Causal perspectives on prediction modeling
2024-08-08
Examples of prediction tasks
observe an \(X\), want to know what to expect for \(Y\)
1. X = patient caughs, Y = patient has lung cancer
2. X = ECG, Y = patient has heart attack
3. X = CT-scan, Y = patient dies within 2 years


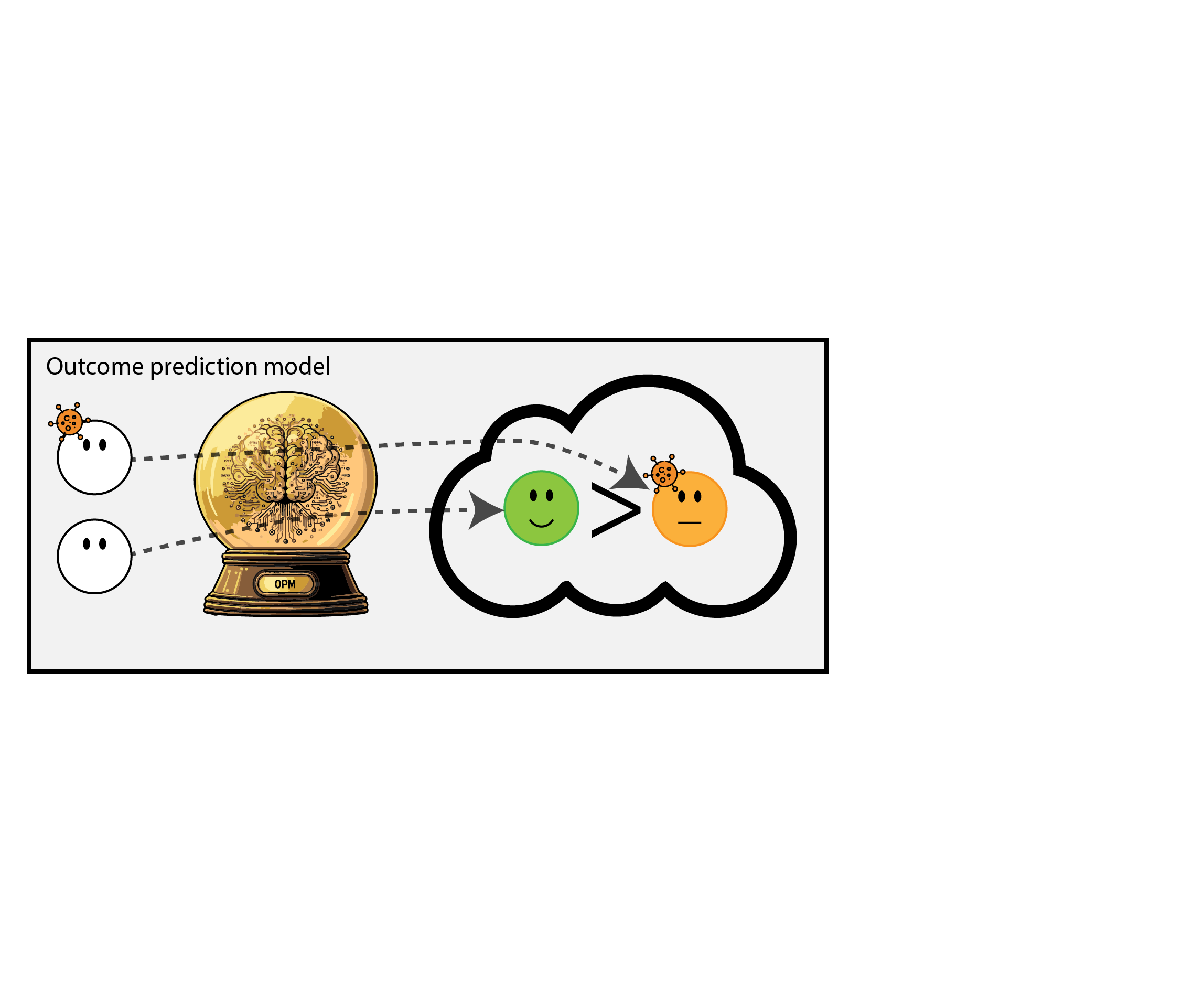
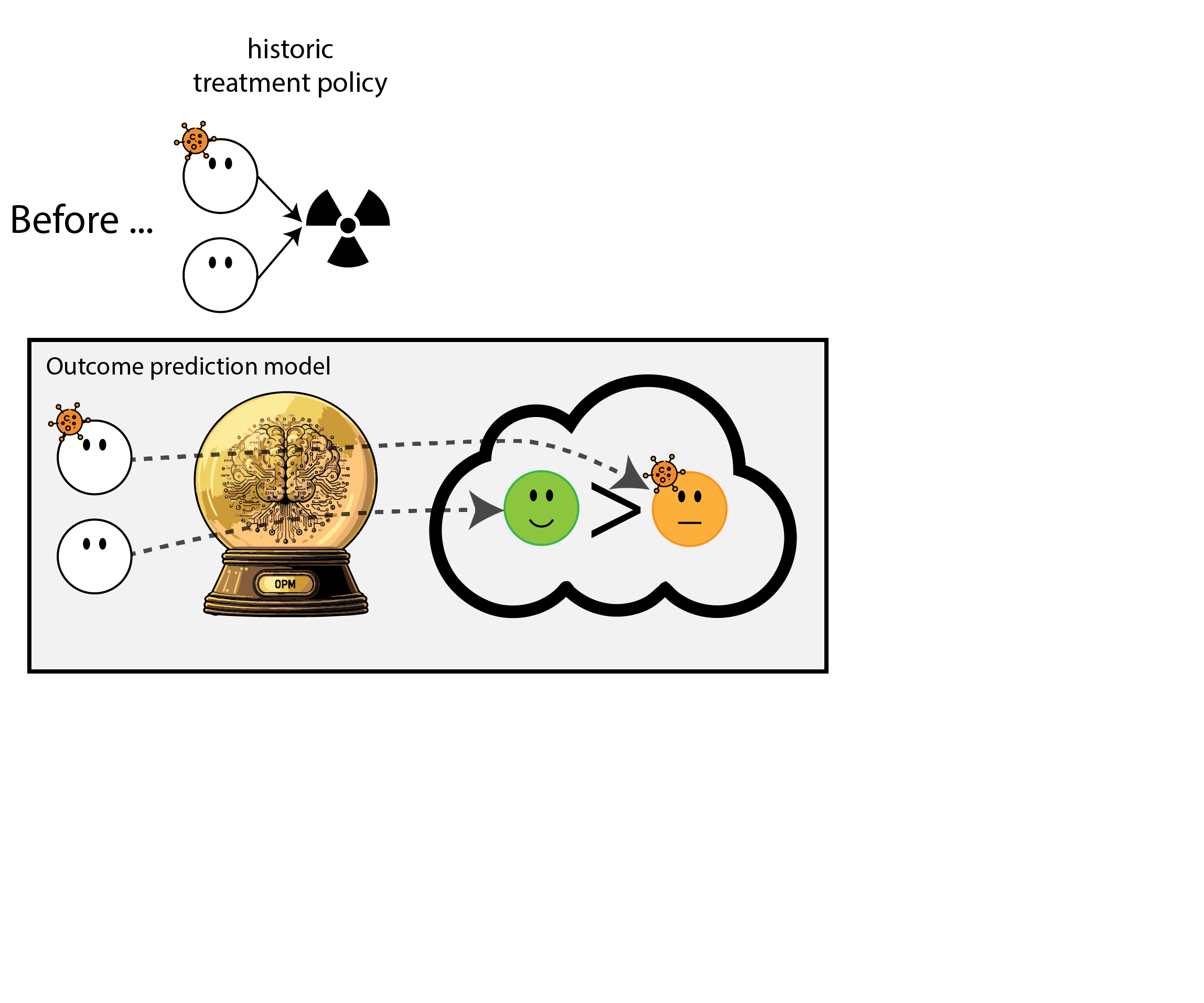
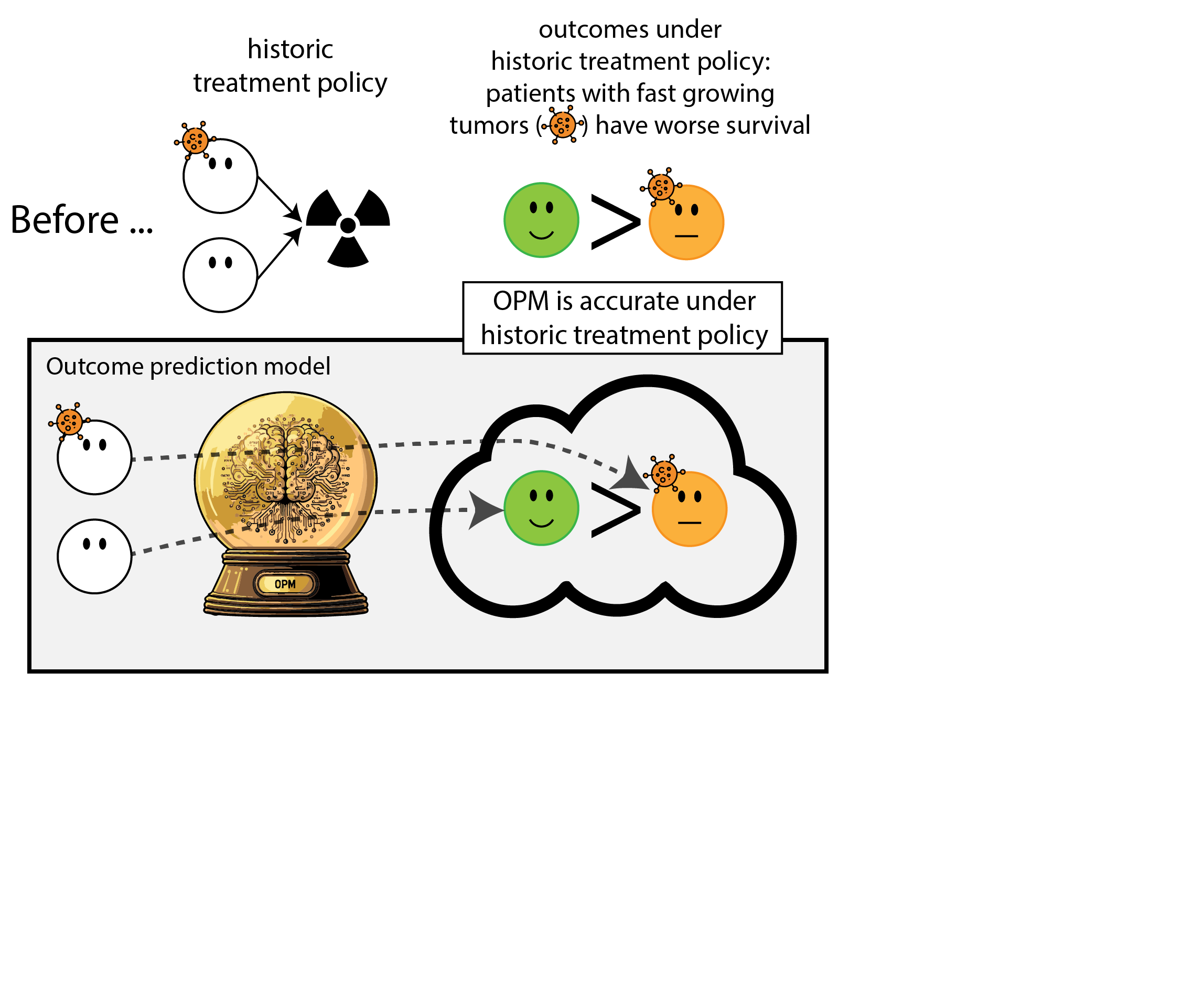
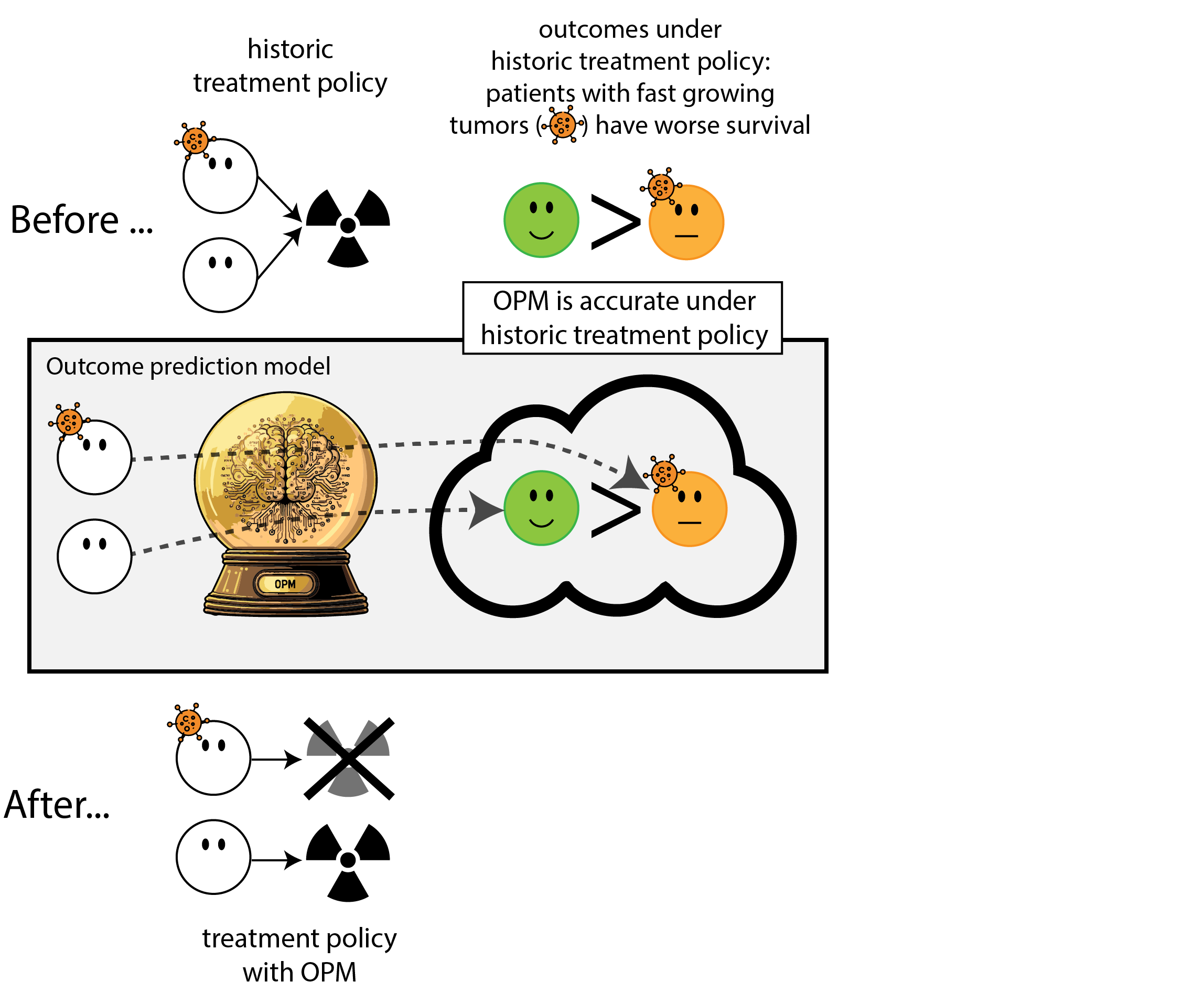
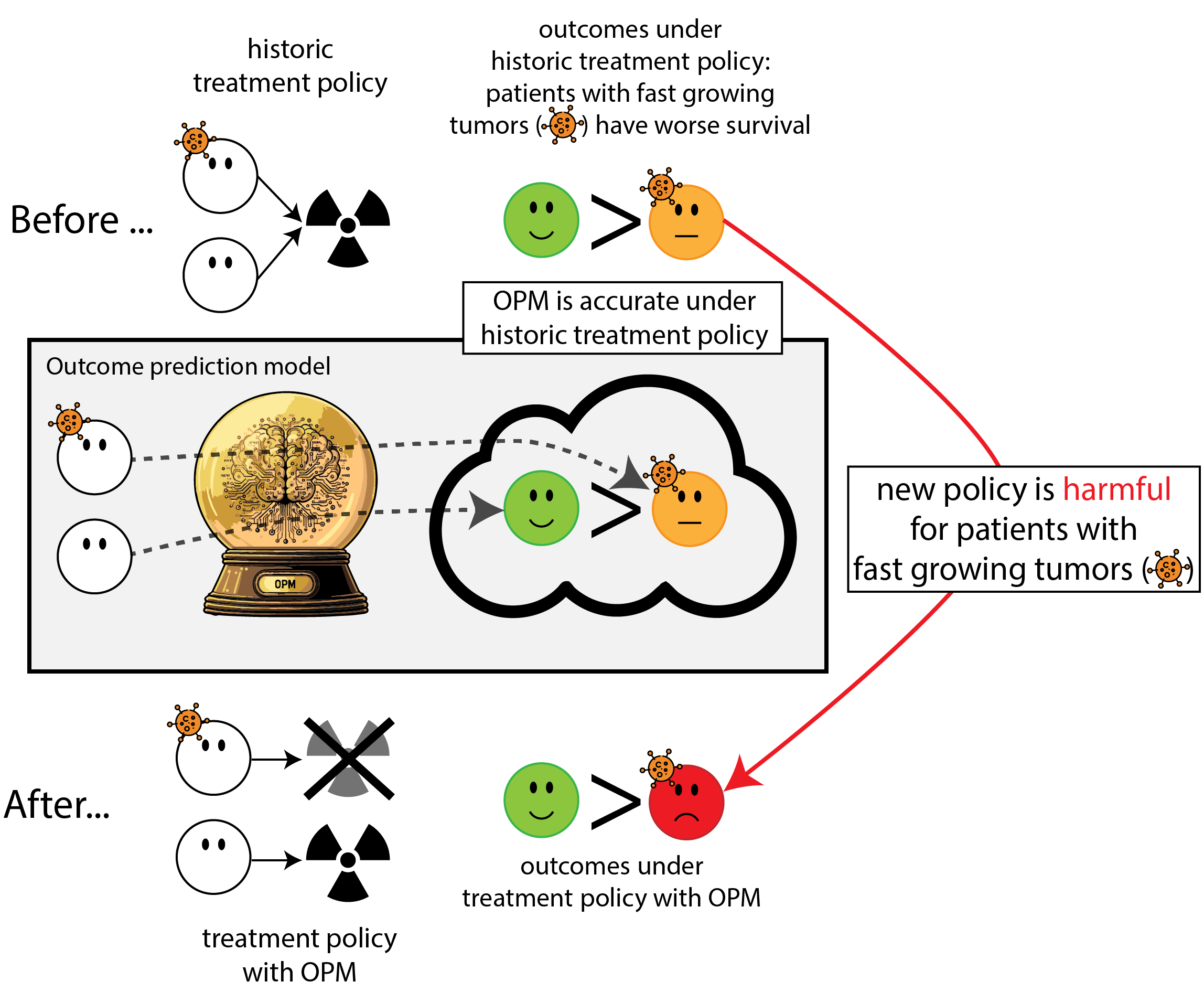
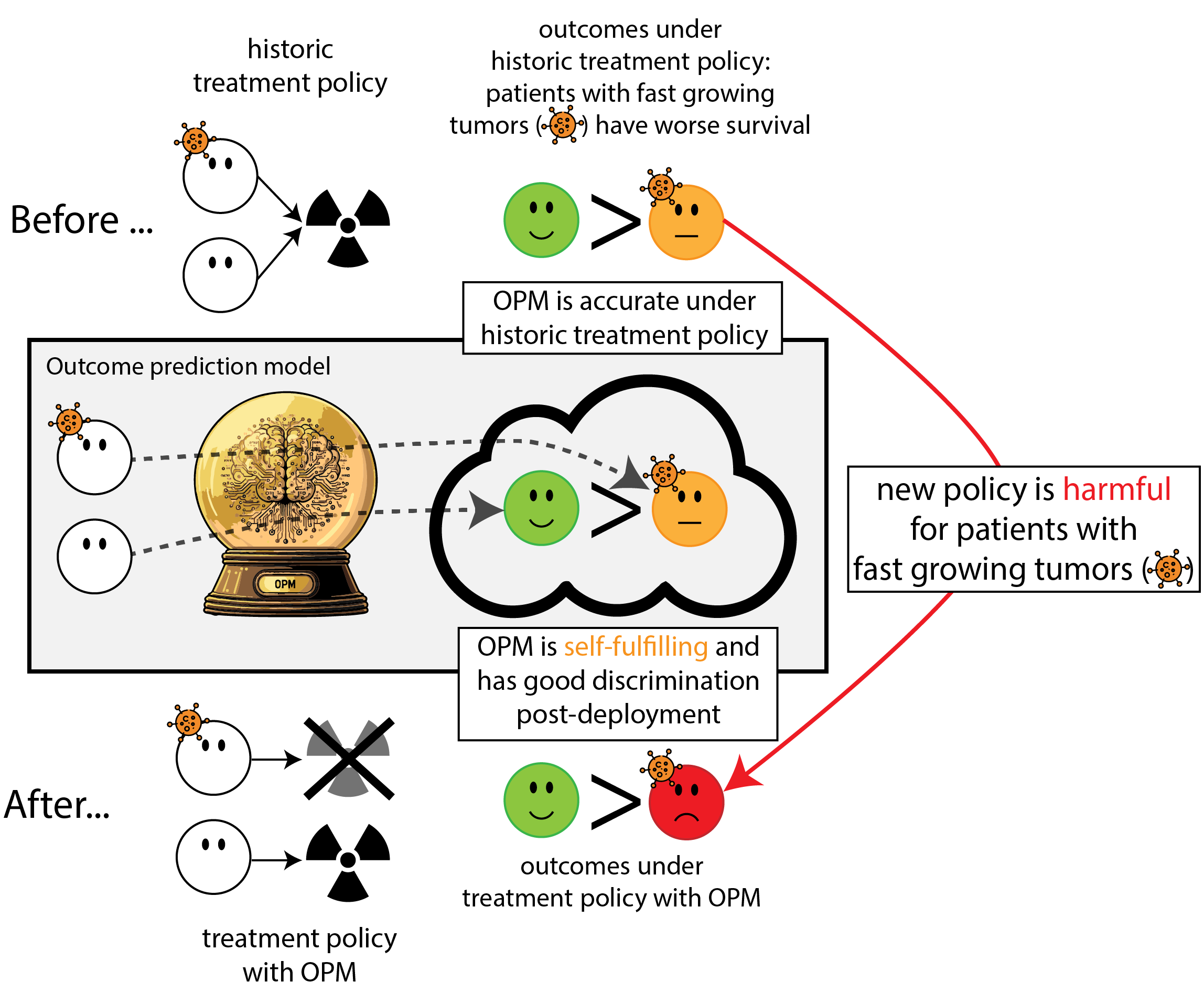
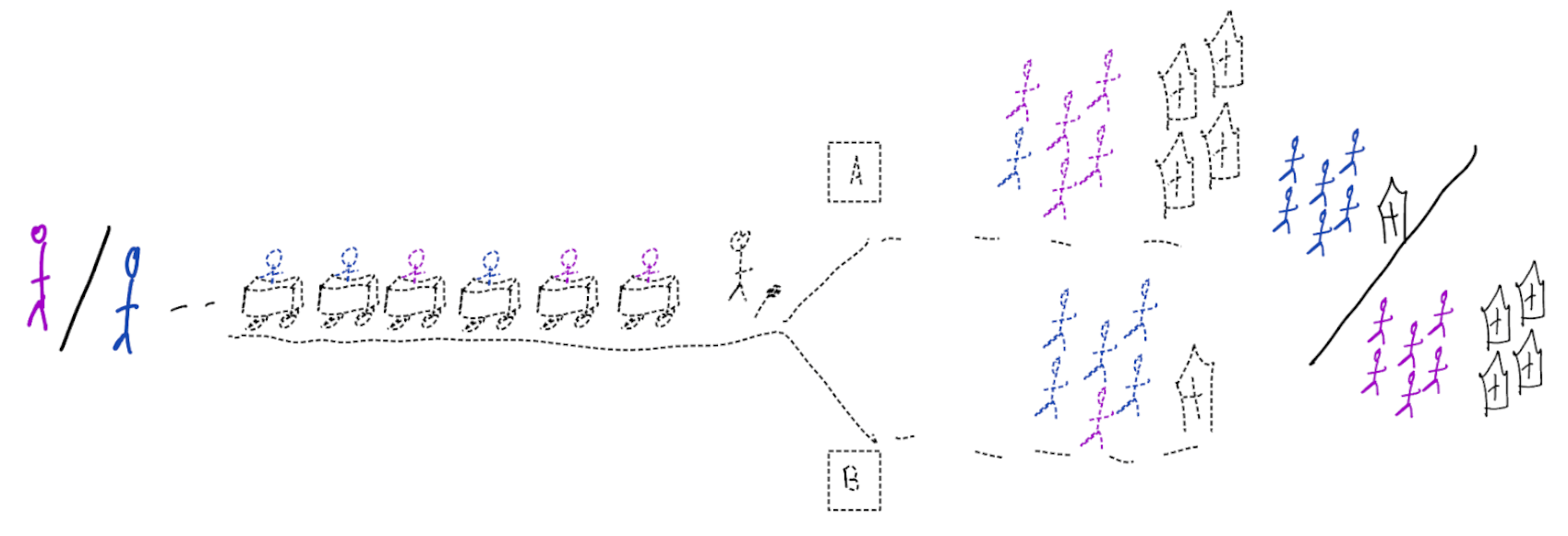
Building models for decision support without regards for the historic treatment policy is a bad idea
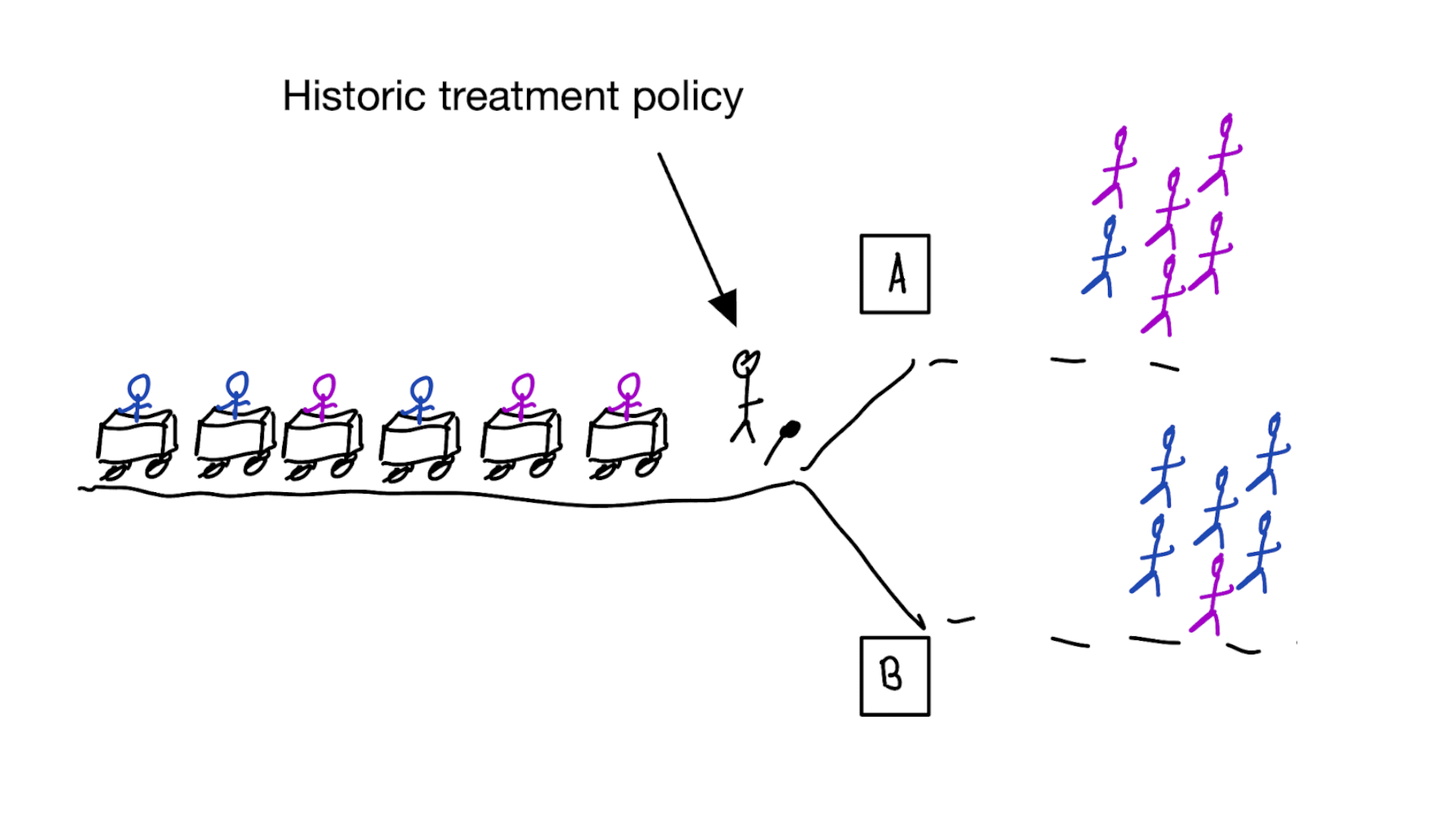
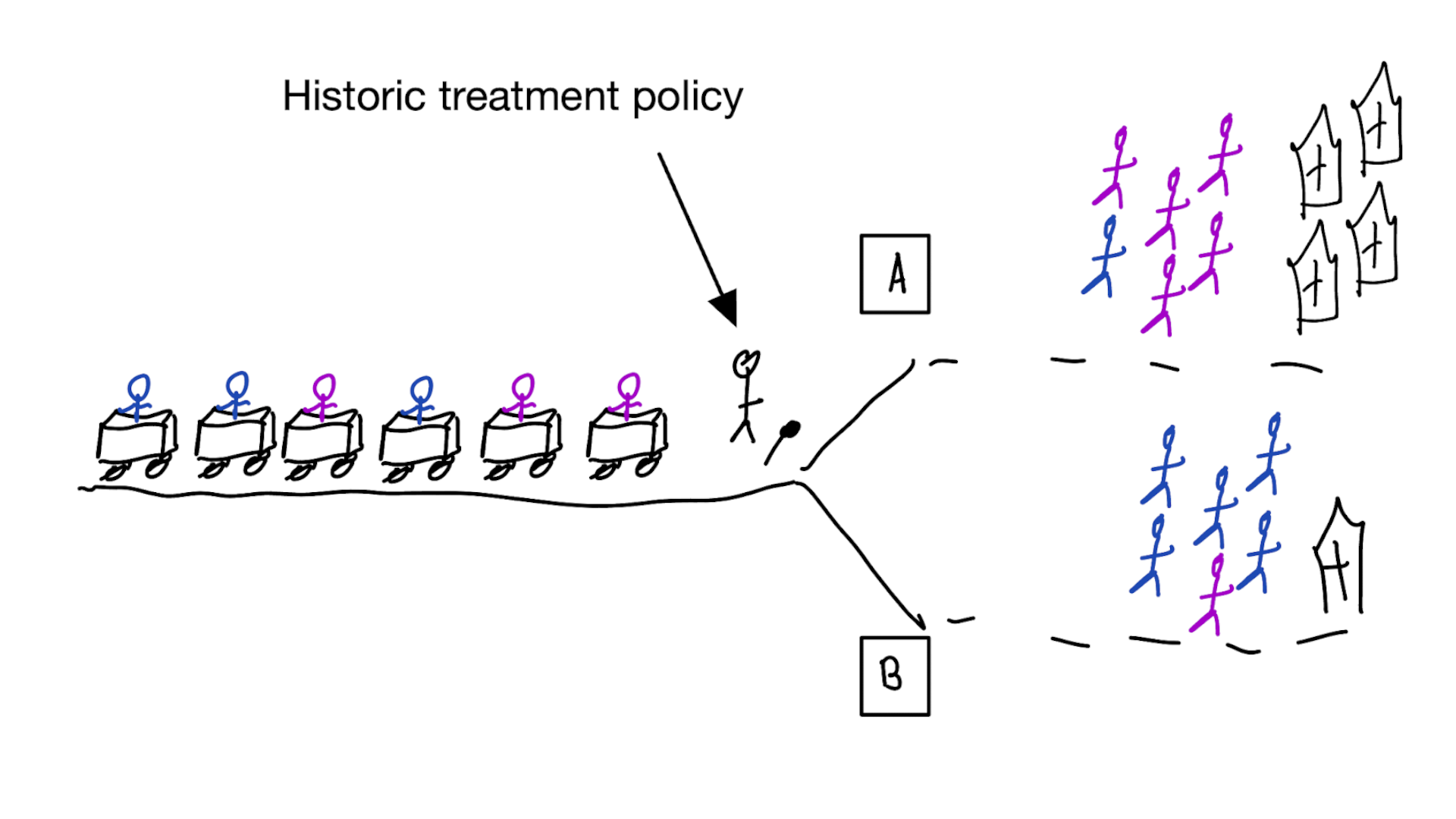
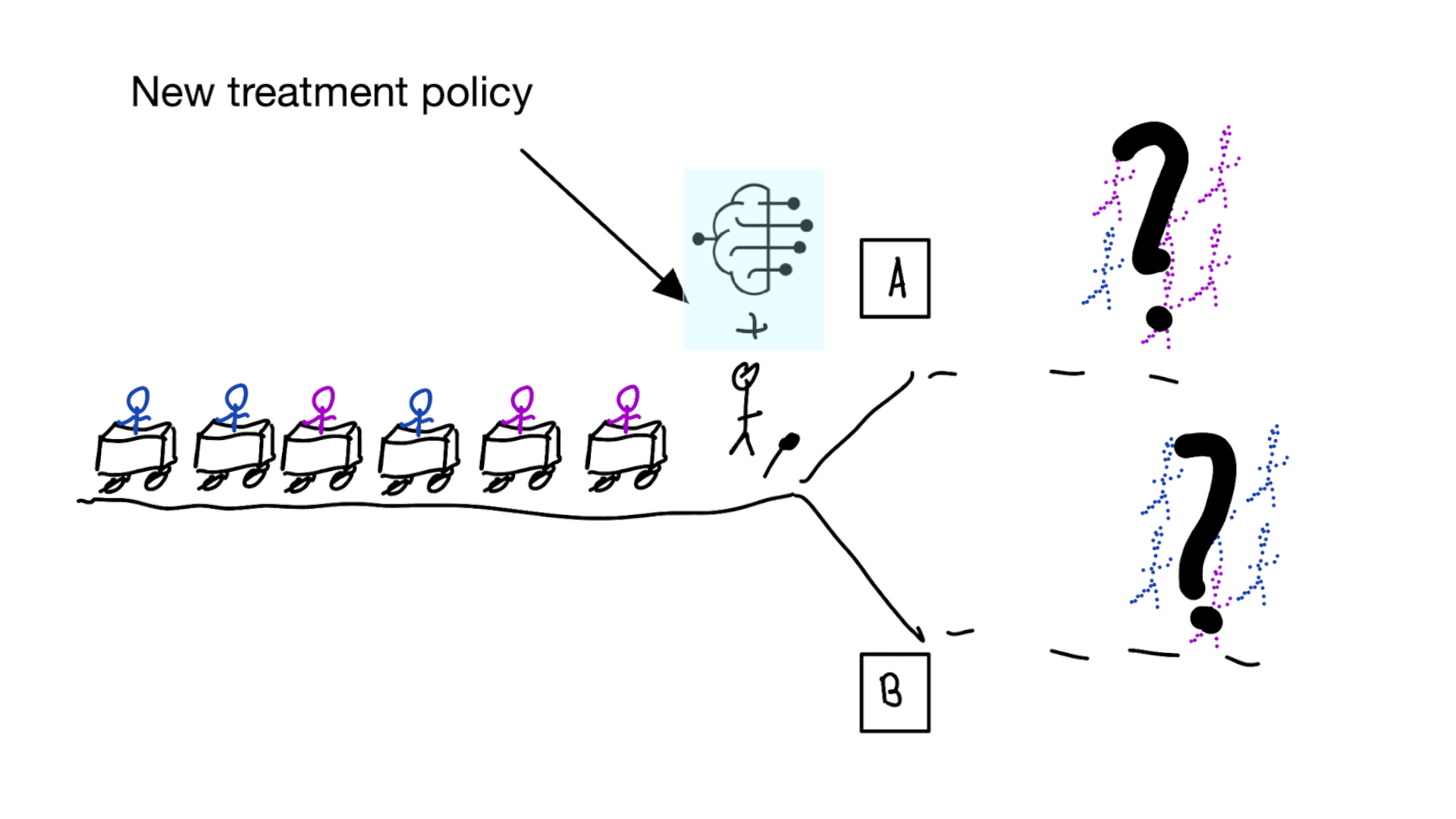
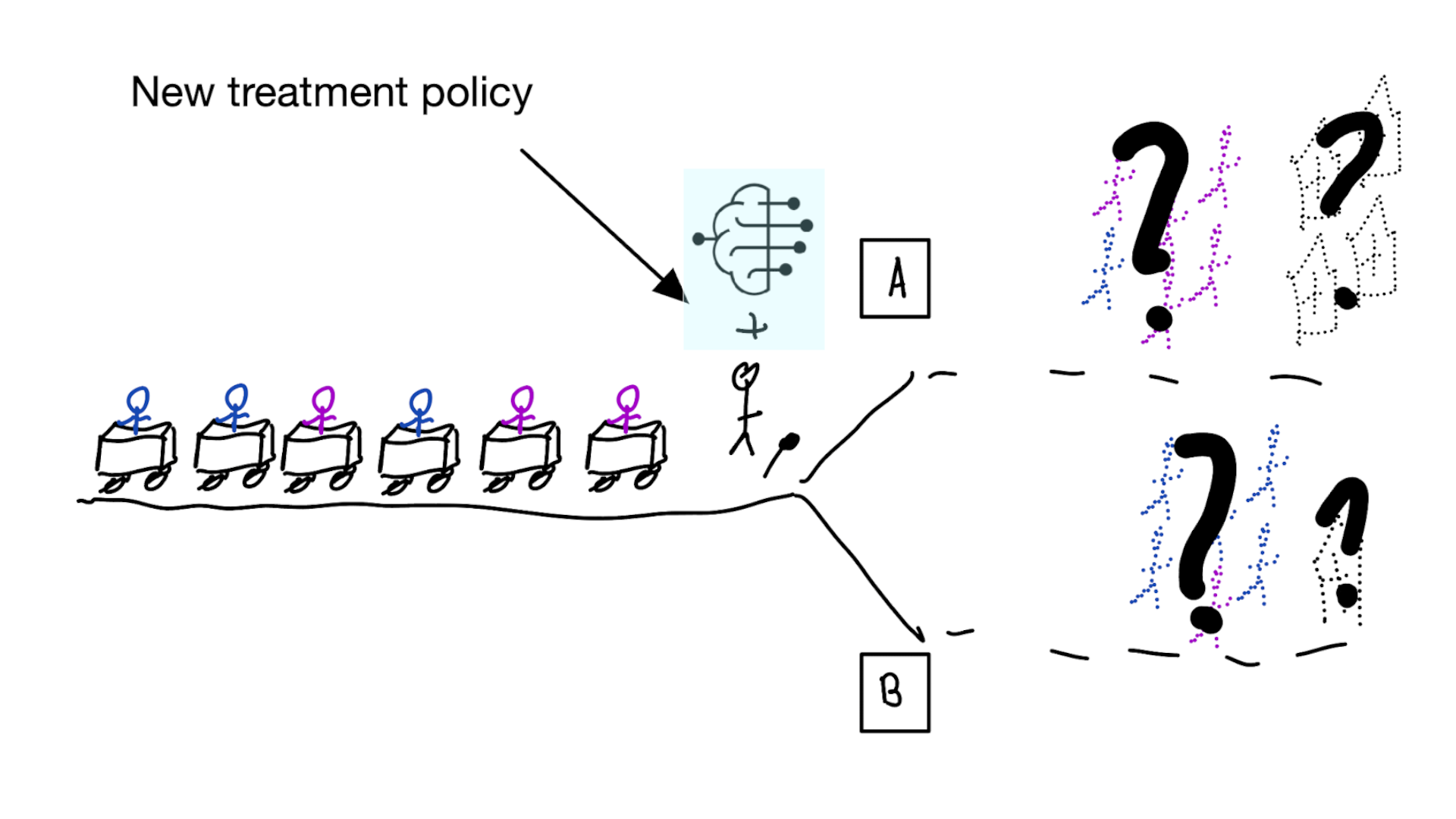
Treatment-naive prediction models
\[\begin{align} E[Y|X] \class{fragment}{= E[E_{t~\sim \pi_0(X)}[Y|X,t]]} \end{align}\]
Prediction modeling is very popular in medical research

Recommended validation practices and reporting guidelines do not protect against harm
because they do not evaluate the policy change


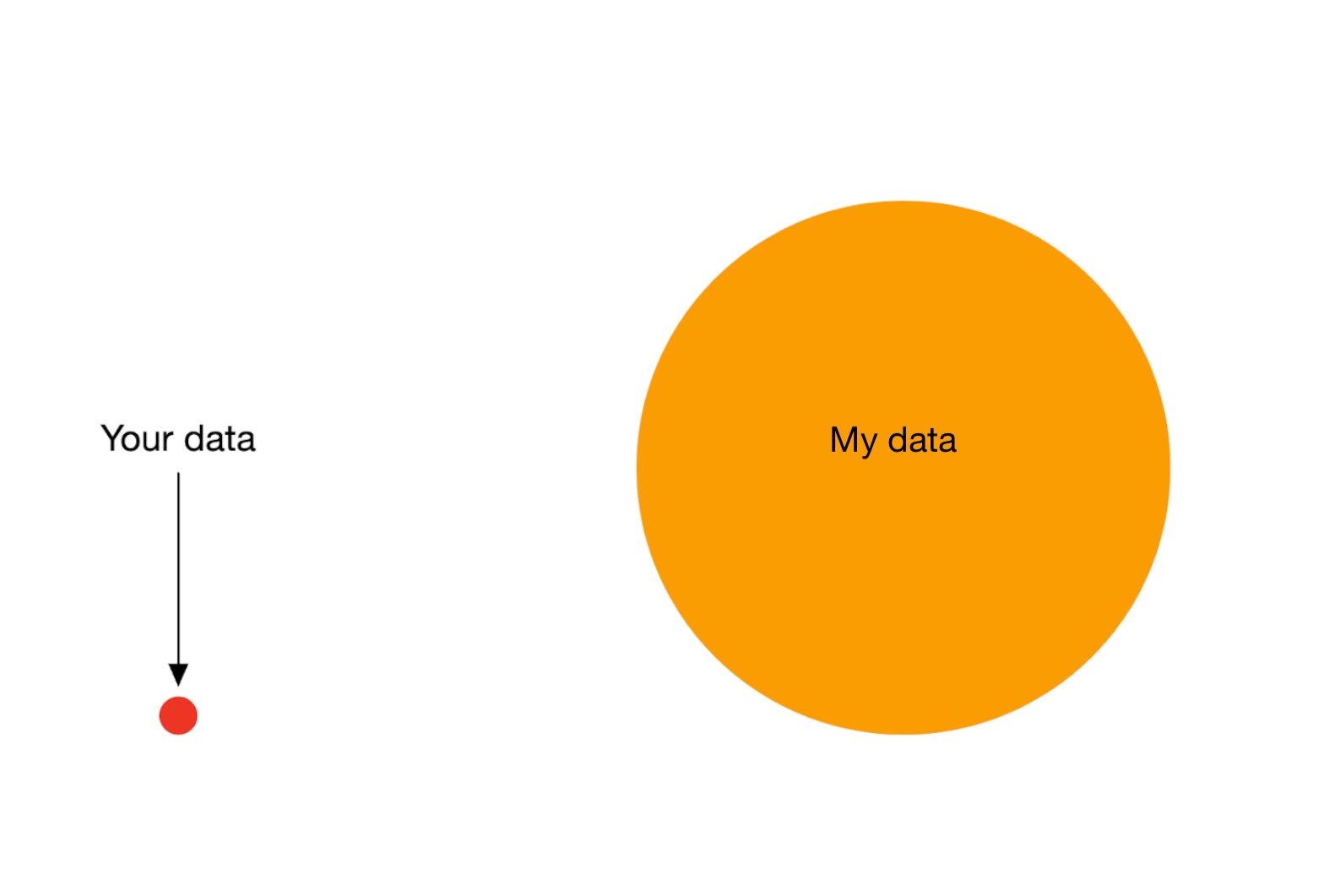
Bigger data does not protect against harmful prediction models
More flexible models do not protect against harmful prediction models

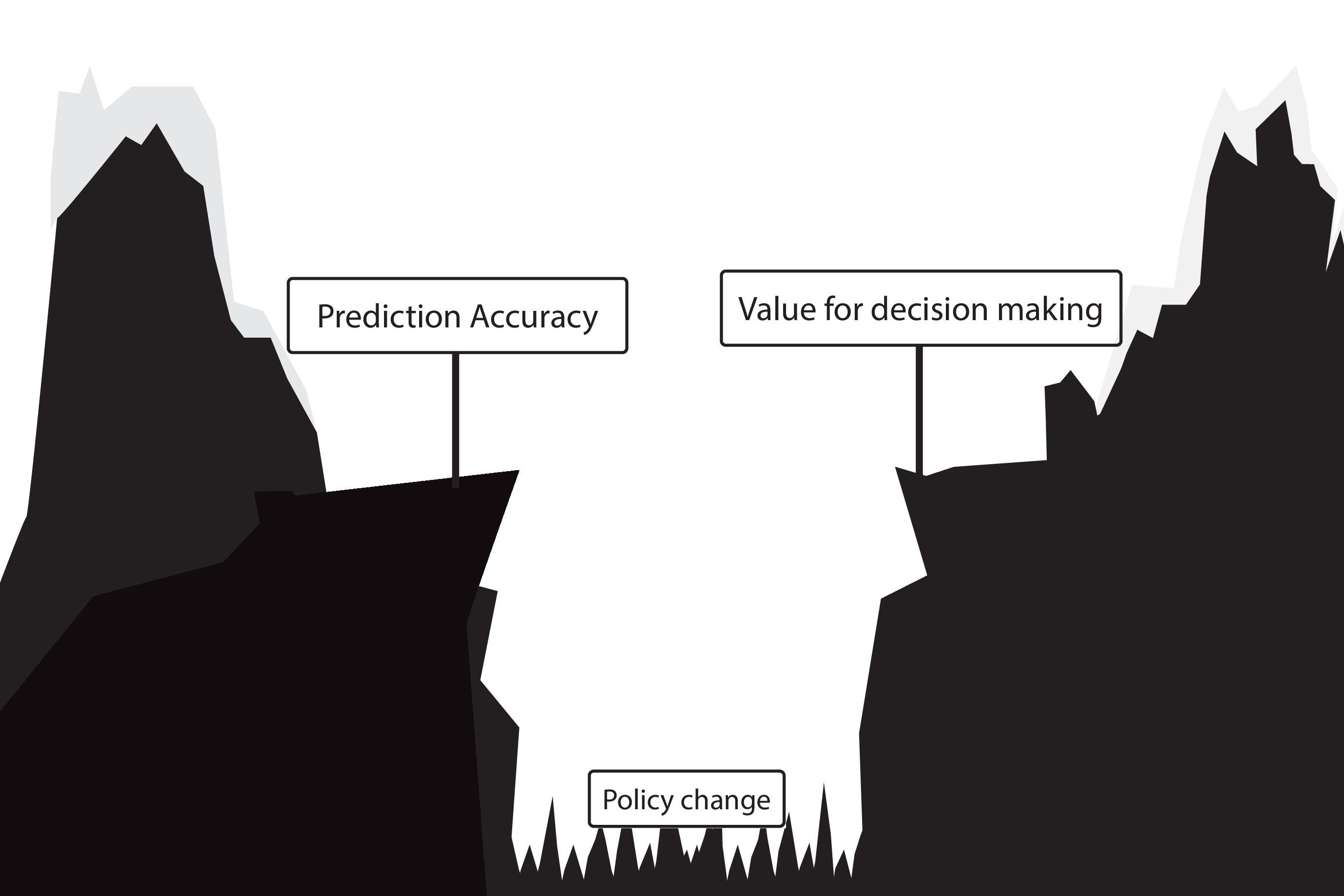
Deploying a model is an intervention that changes the way treatment decisions are made
What can we mean with predictions having a causal interpretation?
Let \(f: \mathbb{X} \to \mathbb{Y}\) be a prediction model for outcome \(Y\) using features \(X\)
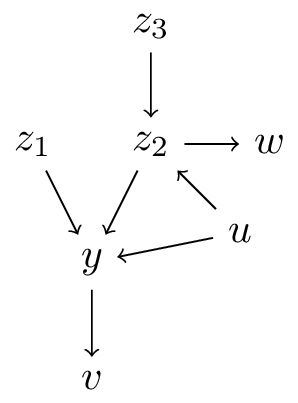
- \(X\) is an ancestor of \(Y\) (\(X=\{z_1,z_2,z_3\}\))
- \(X\) is a direct cause of \(Y\) (\(X=\{z_1,z_2\}\))
- \(f: \mathbb{X} \to \mathbb{Y}\) describes the causal effect of \(X\) on \(Y\) (\(X=\{z_1\}\)), i.e.:
\[f(x) = E[Y|\text{do}(X=x)]\]
- \(f: \mathbb{T} \times \mathbb{X} \to \mathbb{Y}\) describes the causal effect of \(T\) on \(Y\) conditional on \(X\) (\(T=\{z_1\},X=\{z_2,z_3,w\}\):
\[f(t,x) = E[Y|\text{do}(T=t),X=x]\]
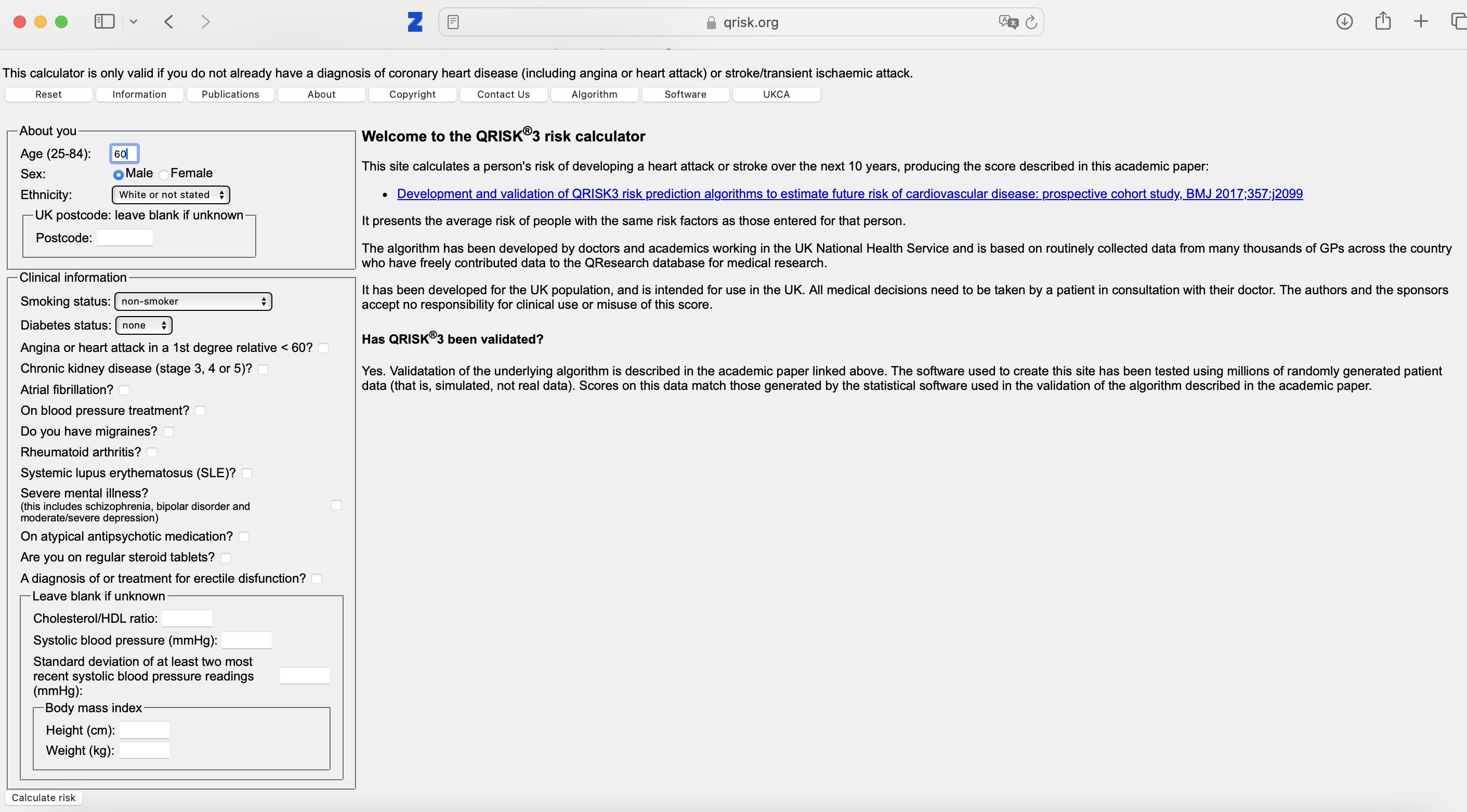
Example of table 2 fallacy when mis-using Qrisk
Qrisk3: a risk prediction model for cardiovascular events in the coming 10-years. Widely used in the United Kingdom for deciding which patients should get statins
interpretation 4. some covariates are causal
or: prediction-under-intervention
\[f(t,x) = E[Y|\text{do}(T=t),X=x]\]
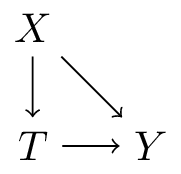
- interpretation: what is the expected value of \(Y\) if we were to assign treatment \(t\) by intervention, given that we know \(X=x\) in this patient
using treatment naive prediction models for decision support
prediction-under-intervention

