AI and its (mis)uses in medical research and practice
Infection and Immunity spring meeting
2024-04-18
ML tasks
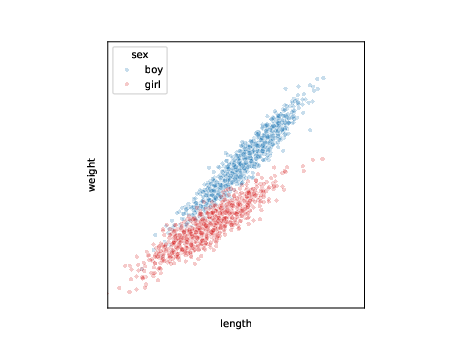
data:
| i | length | weight | sex |
|---|---|---|---|
| 1 | 137 | 30 | boy |
| 2 | 122 | 24 | girl |
| 3 | 101 | 18 | girl |
| … | … | … | … |
\[l_i,w_i,s_i \sim p(l,w,s)\]
ML tasks: generation
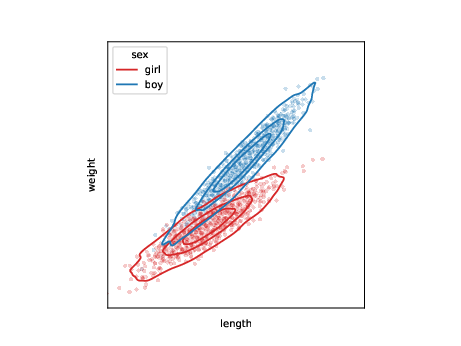
use samples to learn model \(p_{\theta}\) for joint distribution \(p\) \[ l_j,w_j,s_j \sim p_{\theta}(l,w,s) \]
ML tasks: conditional generation
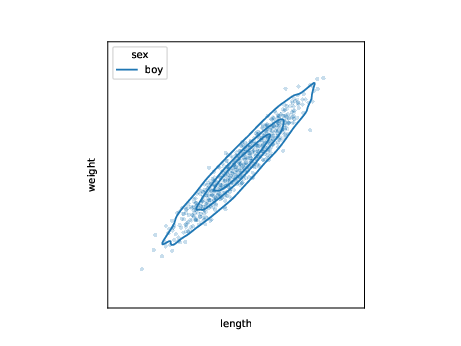
use samples to learn model for conditional distribution \(p\) \[ l_j,w_j \sim p_{\theta}(l,w|s=\text{boy}) \]
| task | |
|---|---|
| generation | \(l_j,w_j,s_j \sim p_{\theta}(l,w,s)\) |
ML tasks: conditional generation 2
use samples to learn model for conditional distribution \(p\) of one variable \[ s_j \sim p_{\theta}(s|l=l',w=w') \]
| task | |
|---|---|
| generation | \(l_j,w_j,s_j \sim p_{\theta}(l,w,s)\) |
| conditional generation | \(l_j,w_j \sim p_{\theta}(l,w|s=\text{boy})\) |
ML tasks: discrimination
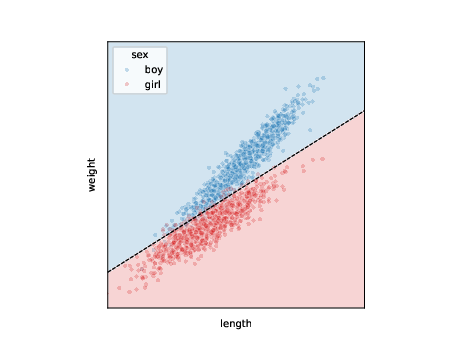
call this one variable outcome and classify when expected value passes threshold (e.g. 0.5): \[ s_j = p_{\theta}(s|l=l',w=w') > 0.5 \]
| task | |
|---|---|
| generation | \(l_j,w_j,s_j \sim p_{\theta}(l,w,s)\) |
| conditional generation | \(l_j,w_j \sim p_{\theta}(l,w|s=\text{boy})\) |
| discrimination | \(p_{\theta}(s|l=l_i,w=w_i) > 0.5\) |
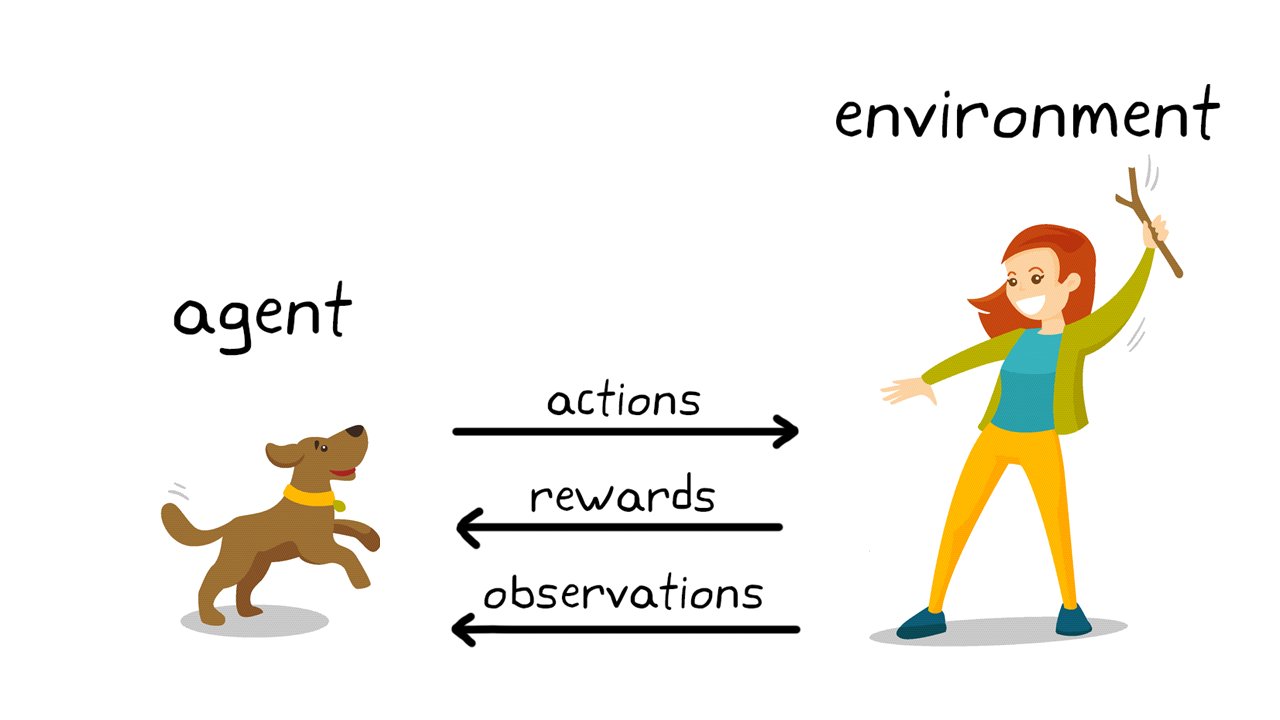
ML tasks: reinforcement learning
- e.g. computers playing games
- maybe not so useful for clinical research as requires many experiments
Machine learning is statistical learning with flexible models
- There is no fundamental difference between statistics and machine learning
- both optimize parameters to improve some criterion (loss / likelihood) that measures model fit to data
- models used in machine learning are more flexible


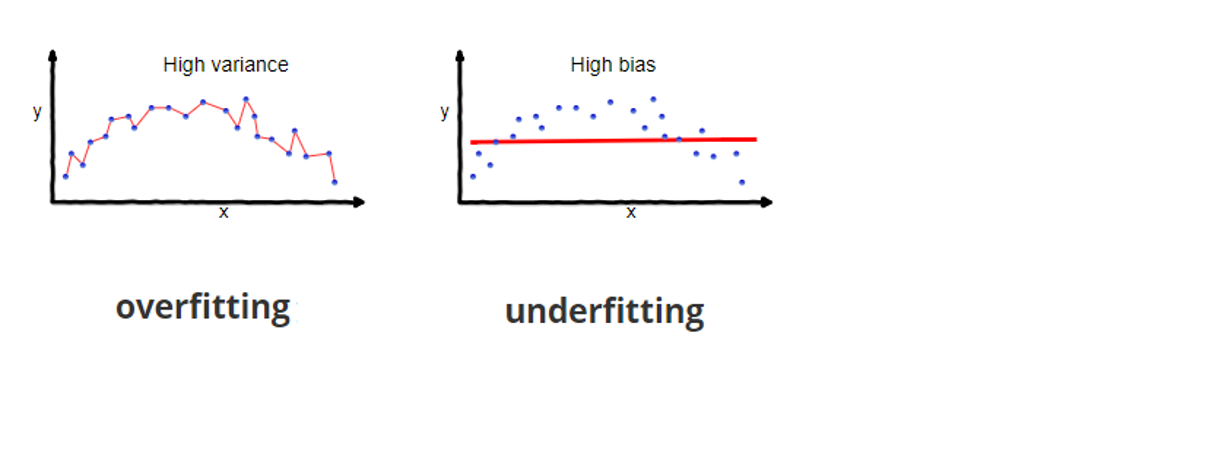
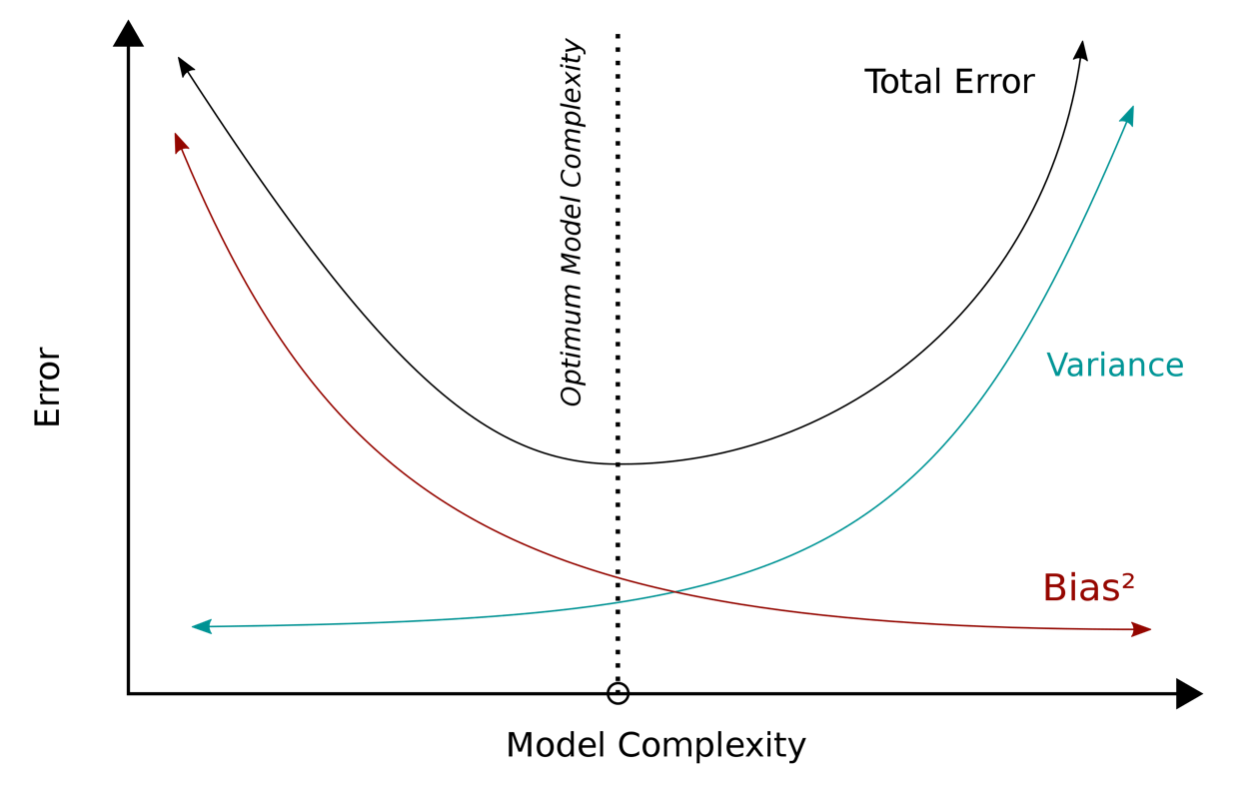
ML models can fit more functions but also more likely to overfit

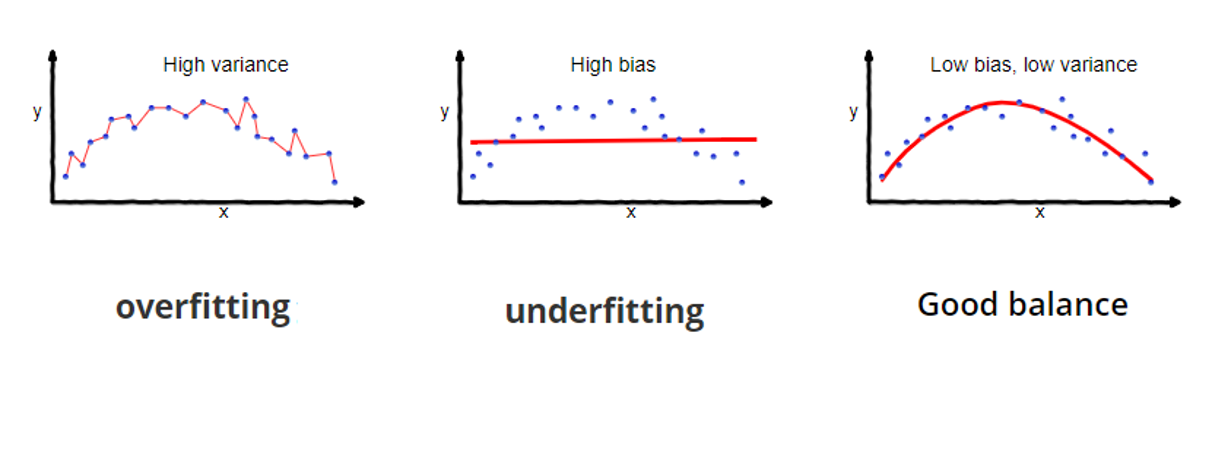
Should pick the ‘right’ amount of model complexity
GPT-4 scale



rule-based vs LLMs
- deduction from explicit knowledge
- knowledge verifiable and fast
- constrained to deducible

- extracted from observed data
- unverifiable and compute intensive
- “chatGPT seems to know(?) much”

A sobering note
- ML in medicine has been ‘hot’ since at least the 90s (Cooper et al. 1997)
- not much evidence that it outperforms regression on most tasks (Christodoulou et al. 2019)
- though many poorly performed studies (Dhiman et al. 2022)



Improving the world is a causal task
- statistics / ML: what to expect when we passively observe the world
- not how we can intervene to make things better, this requires causality
- Question 1
- yellowish fingers predict lung cancer, paint fingers to skin color?
- weight loss predicts death in lung cancer, send patients to couch with McDonalds?
![]()


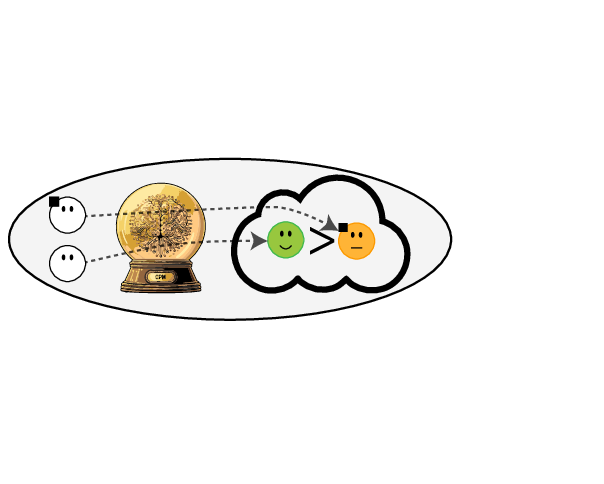
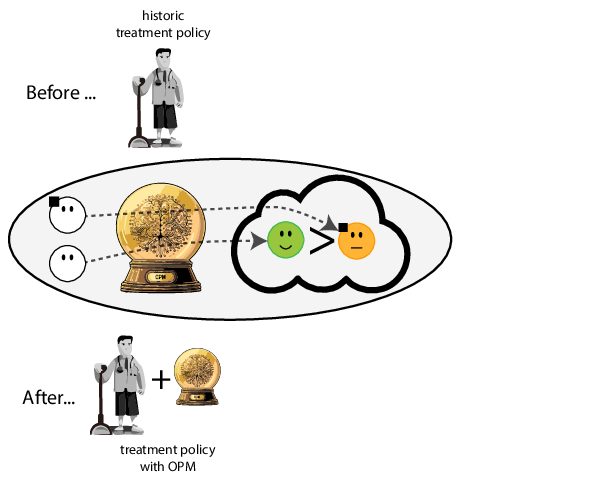
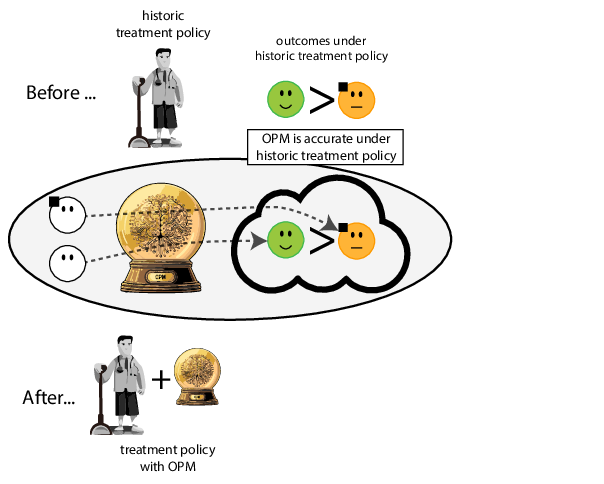
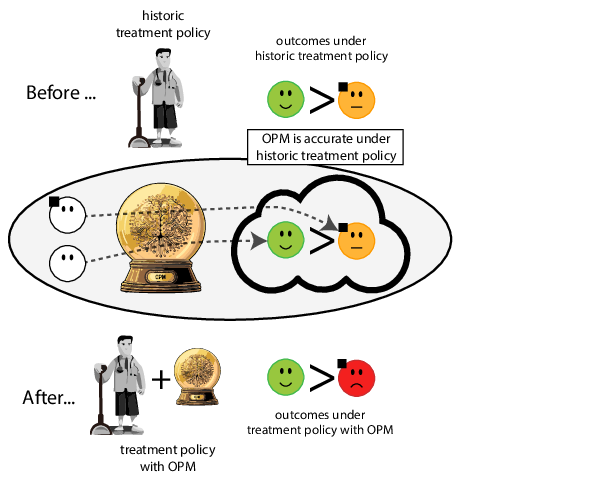
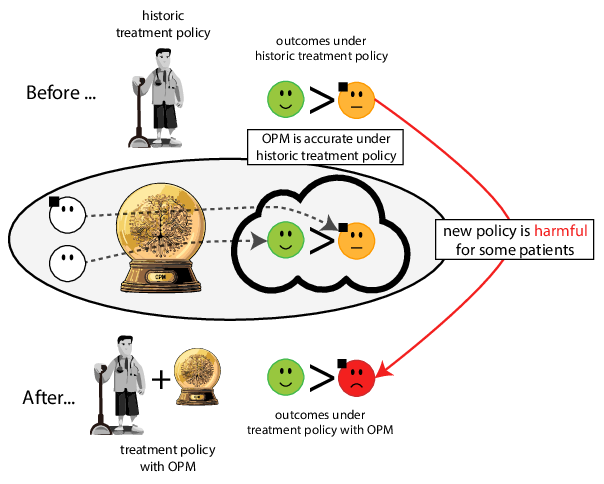
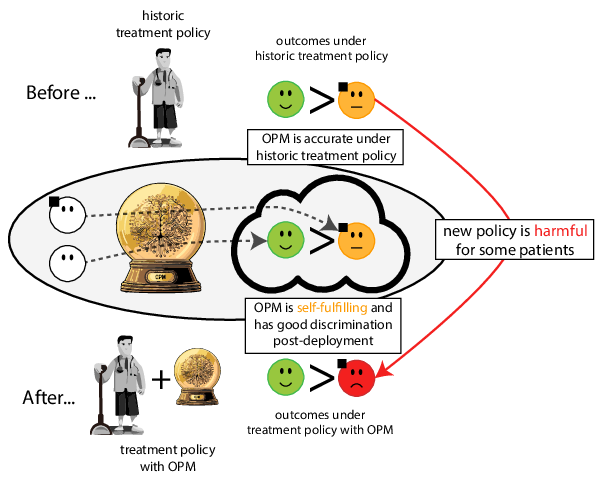
Prediction modeling is very popular in medical research

Tip
building models for decision support without regards for the historic treatment policy is a bad idea
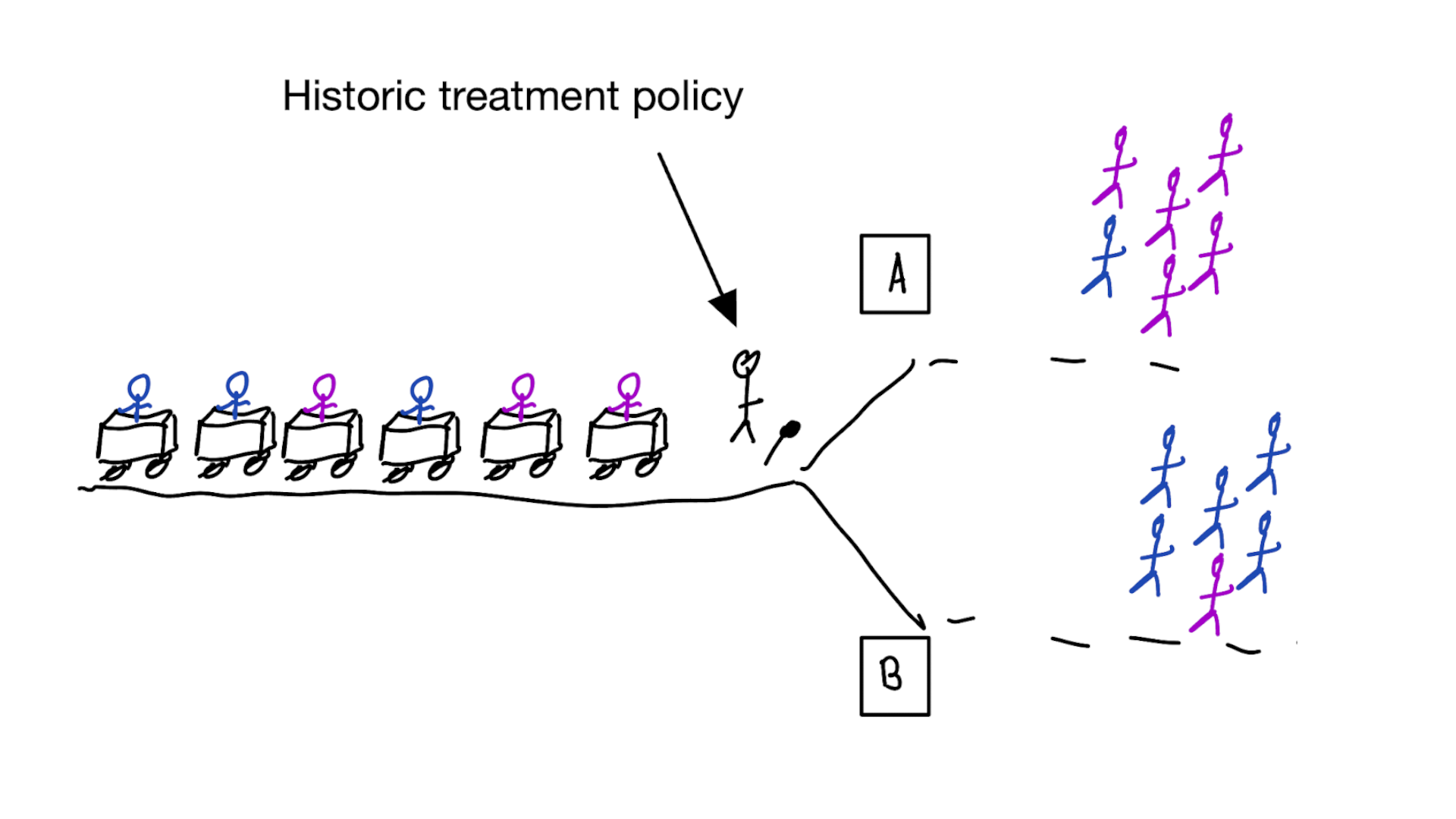
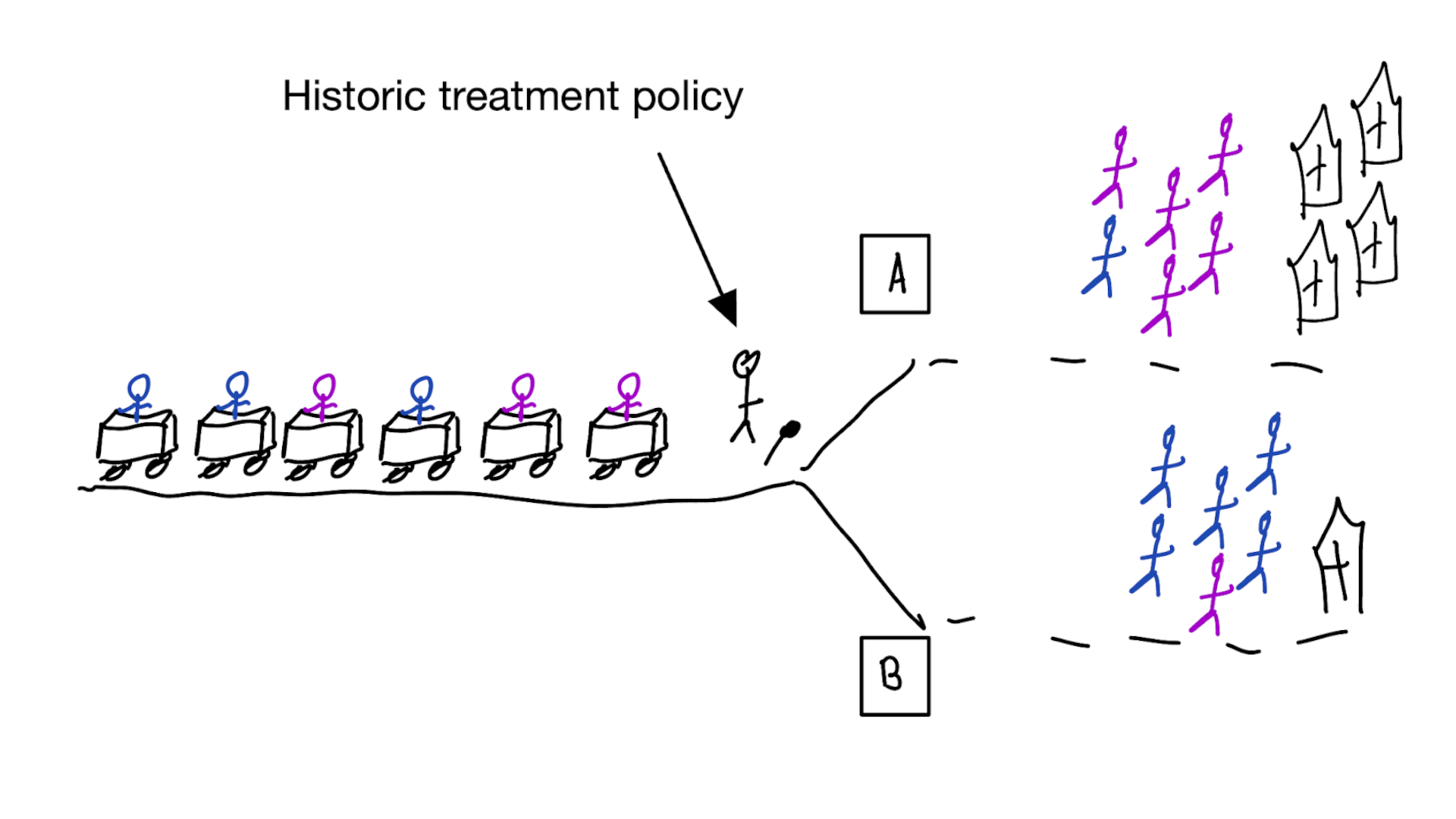
Treatment-naive risk models
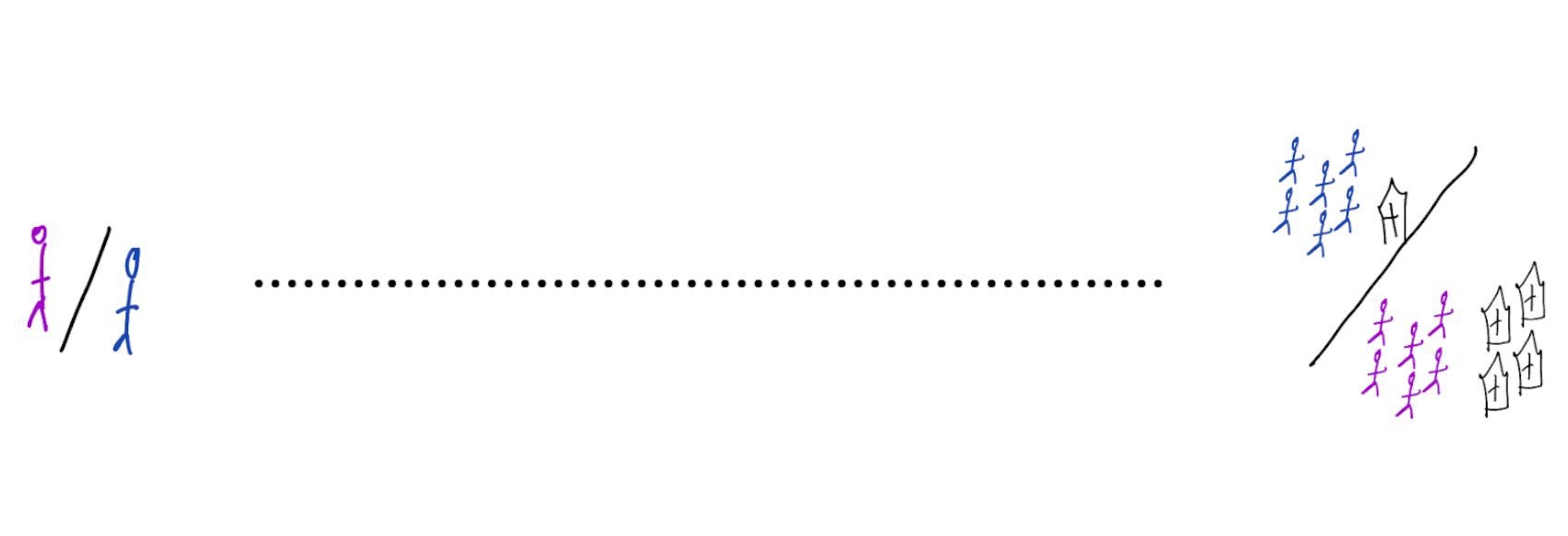

Other risk models:
- condition on given treatment and traits
- unobserved confounding (hat type) leads to wrong treatment decisions
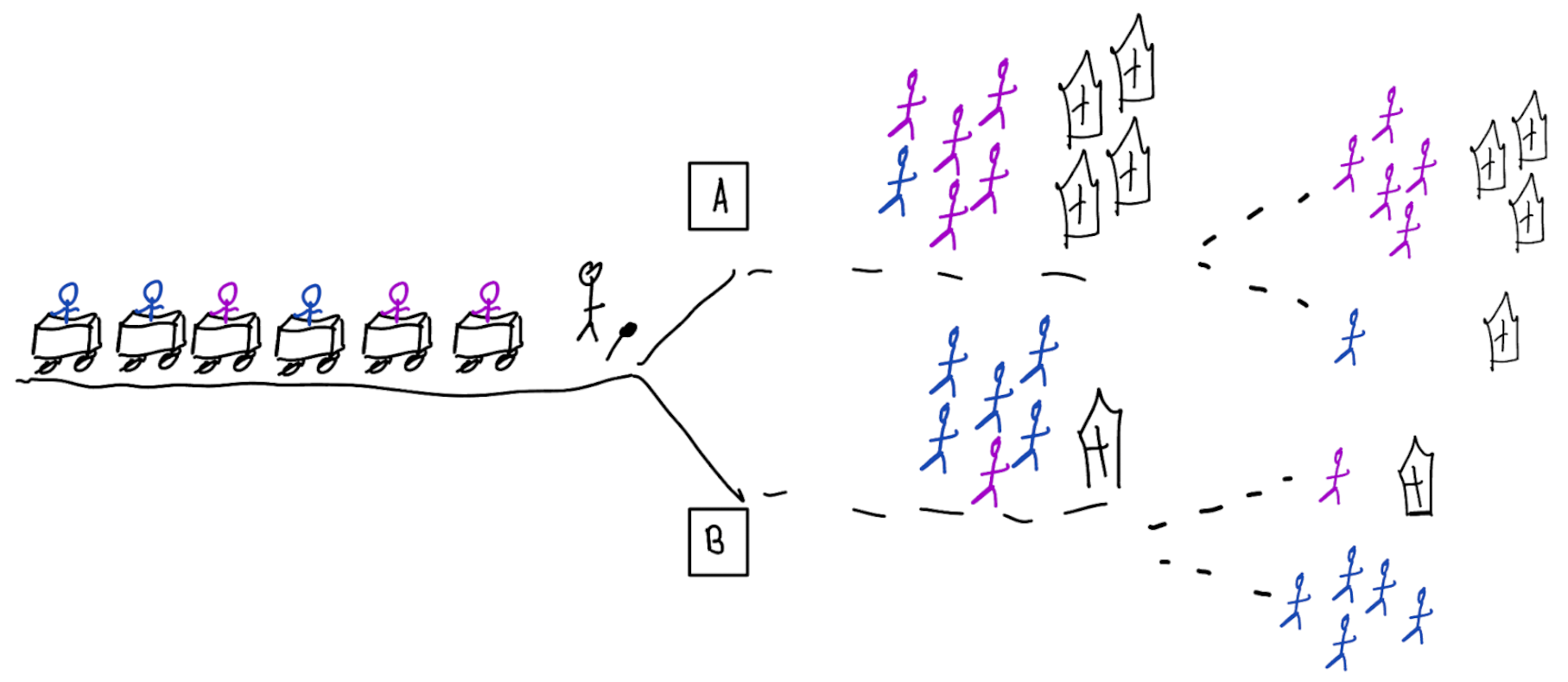
Recommended validation practices do not protect against harm
because they do not evaluate the policy change



Bigger data does not protect against harmful risk models
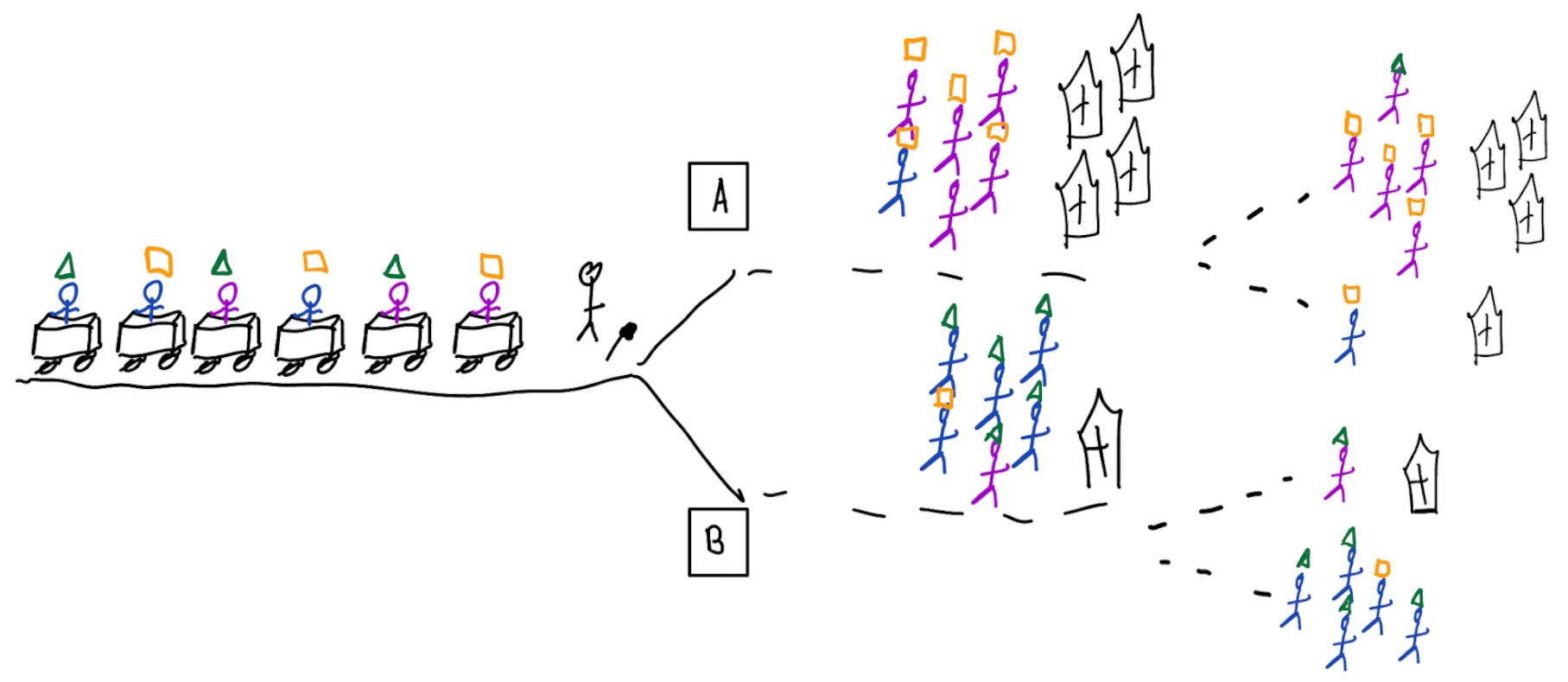
More flexible models do not protect against harmful risk models

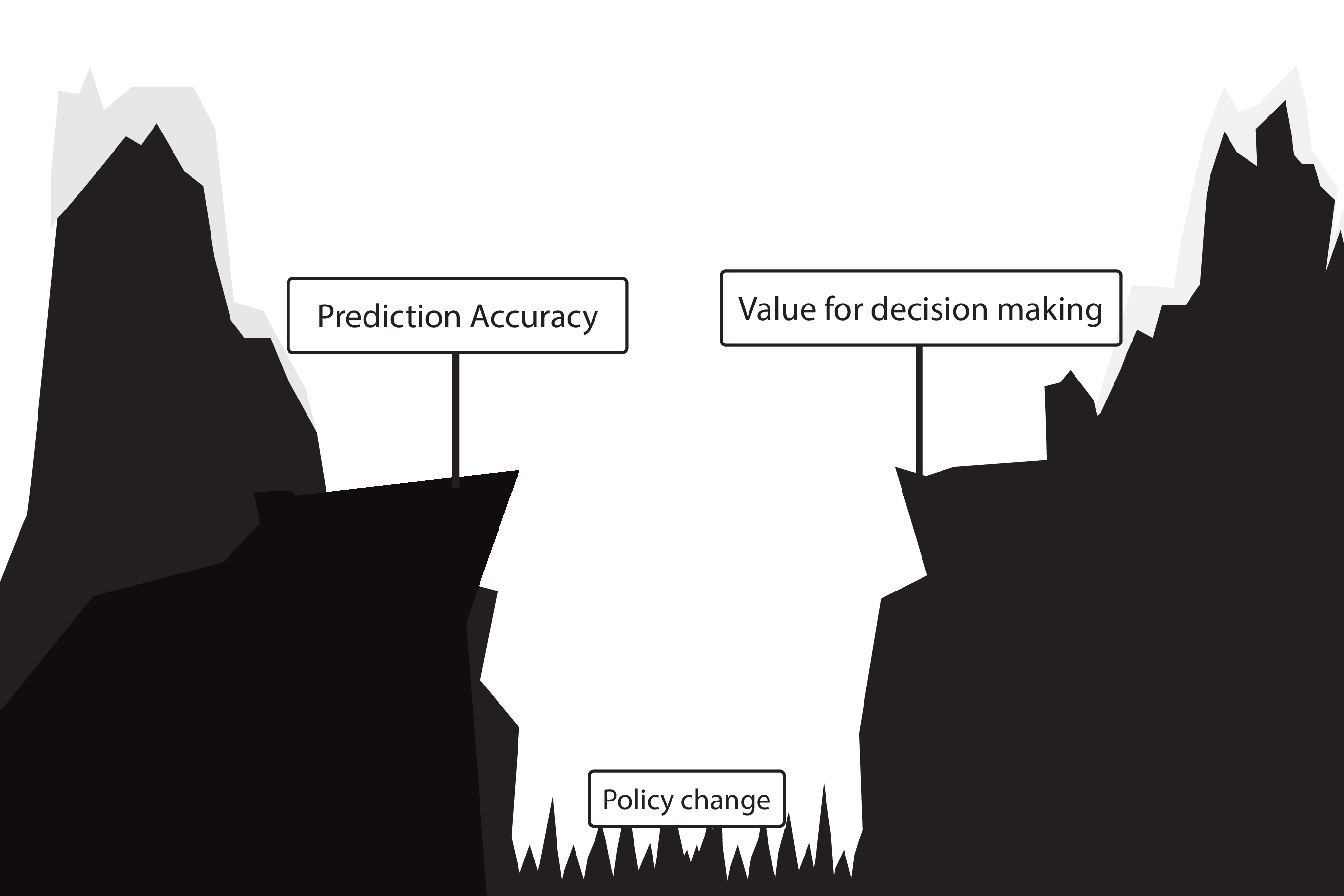
Gap between prediction accuracy and value for decision making
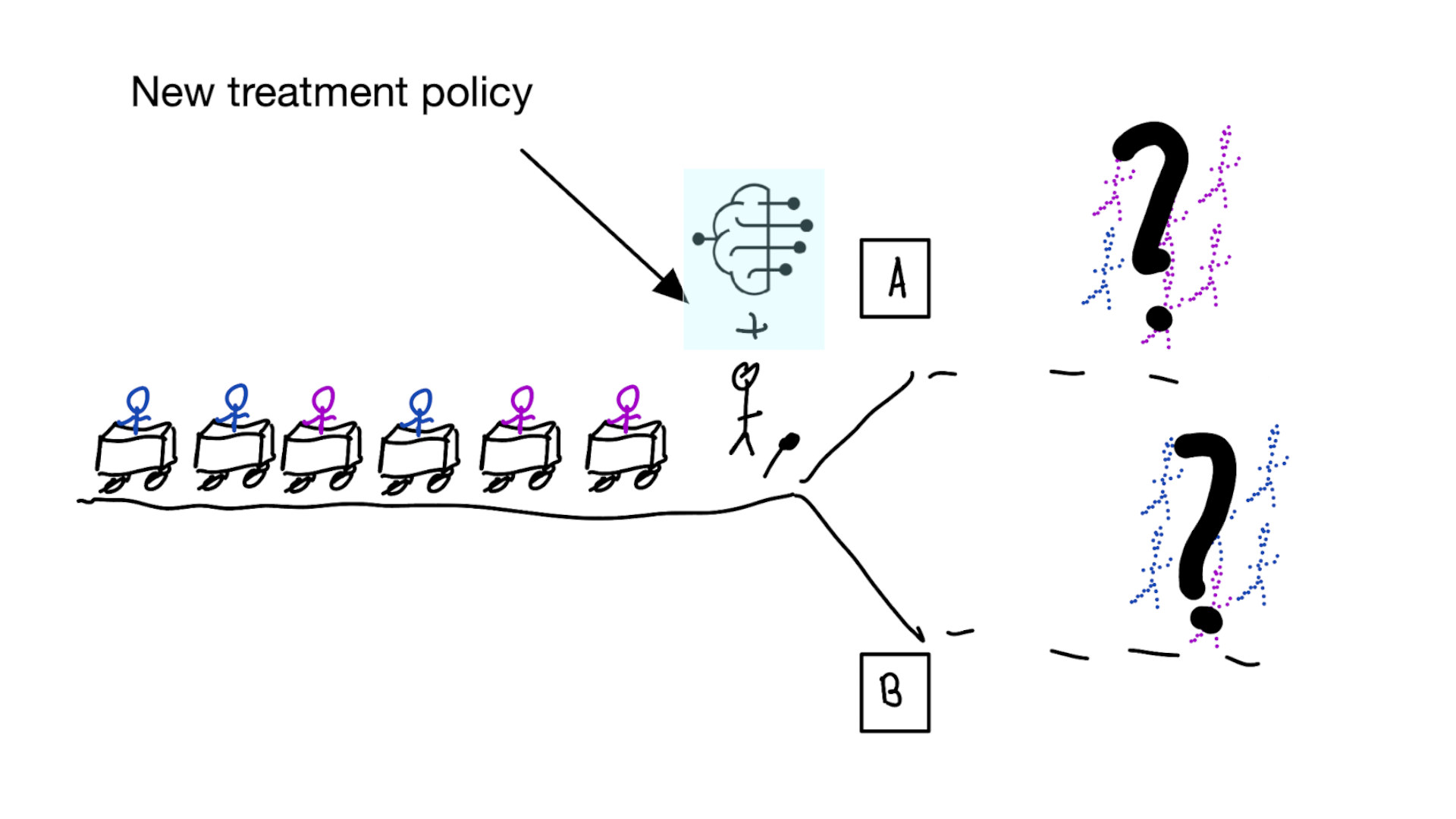
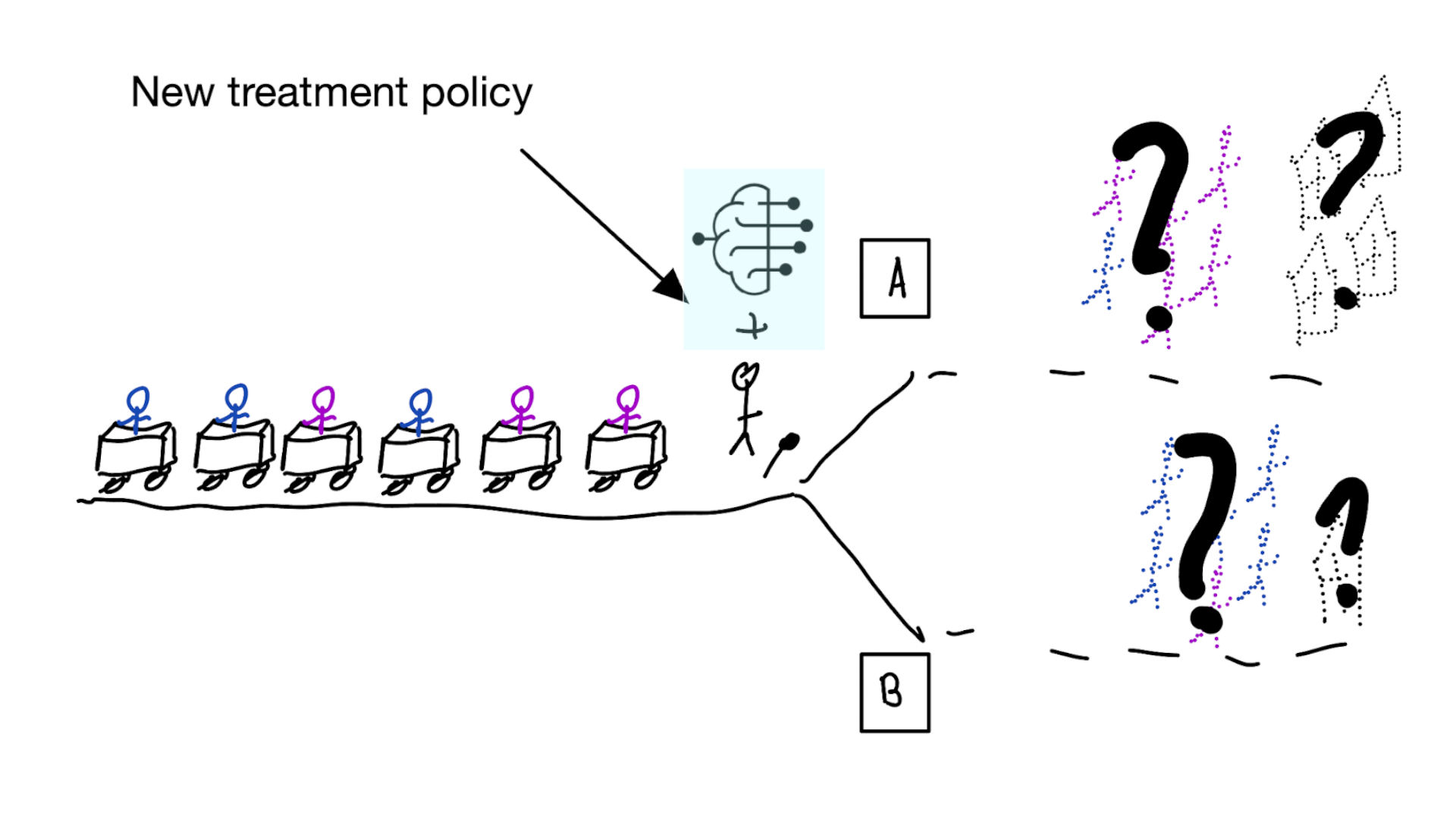
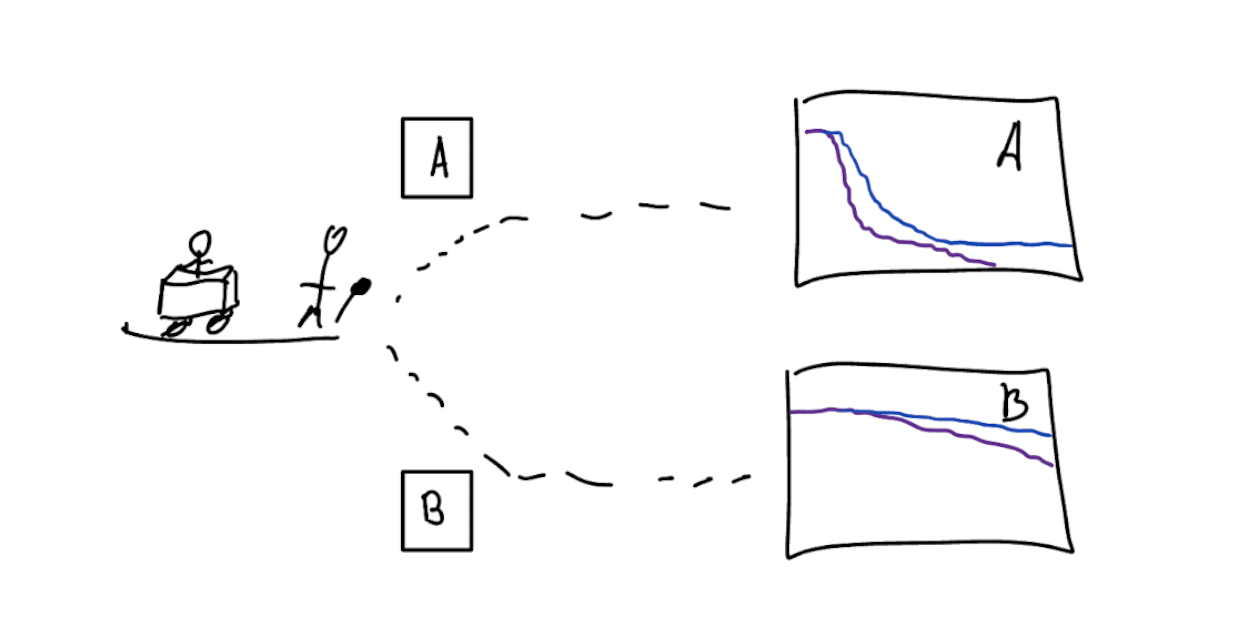
Prediction-under-intervention models
Predict outcome under hypothetical intervention of giving certain treatment
When developing risk models,
always discuss:
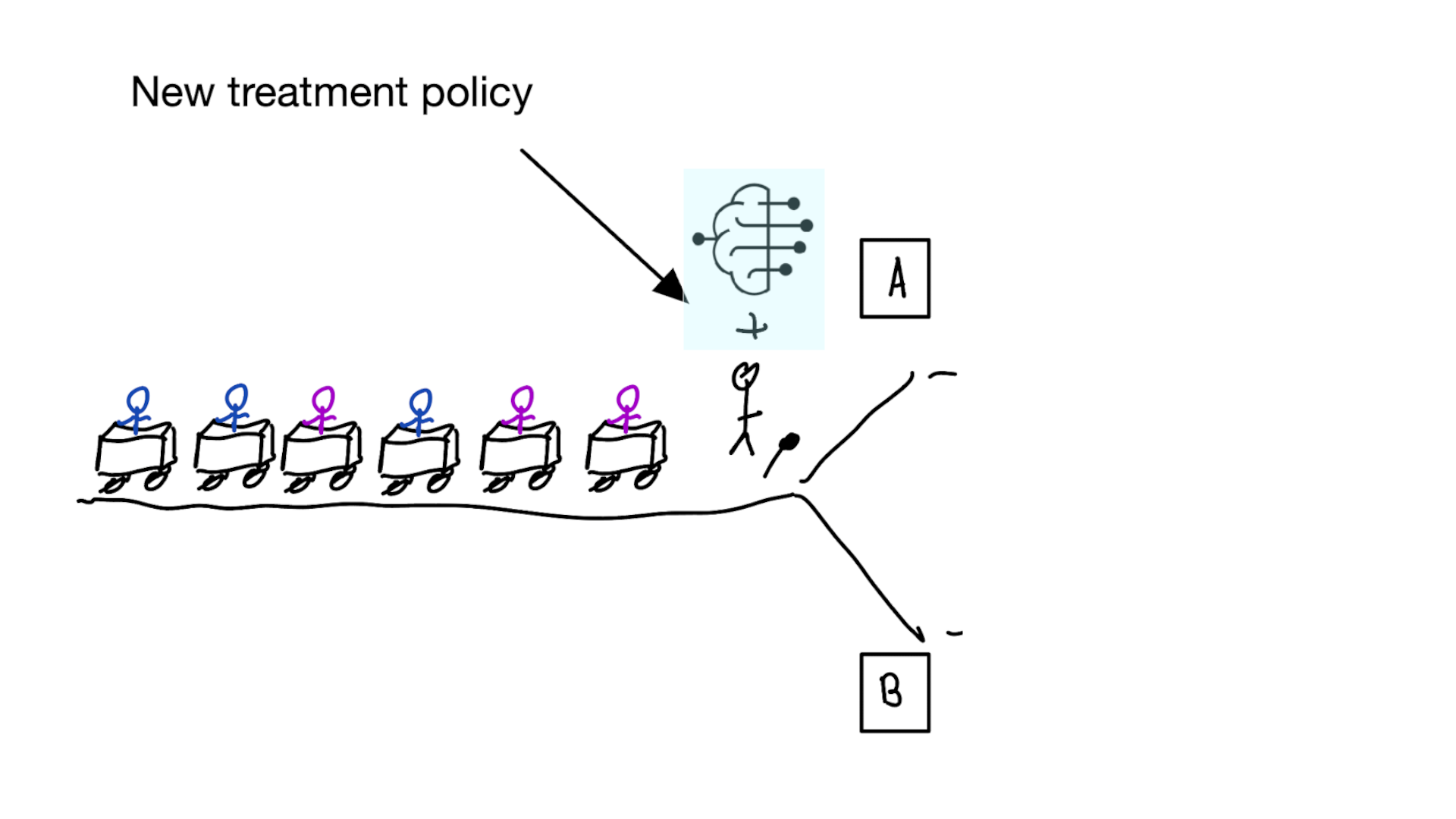
1. what is effect on treatment policy?
2. what is effect on patient outcomes?
Don’t assume predicting well leads to good decisions
think about the policy change

From algorithms to action: improving patient care requires causality (Amsterdam, Jong, et al. 2024)

When accurate prediction models yield harmful sel-fulfilling prophecies (Amsterdam, Geloven, et al. 2024)