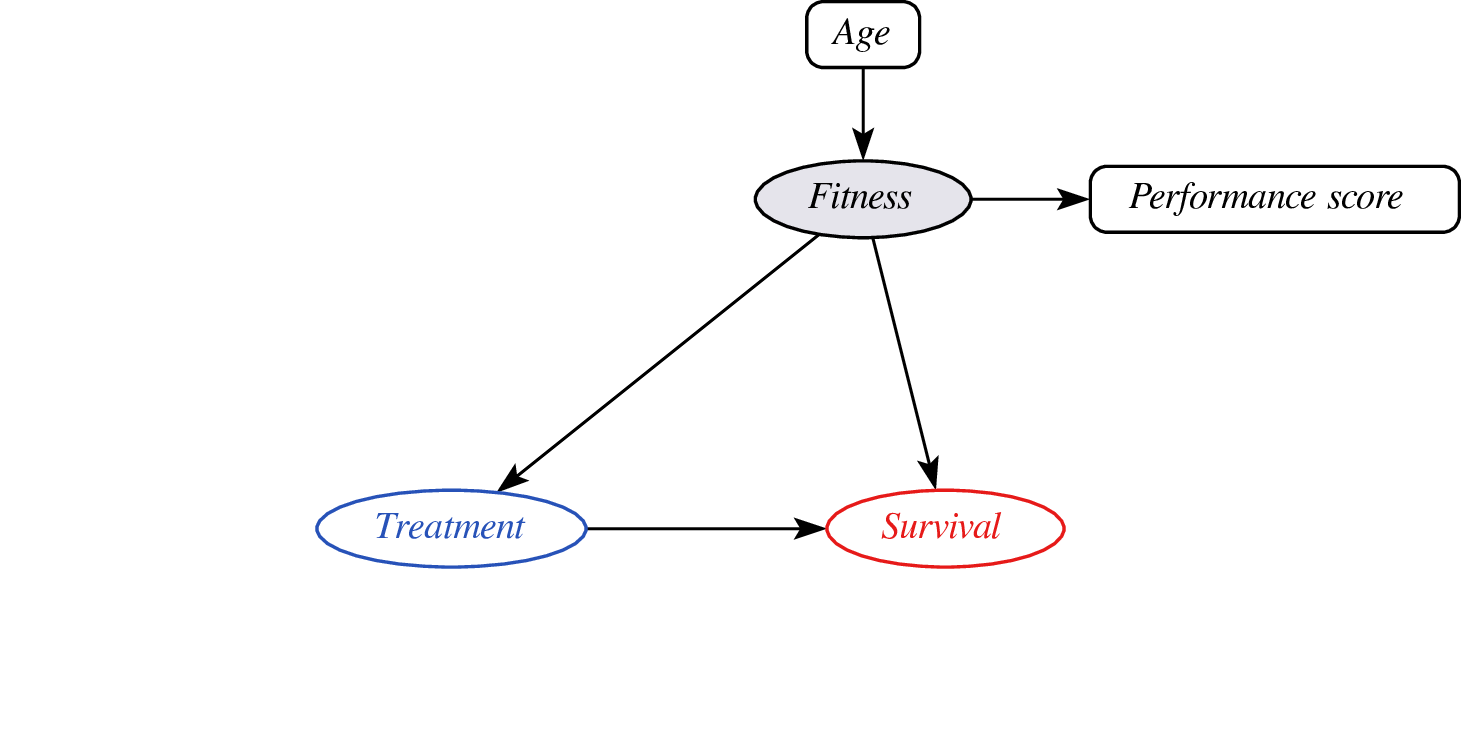
- problem: didn’t observe confounder fitness so cannot do confounder adjustment
- instead, leverage assumptions on confounder - proxy relationship (e.g. monotonicity)
- effect may still be identifyable (van Amsterdam et al. 2022)
Constant relative treatment effect?
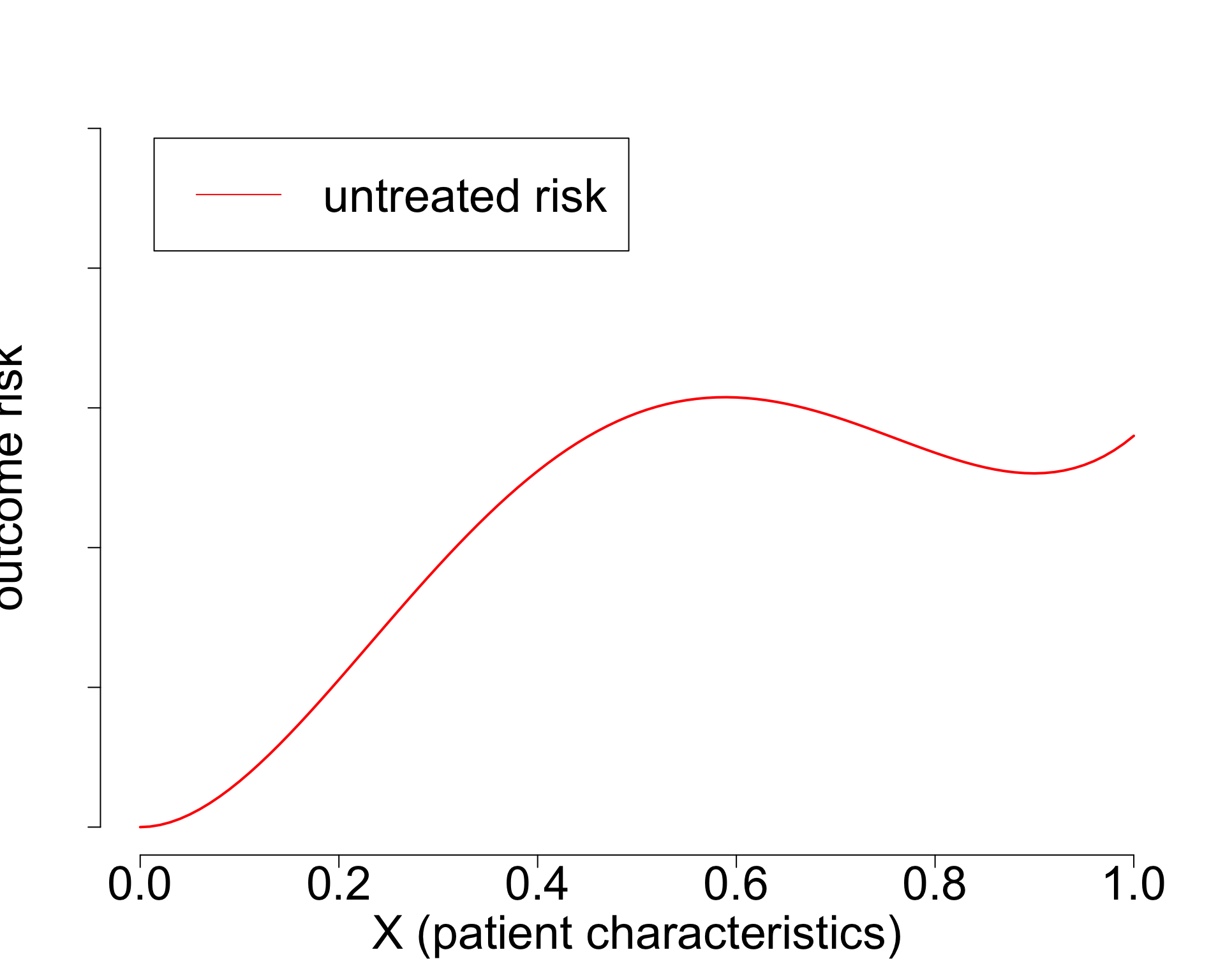
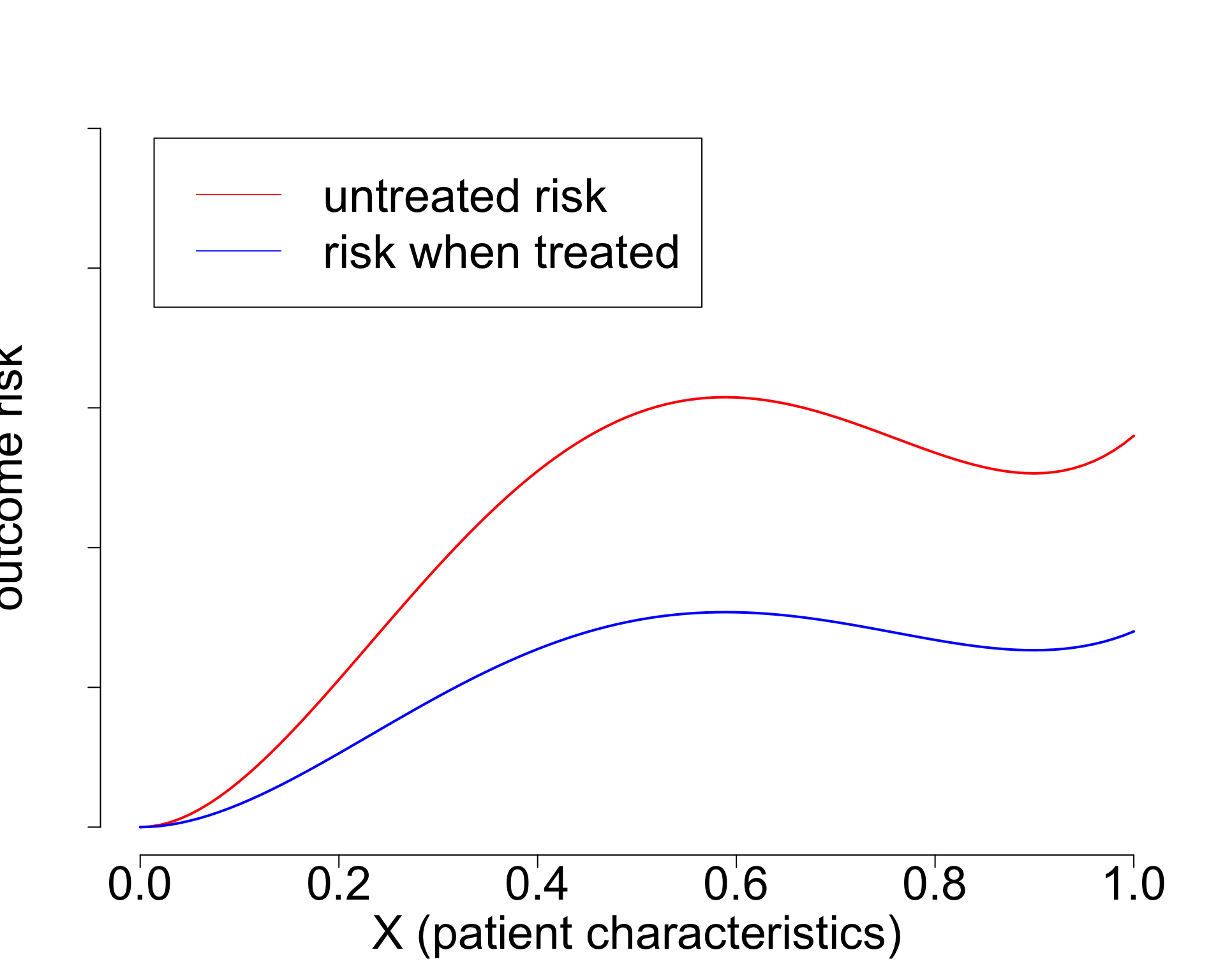
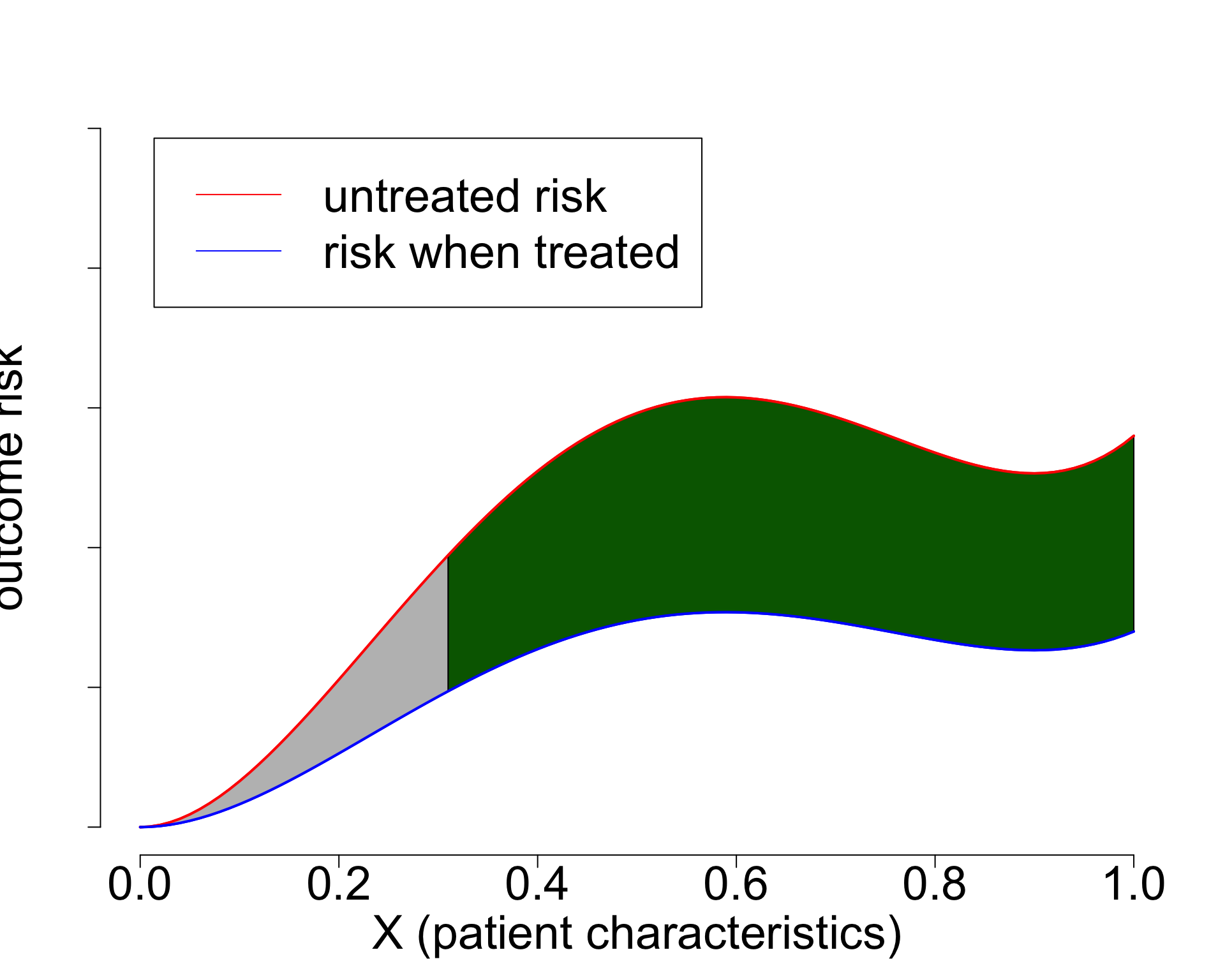
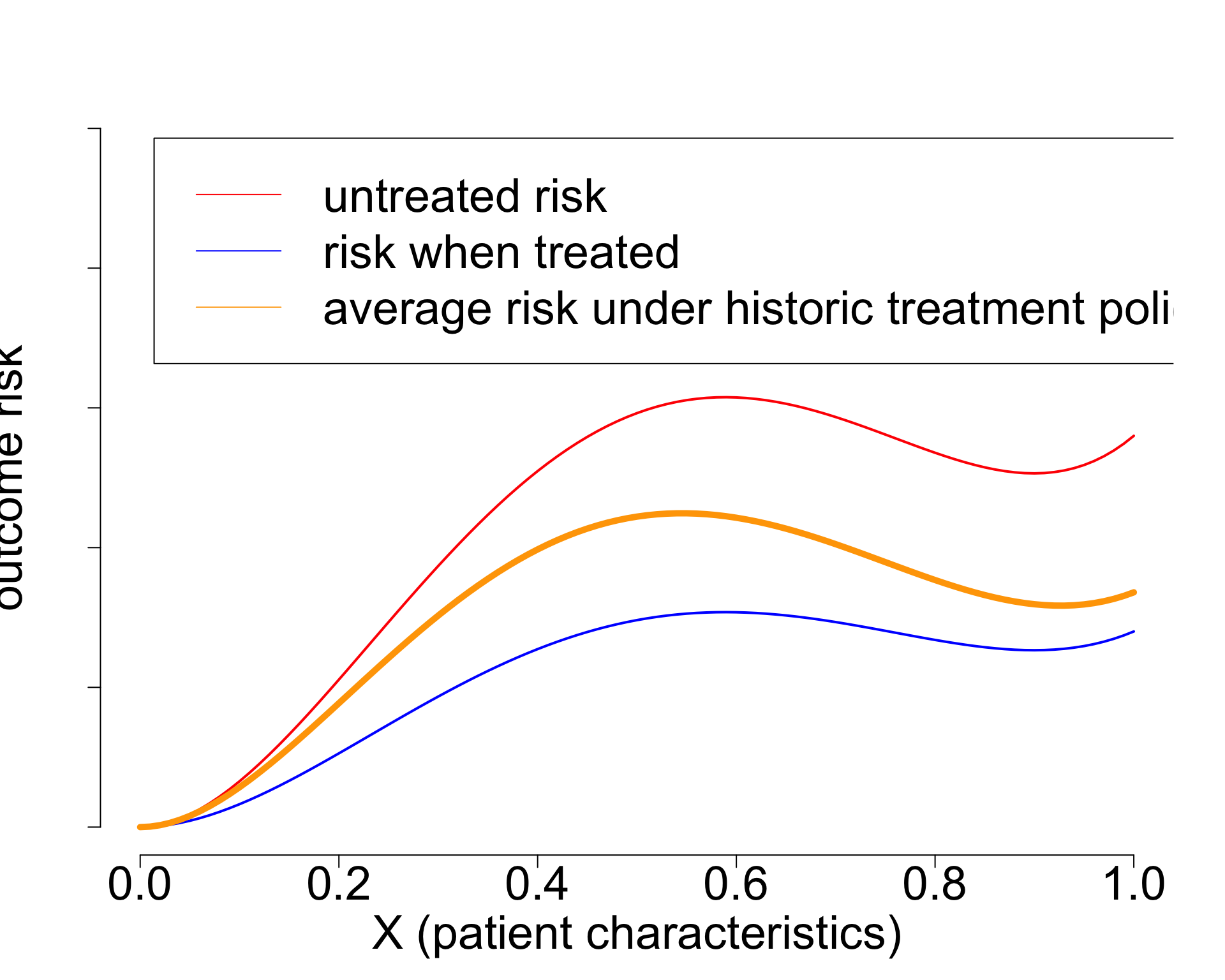
- Widely used paradigm (cardiovascular risk, chemotherapy in breast cancer, …)
- Untreated risk is a quantity of the interventional distribution (i.e. causal)
- Current risk-models: mix of treated / untreated patients (amsterdamAlgorithmsActionImproving2024?),
- or ungrounded methods (Candido dos Reis et al. 2017; Xu et al. 2021).
- Need better `causal’ methods (van Amsterdam and Ranganath 2023)
Take-aways
- Prediction and causal inference come together neatly by declaring \(E[Y|\text{do}(T=t),X]\) as the estimand
- (mis)using prediction models for treatment decisions without causal thinking and evaluation is a bad idea
- deploying models for decision support is an intervention and should be evaluated as such

From algorithms to action: improving patient care requires causality (amsterdamAlgorithmsActionImproving2024?)

When accurate prediction models yield harmful sel-fulfilling prophecies (vanamsterdamWhenAccuratePrediction2024a?)